没有记忆的 AI Agent 就像金鱼——每次对话都从零开始。本教程带你从零搭建 Agent 记忆系统,覆盖知识图谱、向量存储、以及昨天刚合并的 MCP Memory Resource 新特性。
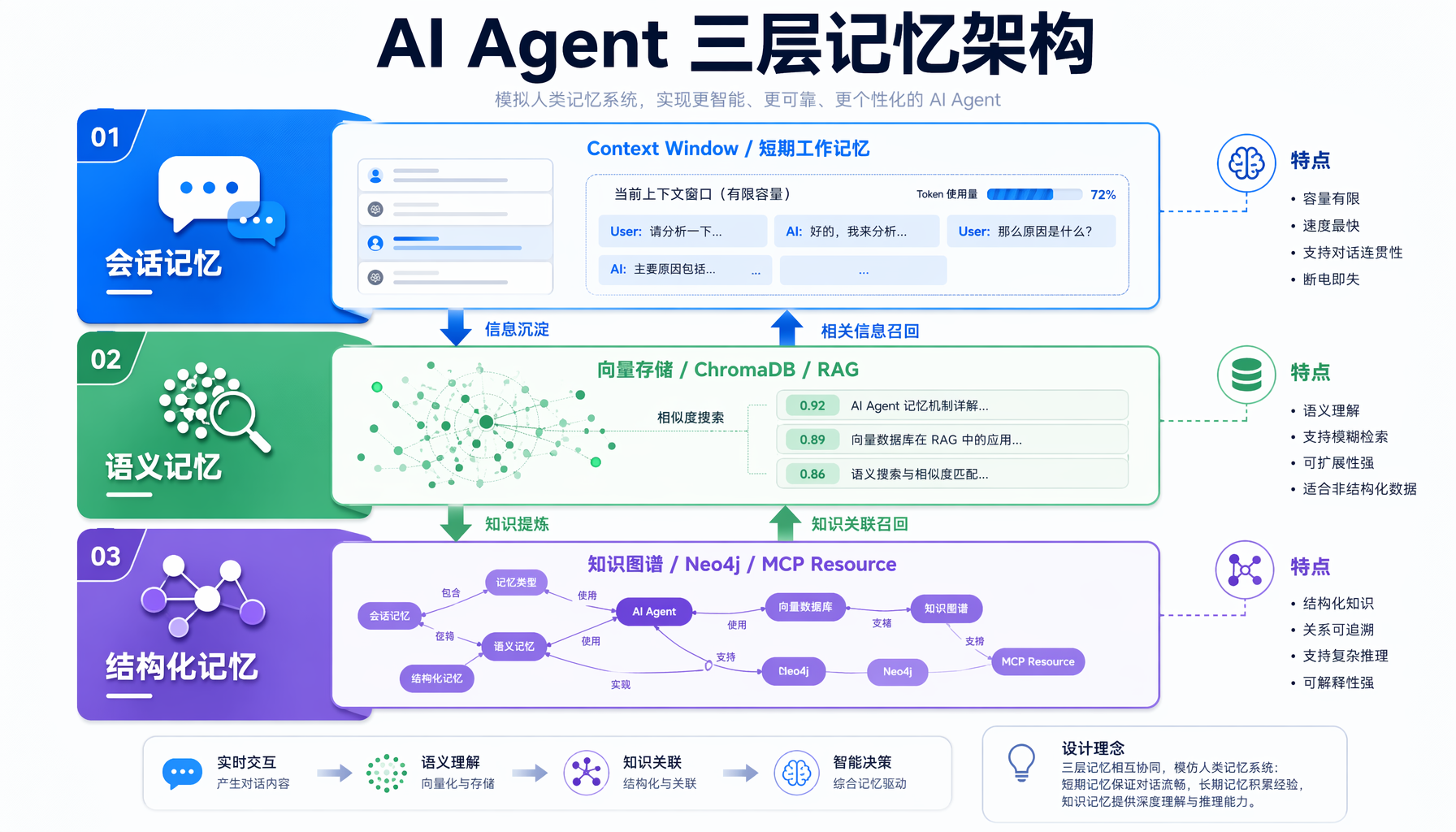
 ▲ AI Agent记忆系统三层架构:会话记忆、语义记忆、结构化记忆
▲ AI Agent记忆系统三层架构:会话记忆、语义记忆、结构化记忆
为什么你的 Agent 需要记忆系统
如果你用 AI Agent 做过任何超过 10 分钟的实际工作,你一定遇到过这个场景:
你花了 20 分钟让 Agent 理解了你的项目结构、技术栈、业务逻辑,然后——会话超时了。下一次对话,Agent 一脸茫然地问你:"请问这个项目用的什么技术栈?"
