
RTK凭借60K+ GitHub Star和"节省60-90% token"的口号席卷AI开发者社区,但一篇名为《Token压缩幻觉》的深度质疑文章在HN上炸出110条激烈讨论。核心指控:你省的那点token,可能正在让你的Agent静默失败。
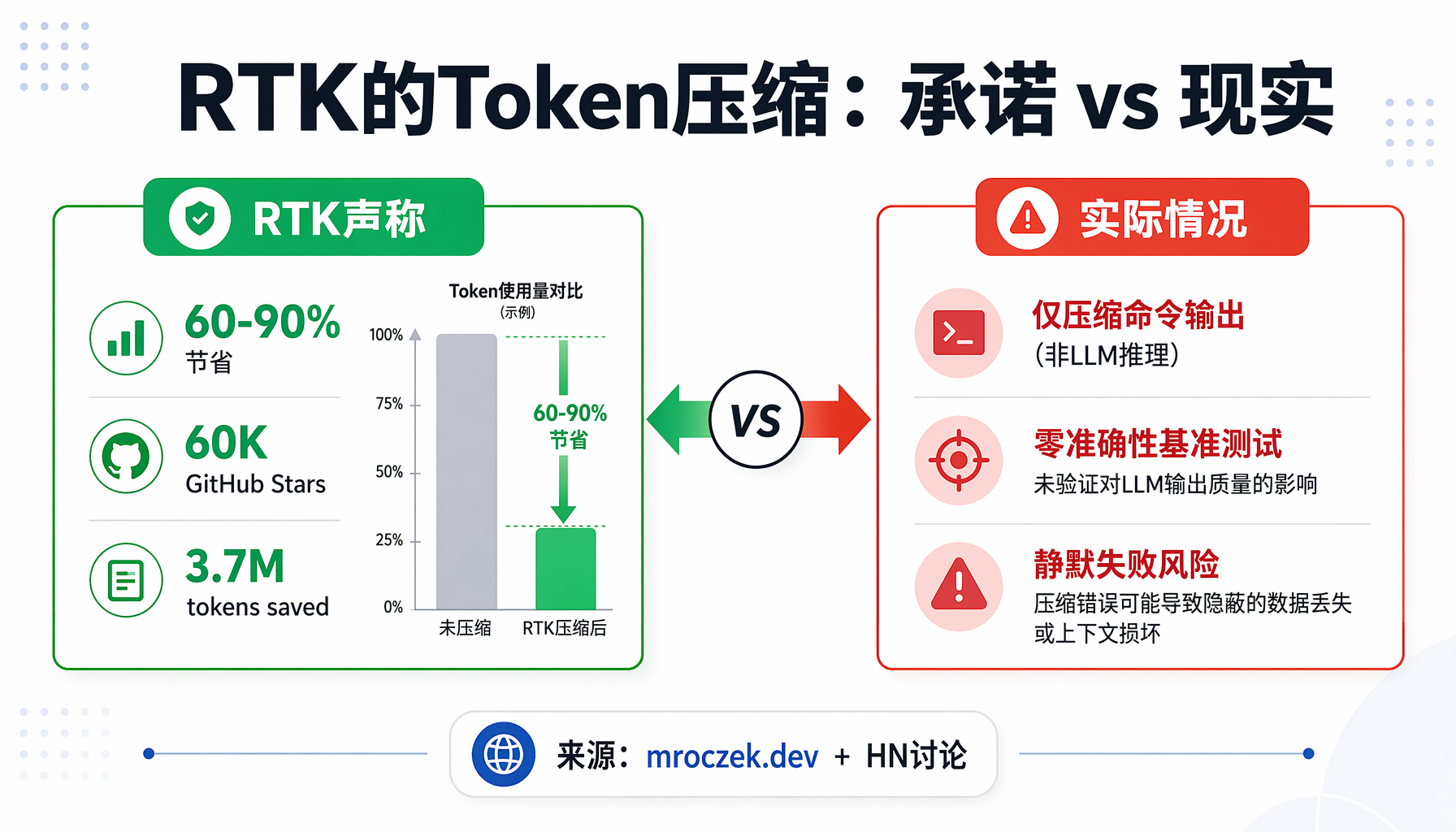
 ▲ ▲ RTK Token压缩:承诺vs现实 — 60-90%节省的宣传背后,仅压缩命令输出而非LLM推理
▲ ▲ RTK Token压缩:承诺vs现实 — 60-90%节省的宣传背后,仅压缩命令输出而非LLM推理
事件回顾
6月18日,资深工程师 Przemek Mroczek 在个人博客发表了一篇引爆HN的文章:《The Token Compression Illusion: Why I'm Skeptical of RTK》。文章直指当前AI Agent开发社区的宠儿——RTK(一个自动压缩终端命令输出的工具)——存在"结构性缺陷",并称其为"虚荣指标驱动的危险工具"。
RTK 是什么?它是一个命令行工具,能自动检测并压缩各种CLI工具的输出。比如 git diff 返回的50行变动,RTK 可能压缩成3行摘要。对于每天调用成千上万次命令的 AI Agent(如 Claude Code、Cursor、Hermes Agent),这听起来是巨大的成本节约——API 按 token 计费,少传一个字就省一分钱。
但 Mroczek 在文章中抛出了5个炸弹级质疑:
1. 「节省90%」是数字游戏:RTK 声称的"60-90%节省"指的是被压缩的命令输出在原始输出中的占比,而不是你的实际 API 账单。"它完全不碰真正烧钱的东西——长文件读取、仓库上下文、系统提示词、模型内部推理 token。rtk gain 这个命令设计出来,就是给人截图发社交媒体用的。"
2. 静默失败陷阱:这是最致命的指控。"RTK 压缩输出后,Agent 根本不知道原文被改过。如果 RTK 为了省几个 token 而丢掉了关键的错误行或编译上下文,你和 LLM 都在黑暗中操作。"文章指出 GitHub 上已有 issue 报告输出静默丢失的问题。
3. 零准确性基准测试:RTK 的营销页面满是 token 节省图表,但"完全没有公布唯一真正重要的指标:任务成功率。省了80%的 prompt 但 Agent 因此幻觉、构建失败、原地打转——这是净亏损。"文章呼吁进行 SWE-bench 级别的准确性评估。
