
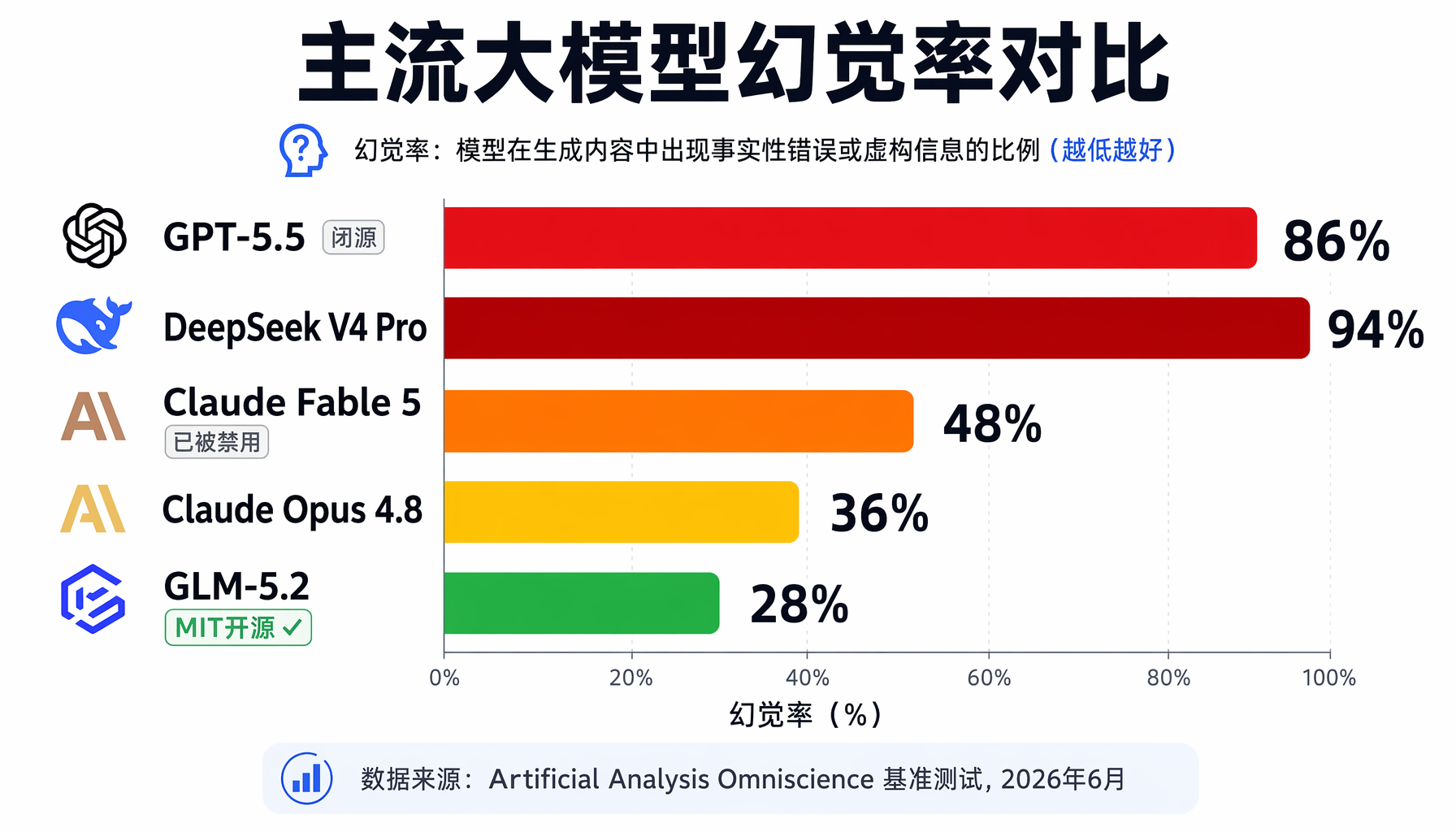
377分登顶Hacker News热榜:最大的模型DeepSeek V4 Pro幻觉率高达94%,而MIT开源的中等规模GLM-5.2仅28%。AI创业者选模型,不能再只看跑分了。
 ▲ 主流大模型幻觉率对比:GLM-5.2仅28%,DeepSeek V4 Pro高达94%
▲ 主流大模型幻觉率对比:GLM-5.2仅28%,DeepSeek V4 Pro高达94%
事件回顾
6月18日,一篇题为《Bigger models are not the way》的技术分析文章在Hacker News引发轩然大波,24小时内获得377 points和180条评论,成为当日AI领域最热讨论。
文章的核心发现令人震惊:根据Artificial Analysis的Omniscience基准测试,当前主流大模型的幻觉率呈现出反直觉的倒挂——模型越大,越喜欢"不懂装懂"。
具体数据:
- DeepSeek V4 Pro(1.6万亿参数):幻觉率94%,面对答不出的问题,只有6%的概率坦承"我不知道"
- GPT-5.5(保守估计1-2万亿参数):幻觉率86%,面对有陷阱的编程问题时,自信满满地输出错误方案
- Claude Fable 5(千亿级参数):幻觉率48%,发布仅3天就被美国政府以国家安全为由禁用
- Claude Opus 4.8:幻觉率36%,相对克制
- GLM-5.2(753B参数,40B活跃,MIT开源):幻觉率仅28%
也就是说,GPT-5.5的幻觉率是GLM-5.2的整整3倍。
一个令人深思的对比实验
文章作者设计了一个带有明确架构陷阱的Python编程任务:要求实现一个"不yield、不使用select/poll、单线程同时处理多个I/O"的自定义异步事件循环。
DeepSeek V4 Pro的表现:
- 推理时间:3分52秒(7700个推理token)
- 输出:结构精美的完整代码方案
- 结论:完全错误——它没有识别出这个任务在计算机科学上是不可能的
GLM-5.2的表现:
- 推理时间:12秒(799个推理token)
- 输出:明确指出任务的不可能性,解释了单线程不yield无法实现多路复用I/O
- 结论:完全正确
耗了近10倍的算力,产出了更差的结果。这不仅是效率问题,更是可信度危机。
为什么这对AI创业者至关重要
1. 你正在为"幻觉"买单
如果你在用GPT-5.5或DeepSeek V4 Pro开发面向客户的AI产品,每100次不确定的查询中,有86-94次模型会给你看起来自信但实际错误答案。
对AI创业者而言,这意味着:
- 客服机器人会自信地给客户错误信息
- 代码生成工具会输出能编译但逻辑错误的代码
- 数据分析Agent会产出看着专业但结论错误的分析报告
一个错误的客服回复可能导致客户流失,一段看似正确的错误代码可能在生产环境潜伏数周才被发现——修复成本远高于生成成本。
2. 开源模型正在缩小差距