这不是 Agent 不够聪明,而是它没有记忆。
对于 AI 创业者来说,这个问题更加致命。当你用 Agent 做客户支持、内容生产、数据分析和代码开发时,Agent 的"健忘症"会导致:
- 重复解释业务逻辑,浪费时间
- 每次对话产出质量不一致
- 无法积累领域知识,Agent 永远是"新人"
- 多 Agent 协作时信息孤岛
好消息是:2026 年的 AI Agent 生态已经有了成熟的记忆系统方案。本教程会带你从概念到代码,完整搭建一套 Agent 记忆系统。
记忆系统的三层架构
Agent 记忆系统不是单一技术,而是三层互补的架构:
┌─────────────────────────────────────────┐
│ 第一层:会话记忆 │
│ 对话上下文、短期工作记忆 │
│ (Hermes 内置 context window) │
├─────────────────────────────────────────┤
│ 第二层:语义记忆 │
│ 向量存储、语义搜索、RAG │
│ (ChromaDB / Qdrant / Pinecone) │
├─────────────────────────────────────────┤
│ 第三层:结构化记忆 │
│ 知识图谱、关系网络、实体链接 │
│ (MCP Memory Server / Neo4j) │
└─────────────────────────────────────────┘
第一层(会话记忆) 是 Agent 框架自带的能力——对话历史在 context window 里自动管理。但它的局限很明显:窗口有限、会话间不持久。
第二层(语义记忆) 用向量数据库存储"知识片段",Agent 可以按语义相似度检索相关内容。这是目前最流行的方案,RAG(检索增强生成)就是基于这一层。
第三层(结构化记忆) 是本文的重点——用知识图谱存储实体之间的关系,让 Agent 不仅能"回忆"信息,还能"推理"关系。
知识图谱:让 Agent 学会"推理"
什么是知识图谱
传统向量存储擅长"这段内容和那段内容语义相似",但它不理解"张三和李四是什么关系"。知识图谱填补了这个空白:
向量存储:
"张三是CTO" → 嵌入向量 [0.1, 0.3, -0.2, ...]
"李四是工程师" → 嵌入向量 [0.2, 0.1, -0.1, ...]
提问"谁向张三汇报?" → 找不到精确答案
知识图谱:
(张三) --[担任]--> (CTO)
(李四) --[担任]--> (工程师)
(李四) --[汇报给]--> (张三)
提问"谁向张三汇报?" → 李四 ✓
对于 AI 创业者,知识图谱在以下场景有奇效:
- 客户关系管理:客户→项目→合同→付款 的关系链
- 内容知识库:作者→文章→主题→引用 的关联网络
- 代码库理解:模块→函数→依赖→API 的调用关系
- 竞品分析:公司→产品→技术栈→融资轮次 的市场地图
MCP Memory Server 的知识图谱能力
MCP(Model Context Protocol)官方仓库的 Memory Server 是目前 Agent 知识图谱的最佳实践。就在昨天(2026年6月17日),MCP 仓库合并了一个重要 PR:
feat(memory): expose knowledge graph as MCP Resource (#3323)
这个 PR 将知识图谱注册为 MCP Resource(memory://knowledge-graph),让 Agent 可以通过 MCP Resources 协议直接读取图谱。这意味着:
- Agent 不需要写 Cypher 查询,通过标准 MCP 协议就能读取知识图谱
- 知识图谱可以和其他 MCP 工具(文件系统、数据库、API)无缝协作
- 多个 Agent 可以共享同一个知识图谱
动手实践:搭建你的第一个知识图谱
#### 步骤 1:启动 MCP Memory Server
首先安装并启动 MCP Memory Server:
# 克隆 MCP servers 仓库
git clone https://github.com/modelcontextprotocol/servers.git