4. 它是功能,不是产品:"主流 CLI 工具随时可以加一个 --compact 或 --json-stream 参数。一旦 git、cargo、npm 原生支持 LLM 友好输出,RTK 的存在意义就消失了。"
5. 脆弱的解析层:"RTK 依赖精确解析人类可读的终端输出格式。某天 git 改了几个空格、npm 调整了错误布局——RTK 的正则全炸。而且它不会报错,只是静默地喂给 Agent 残缺文本。"
HN 社区的撕裂
这篇文章在 HN 上获得 103 points、110 条评论,评论区罕见地出现了势均力敌的分裂:
支持质疑的声音:
- "我亲眼见过 Agent 被 RTK 输出搞糊涂,然后原地打转或用荒谬的 workaround" —
RVuRnvbM2e - "从 caveman mode 到 RTK 到语义搜索,开发者已经变成了念咒语的魔法师而不是工程师" —
cityofdelusion - "我测过,在一个 300K token 的 session 里,RTK 实际只省了约 3K token" —
Otterly99 - "最核心的问题是没有办法衡量 AI 是否真的'工作得更好'" —
trjordan
为 RTK 辩护的声音:
- "我在 Mac 上实测,省了 51K 输入 token、23K 输出 token,每个命令平均快 3 秒" —
giancarlostoro - "工具输出是我 token 消耗的大头。省了 370 万 token 就是省了 370 万——省到就是赚到" —
compuficial - "文章没有提供任何实际数据来支撑反对意见" —
Bnjoroge - "可以用
RTK_DISABLE=1做 bypass,需要原文时随时恢复" —ilia-a
作者本人也现身评论区坦诚写作动机:"RTK 的 AI 味儿让我这个老派工程师看着很不舒服,60K star、零准确性指标、管理层用它来压成本——人们正在用 RTK 包裹每一个命令,试图处理所有主流 CLI,然后自己决定删掉哪些输出。"
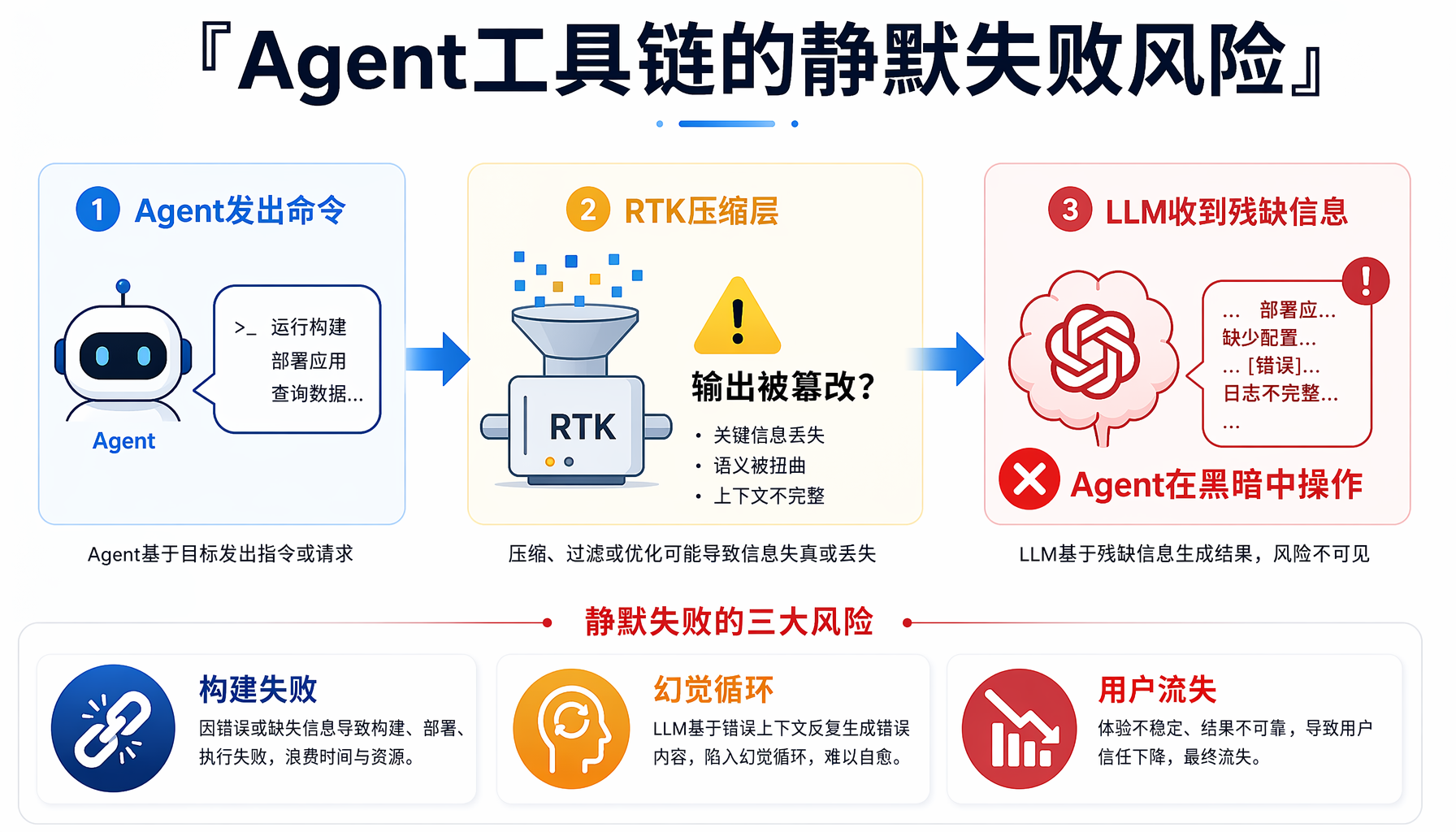