GLM-5.2在Artificial Analysis智能指数上仅比GPT-5.5低4分,比Fable 5低9分——但它是MIT开源的,可以免费商用、本地部署、无需担心API限流或出口管制。
对于一人公司或小型创业团队,这意味着:
- 不必每月支付数千美元的API费用
- 不必担心模型被禁用(Fable 5的教训就在眼前)
- 可以在自有服务器上微调,完全掌控数据隐私
 ▲ 同一道Python陷阱题:DeepSeek V4 Pro耗时3分52秒输出错误答案,GLM-5.2仅12秒正确识别
▲ 同一道Python陷阱题:DeepSeek V4 Pro耗时3分52秒输出错误答案,GLM-5.2仅12秒正确识别
3. 选择标准需要更新
当前的模型选型存在严重的"跑分迷信"——只看排行榜分数,不看实际可靠性。文章提出的现代LLM三元悖论值得每位AI创业者深思:
原始能力(跑分)vs 不确定性校准(幻觉率)vs 计算效率(成本)——三者不可兼得,必须做取舍。
如果你在做一个需要高可靠性的AI产品(如金融分析、医疗咨询、法律文书),低幻觉率的重要性远高于跑分榜上的那几分之差。
我们能学到什么
1. 建立"幻觉预算"意识
在产品设计中明确不同场景的容错率:
- 创意生成(营销文案、头脑风暴)→ 幻觉率高可接受
- 信息检索(客服回答、知识查询)→ 必须要求低幻觉率
- 代码生成(生产环境)→ 低幻觉率+人工审核双保险
- 决策支持(数据分析、风险评估)→ 宁可不知,不可妄言
2. 多模型组合策略
不要押注单一模型。参考以下组合方案:
- 主力推理:GLM-5.2或Claude Opus 4.8(低幻觉率,适合核心业务)
- 创意生成:GPT-5.5(跑分高,适合需要发散思维的场景)
- 成本敏感:本地部署GLM-5.2(MIT开源,零API费用)
- 兜底验证:用低幻觉率模型审核高幻觉率模型的输出
3. 跟踪"诚实度"指标
选购或评估模型时,除了看常见的MMLU、HumanEval跑分外,主动追问:
- 这个模型在不确定性校准(calibration)上的表现如何?
- 遇到无法确定的问题时,它有多大概率承认"不知道"?
- 它的"幻觉率"在同类模型中处于什么水平?
行动建议
- 本周:如果你在用GPT-5.5或DeepSeek V4 Pro做面向客户的产品,跑一遍自己的"幻觉压力测试"——给模型一组你知道答案但模型训练数据中不可能有的问题,统计它给出错误自信回答的比例。
- 本月:尝试接入GLM-5.2作为备选方案。MIT开源意味着零许可成本,753B参数在消费级硬件上也能推理(40B活跃参数)。对比一下在你的实际业务场景中,幻觉率和成本差异有多大。
- 持续关注:Artificial Analysis的Omniscience基准测试正在成为衡量模型"诚实度"的行业标准。把它加入你的模型选型参考清单,而不仅仅是看跑分排行榜。
#AI创业 #大模型选型 #幻觉率 #GLM-5.2 #一人公司
本文由AI辅助创作,经人工审核编辑发布
更多一人公司案例与工具,微信搜索「AI创业内参」关注我们