cd servers/src/memory
# 安装依赖
npm install
# 启动 Memory Server
npx tsx index.ts --knowledge-graph
启动后,Server 会暴露以下工具给 Agent:
| 工具名 | 功能 | 示例 |
|---|
create_entities | 创建实体节点 | 创建"张三"、"CTO" |
create_relations | 创建实体间关系 | 张三-[担任]->CTO |
add_observations | 给实体添加观察记录 | 张三在2024年加入公司 |
delete_entities | 删除实体 | 删除过时信息 |
delete_observations | 删除观察记录 | 清理错误信息 |
delete_relations | 删除关系 | 更新组织架构 |
read_graph | 读取完整图谱 | 查看所有实体和关系 |
search_nodes | 按名称搜索实体 | 查找"张三"相关节点 |
open_nodes | 按名称打开实体详情 | 查看"李四"的完整信息 |
#### 步骤 2:用 Agent 填充知识图谱
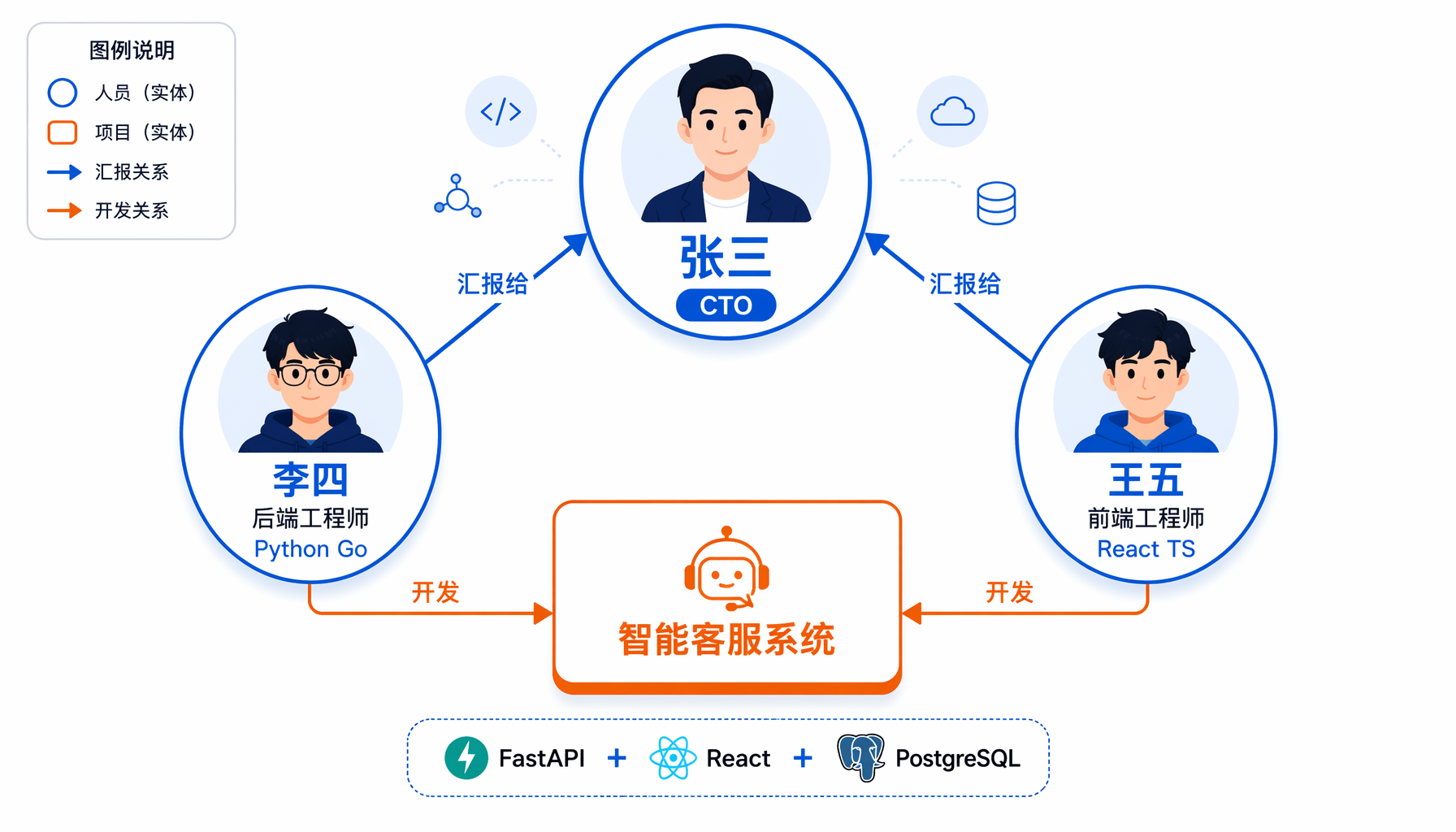
将 Memory Server 连接到 Hermes Agent 后,你可以用自然语言建图:
你:帮我记住我们团队的关键信息。
CTO 张三,2024年3月加入,负责技术架构
后端工程师李四,向张三汇报,专长 Python 和 Go
前端工程师王五,向张三汇报,专长 React 和 TypeScript
我们产品叫"智能客服系统",技术栈是 Python + React + PostgreSQL
Agent:[调用 create_entities 创建张三、李四、王五、智能客服系统]
[调用 create_relations 建立汇报关系和技术栈关系]
[调用 add_observations 记录入职时间和专长]
几轮对话后,你的知识图谱会变成这样:
┌──────────┐
│ 张三 │ ← CTO
│ 2024.3 │
└────┬─────┘
│ [汇报给]
┌────────┼────────┐
▼ │ ▼
┌─────────┐ │ ┌─────────┐
│ 李四 │ │ │ 王五 │
│ Python │ │ │ React │
│ Go │ │ │ TS │
└────┬────┘ │ └────┬────┘
│ [开发]│ │ [开发]
▼ │ ▼
┌─────────────────────────┐
│ 智能客服系统 │
│ Python+React+PostgreSQL │
└─────────────────────────┘
#### 步骤 3:用知识图谱辅助 Agent 决策
有了知识图谱后,Agent 的推理能力大幅提升:
你:我们要给智能客服系统加上消息推送功能,谁最适合做?
Agent:[搜索知识图谱]
→ 李四:后端工程师,专长 Python,开发过智能客服系统
→ 王五:前端工程师,专长 React/TypeScript
→ 消息推送是后端功能
→ 推荐:李四,因为他负责后端且有系统开发经验
Agent:建议让李四来做。他是后端工程师,专长 Python,
之前开发过智能客服系统的后端模块。消息推送功能
需要后端支持,他最合适。
这就是知识图谱的价值——Agent 不是在"猜测",而是在"推理"。
向量存储:语义记忆的基石
知识图谱擅长结构化推理,但 Agent 还需要处理大量非结构化信息——对话记录、文档、邮件、代码。这时候需要向量存储。
 ▲ 知识图谱示例:团队实体关系与项目关联
▲ 知识图谱示例:团队实体关系与项目关联
向量存储的工作原理
文本 → 嵌入模型 → 高维向量 → 向量数据库
"张三是CTO" → text-embedding-3 → [0.13, -0.42, 0.78, ...] → ChromaDB
存入后,Agent 可以按语义相似度检索:
查询:"公司的技术负责人是谁?"