 ▲ ▲ Agent工具链的静默失败风险 — RTK压缩层可能篡改输出,让Agent在黑暗中操作
▲ ▲ Agent工具链的静默失败风险 — RTK压缩层可能篡改输出,让Agent在黑暗中操作
这对 AI 创业者的实际影响
不管你站哪边,这场争论揭示了 AI Agent 工具链的一个核心矛盾:成本优化与可靠性之间的张力。
对于正在构建 AI Agent 产品的一人公司或小团队来说,这不仅仅是看热闹——它直接关系到你的底线:
场景一:你用 Claude Code/Cursor 写代码。 如果 RTK 删掉了关键的 lint 错误或类型提示,Agent 可能产出有 bug 的代码,而你要花双倍时间 debug。省钱省出了 bug,得不偿失。
场景二:你搭建了自动化 AI 内容流水线。 如果 Agent 依赖精确的 Git log 或构建输出来判断内容变更,压缩层引入的静默错误可能导致"看起来发布成功但实际内容残缺"——这可是微信平台能检测到的。
场景三:你在做 AI Agent SaaS 产品。 你的用户不会关心你用了什么 token 压缩工具——他们只关心 Agent 给的结果对不对。如果因为输出被篡改导致用户任务失败,流失率和退款成本远超省下的 API 费用。
行动建议
- 先别急着盲目上车:RTK 对某些场景(如大量 git/log 输出)可能有价值,但务必在自己的实际工作流中测量端到端任务成功率,而不是只看
rtk gain的数字。 - 写个简单的 A/B 测试脚本:同样的任务跑两遍——一次用 RTK,一次不用。对比最终输出的正确性。这才是你的 ROI。
- 关注原生解决方案:越来越多的 CLI 工具在添加 LLM 友好输出。OpenAI 和 Anthropic 的 Agent SDK 也在内置上下文管理。长期看,外部压缩层可能被原生能力取代。
- 如果必须用,加安全网:设置
RTK_DISABLE=1环境变量作为 bypass 开关;在关键步骤(部署、数据写入)前禁用压缩;定期对比原始输出和压缩输出的语义一致性。 - 写进你的系统提示词:如果用了 RTK,在系统提示词中告知 Agent "命令输出可能被压缩过,如有疑问请用原始命令重新执行"——这能显著降低静默失败的概率。
本文由AI辅助创作,经人工审核编辑发布
更多一人公司案例与工具 → 微信公众号搜索「AI创业内参」→ 菜单栏「官方网站」即可访问 xopcx.com