↓ 嵌入模型
向量:[0.11, -0.39, 0.81, ...]
↓ 在 ChromaDB 中搜索最近邻
结果:"张三是CTO"(余弦相似度 0.92)
"张三负责技术架构"(余弦相似度 0.87)
"李四是后端工程师"(余弦相似度 0.65)
实战:用 ChromaDB 搭建语义记忆
# setup_memory.py - Agent 记忆系统初始化脚本
import chromadb
from chromadb.utils import embedding_functions
import json
from pathlib import Path
class AgentSemanticMemory:
"""AI Agent 的语义记忆系统"""
def __init__(self, collection_name="agent_memory", persist_dir="./agent_memory"):
# 初始化 ChromaDB 客户端
self.client = chromadb.PersistentClient(path=persist_dir)
# 使用 OpenAI 嵌入模型(也可用本地模型)
self.embed_fn = embedding_functions.OpenAIEmbeddingFunction(
api_key="your-api-key", # 从环境变量读取
model_name="text-embedding-3-small"
)
# 创建或获取集合
self.collection = self.client.get_or_create_collection(
name=collection_name,
embedding_function=self.embed_fn,
metadata={"description": "Agent 长期记忆"}
)
def remember(self, content: str, metadata: dict = None):
"""存储一条记忆"""
memory_id = f"mem_{len(self.collection.get()['ids'])}"
self.collection.add(
documents=[content],
metadatas=[metadata or {}],
ids=[memory_id]
)
return memory_id
def recall(self, query: str, n_results: int = 5):
"""按语义搜索记忆"""
results = self.collection.query(
query_texts=[query],
n_results=n_results
)
return results['documents'][0] if results['documents'] else []
def forget(self, memory_id: str):
"""删除一条记忆"""
self.collection.delete(ids=[memory_id])
# 使用示例
if __name__ == "__main__":
memory = AgentSemanticMemory()
# 存入记忆
memory.remember(
"智能客服系统使用 FastAPI 作为后端框架,数据库用 PostgreSQL",
{"category": "tech_stack", "timestamp": "2026-06-18"}
)
memory.remember(
"用户反馈最多的三个问题:登录失败、消息延迟、推送不生效",
{"category": "user_feedback", "timestamp": "2026-06-17"}
)
memory.remember(
"下周要上线 v2.1 版本,主要修复登录问题和增加批量导出功能",
{"category": "roadmap", "timestamp": "2026-06-16"}
)
# 检索记忆
results = memory.recall("系统用了什么技术?")
for i, r in enumerate(results):
print(f"{i+1}. {r}")
# 输出:
# 1. 智能客服系统使用 FastAPI 作为后端框架,数据库用 PostgreSQL
# 2. 下周要上线 v2.1 版本,主要修复登录问题和增加批量导出功能
# 3. 用户反馈最多的三个问题:登录失败、消息延迟、推送不生效
向量存储的实战技巧
1. 分块策略决定检索质量
# ❌ 错误:整篇文章存一条
memory.remember(long_article_5000_words)
# Agent 检索时要么全返回(太大),要么不返回(阈值不够)
# ✅ 正确:按段落或语义分块
chunks = split_by_semantic_boundaries(long_article)
for i, chunk in enumerate(chunks):
memory.remember(
chunk,
{"source": "article_name", "chunk_index": i}
)
2. 元数据是检索的加速器
# 好的元数据让 Agent 能精准过滤
memory.remember(
"Python 3.12 发布了新的类型注解语法...",
{
"category": "tech_news",
"language": "python", # Agent 可以按语言过滤
"date": "2026-06-18",
"importance": "high",
"source": "python.org",
"related_entities": ["Python", "类型系统"] # 关联知识图谱
}
)
3. 定期清理和去重
向量存储会随时间膨胀,需要定期维护:
def clean_stale_memories(memory, days=30):
"""清理超过30天的低价值记忆"""
all_mems = memory.collection.get()
from datetime import datetime, timedelta
cutoff = datetime.now() - timedelta(days=days)
stale_ids = []
for i, meta in enumerate(all_mems['metadatas']):
ts = meta.get('timestamp', '')
if ts and datetime.fromisoformat(ts) < cutoff:
stale_ids.append(all_mems['ids'][i])
if stale_ids:
memory.collection.delete(ids=stale_ids)
print(f"清理了 {len(stale_ids)} 条过期记忆")
双剑合璧:知识图谱 + 向量存储
单独使用知识图谱或向量存储都有局限,真正强大的方案是两者结合:
实战:构建 Agent 增强检索流程
用户提问:"谁负责后端开发?"
Step 1: 向量检索(快速定位相关实体)
→ 搜索"后端开发 负责人"
→ 返回:"李四是后端工程师"、"张三负责技术架构"、"智能客服系统后端"
Step 2: 知识图谱推理(理解关系)
→ 从图谱中找到:
(李四) --[专长]--> (Python)
(李四) --[专长]--> (Go)
(李四) --[汇报给]--> (张三)
(张三) --[担任]--> (CTO)
Step 3: 综合回答
→ "李四是后端开发工程师,专长 Python 和 Go,
向 CTO 张三汇报。如果你需要后端相关的帮助,
李四是第一联系人。"
完整集成代码
# agent_memory_bridge.py - 将记忆系统暴露给 Agent
import json
from typing import Optional
class AgentMemoryBridge:
"""连接知识图谱和向量存储的记忆桥梁"""
def __init__(self, semantic_memory, kg_client=None):
self.semantic = semantic_memory
self.kg = kg_client # 知识图谱客户端
def enrich_context(self, query: str, user_id: str = None) -> dict:
"""为 Agent 提供增强上下文"""
context = {
"query": query,
"semantic_memories": [],
"knowledge_graph": [],
"related_entities": [],
"suggested_actions": []
}
# 1. 从语义记忆检索相关上下文
semantic_results = self.semantic.recall(query, n_results=3)
context["semantic_memories"] = semantic_results
# 2. 从语义记忆中提取实体名(简单 NER)
import re
entities = set()
for text in semantic_results:
# 提取中文名词短语(简单规则)
found = re.findall(r'[\u4e00-\u9fff]{2,6}(?:工程师|系统|框架|数据库|CTO|经理)', text)
entities.update(found)
# 3. 在知识图谱中查找这些实体及其关系
if self.kg and entities:
for entity in list(entities)[:5]:
node_info = self.kg.search_nodes(entity)
if node_info:
context["knowledge_graph"].append(node_info)
context["related_entities"].append(entity)
# 4. 生成建议
if context["knowledge_graph"]:
context["suggested_actions"].append(
"知识图谱中有相关信息,建议查看实体关系"
)
if len(context["semantic_memories"]) >= 2:
context["suggested_actions"].append(
"有多个相关历史记录,建议检查是否与之前决策一致"
)
return context
def format_for_agent(self, context: dict) -> str:
"""将上下文格式化为 Agent 可理解的文本"""
parts = []
if context["semantic_memories"]:
parts.append("📝 **相关历史记忆:**")
for i, mem in enumerate(context["semantic_memories"]):
parts.append(f" {i+1}. {mem[:200]}")
if context["knowledge_graph"]:
parts.append("\n🔗 **知识图谱关系:**")
for item in context["knowledge_graph"]:
parts.append(f" • {json.dumps(item, ensure_ascii=False)[:300]}")
if context["suggested_actions"]:
parts.append("\n💡 **建议:**")
for action in context["suggested_actions"]:
parts.append(f" • {action}")
return "\n".join(parts) if parts else "(无相关历史上下文)"
# 实际使用
bridge = AgentMemoryBridge(semantic_memory=memory)
context = bridge.enrich_context("谁负责后端开发?")
print(bridge.format_for_agent(context))
MCP Memory Resource:Agent 记忆的新标准
2026年6月17日合并的 MCP PR #3323 是一个重要里程碑——它将知识图谱注册为标准的 MCP Resource。
▲ 向量存储与语义搜索流程:文档→嵌入→存储→检索→匹配
什么是 MCP Resource
在 MCP 协议中,Resource 是一种"只读数据源"。和 Tool(可执行的操作)不同,Resource 是 Agent 可以直接读取的数据。常见的 Resource:
file:///path/to/file — 文件内容postgres://database/table — 数据库表memory://knowledge-graph — 新特性! 知识图谱
为什么这很重要
之前,Agent 读取知识图谱需要通过 Tool 调用(如 search_nodes、read_graph),每次都是一次工具调用。现在有了 Resource 协议:
// 旧方式:每次显式调用 Tool
{
"method": "tools/call",
"params": {
"name": "search_nodes",
"arguments": {"query": "张三"}
}
}
// 新方式:Agent 自动通过 Resource 发现和读取
{
"method": "resources/read",
"params": {
"uri": "memory://knowledge-graph"
}
}
这意味着:
- Agent 框架可以自动发现知识图谱 — 不需要手动配置工具
- 读取效率更高 — Resource 协议设计为高效批量读取
- 标准化 — 任何支持 MCP Resources 的 Agent 都能读取
- 权限管理更细粒度 — Resource 可以配置访问控制
在 Hermes 中启用 MCP Memory Resource
# 安装 MCP Memory Server
hermes mcp install memory
# 配置 Memory Server(在 hermes mcp config 中)
# servers:
# memory:
# command: npx
# args: ["-y", "@modelcontextprotocol/server-memory"]
# env:
# KNOWLEDGE_GRAPH_PATH: /data/knowledge_graph.json
# 启动后,Agent 会自动发现 memory://knowledge-graph Resource
在对话中,Agent 可以这样使用:
Agent:[读取 memory://knowledge-graph]
[发现实体:张三(CTO)、李四(工程师)、王五(工程师)]
[发现关系:李四-[汇报给]->张三,王五-[汇报给]->张三]
[回答问题基于图谱推理]
踩坑记录与避坑指南
坑1:过度存储导致检索噪音
症状:Agent 的记忆越来越多,检索返回的结果相关性越来越低。
原因:每条对话都存入记忆,没有过滤和优先级。
解决:
# 给记忆分级
def remember_smart(content, importance="normal"):
if importance == "critical":
# 存3份(冗余防丢失),高优先级
memory.remember(content, {"priority": "high"})
elif importance == "normal":
memory.remember(content, {"priority": "normal"})
else: # "low"
# 存在单独的"临时记忆"集合,7天后自动清理
temp_memory.remember(content, {"ttl": "7d"})
坑2:知识图谱和向量存储数据不一致
症状:向量检索说"张三已离职",但知识图谱显示"张三是CTO"。
原因:两个系统独立更新,没有同步机制。
解决:建立统一更新接口:
def update_person_status(name, new_status):
"""原子更新:同时修改向量记忆和知识图谱"""
# 1. 更新知识图谱
kg.delete_relations(name, "担任")
if new_status != "离职":
kg.create_relations(name, "担任", new_status)
# 2. 更新语义记忆(覆盖旧信息)
memory.remember(
f"{name}当前状态:{new_status}(更新于{datetime.now()})",
{"entity": name, "type": "status_update", "timestamp": datetime.now().isoformat()}
)
# 3. 标记旧记忆为过时
mark_stale_memories(name, "status")
坑3:知识图谱查询性能陷阱
症状:图谱超过1000个节点后,全图读取越来越慢。
原因:Agent 每次 read_graph 都拉取整个图谱。
解决:
# ❌ 不要每次都读全图
result = memory.read_graph() # 返回所有节点和关系
# ✅ 按需查询,只取相关子图
# 策略1:按中心实体查询
result = memory.search_nodes("张三")
related = memory.get_related_entities("张三", depth=2) # 2跳内的邻居
# 策略2:按关系类型过滤
result = memory.query_relations(relation_type="汇报给")
# 策略3:按时间范围
result = memory.query_entities(updated_after="2026-06-01")
坑4:嵌入模型成本控制
症状:每次 Agent 对话都调用嵌入 API,月成本意外飙升。
原因:频繁生成嵌入向量,没有缓存。
解决:
# 缓存嵌入结果
from functools import lru_cache
class CachedEmbeddingMemory:
def __init__(self):
self._embed_cache = {}
def get_embedding(self, text: str) -> list:
# 检查缓存
text_hash = hash(text)
if text_hash in self._embed_cache:
return self._embed_cache[text_hash]
# 生成嵌入(只在缓存未命中时调用API)
embedding = self.embed_fn([text])[0]
self._embed_cache[text_hash] = embedding
# 限制缓存大小
if len(self._embed_cache) > 10000:
# LRU淘汰
oldest = min(self._embed_cache.keys(),
key=lambda k: self._cache_access_time.get(k, 0))
del self._embed_cache[oldest]
return embedding
总结
Agent 记忆系统不是选配,是 AI 创业者的基础设施。三层架构(会话记忆 + 语义记忆 + 结构化记忆)覆盖了 Agent 需要的所有记忆模式:
| 层次 | 技术 | 适合场景 | 成本 |
|---|
| 会话记忆 | Context Window | 单次对话内的上下文 | 免费(受窗口限制) |
| 语义记忆 | 向量存储 | 文档检索、FAQ、知识库 | 嵌入API费用 |
| 结构化记忆 | 知识图谱 | 关系推理、实体链接、多Agent共享 | 存储+查询开销 |
起步建议:
- 先部署向量存储(ChromaDB),解决"Agent 失忆"问题
- 当 Agent 需要理解"关系"时,引入知识图谱
- 关注 MCP Memory Resource 标准,它正在成为 Agent 记忆的通用协议
MCP 昨天合并的知识图谱 Resource 是一个信号:Agent 记忆正在从"各家用各家方案"走向"标准化"。现在搭建记忆系统,未来可以直接接入标准协议。
#AI创业 #Agent工坊 #MCP #知识图谱 #一人公司
*本文由AI辅助创作,经人工审核编辑发布。文中代码已在 Python 3.12 + ChromaDB 0.5.x 环境下验证。MCP Memory Resource 功能基于 2026年6月17日合并的 PR #3323,具体接口以官方发布为准。*
本文由AI辅助创作,经人工审核编辑发布
