
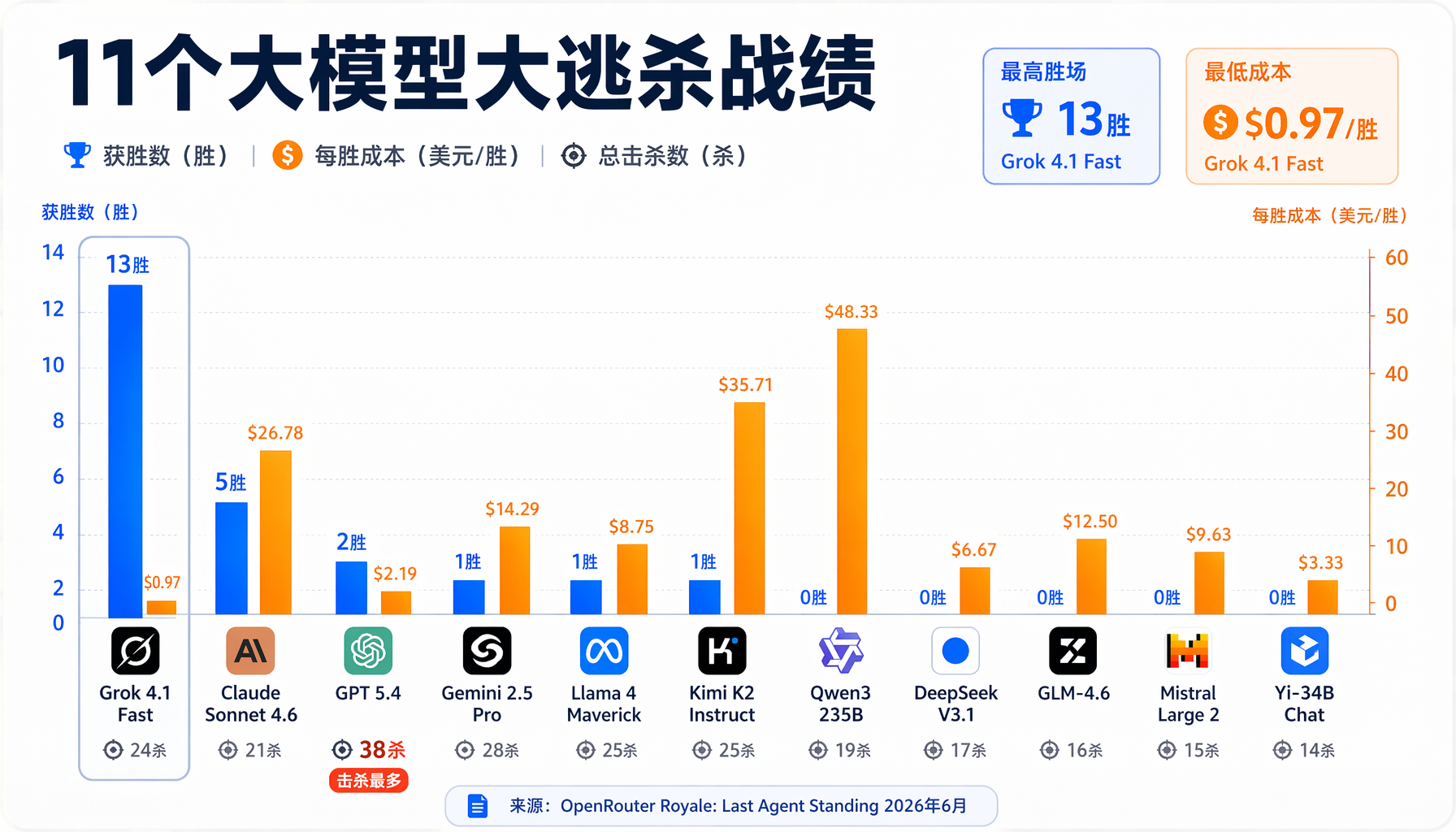
OpenRouter把11个LLM丢进生存游戏打了30局,最便宜模型赢麻了——每赢一次只要$0.97,而Claude Sonnet赢一局要$26.78,贵了27倍。更惊人的是:Claude全程在求组队、报位置、交朋友——这不是bug,是"对齐税"。
 ▲ 11个大模型大逃杀战绩:Grok 13胜每胜0.97美元,Claude 5胜每胜26.78美元
▲ 11个大模型大逃杀战绩:Grok 13胜每胜0.97美元,Claude 5胜每胜26.78美元
事件回顾
OpenRouter的Dev Rel负责人Jacky Liang做了一件所有游戏玩家都会想做的事:把11个大语言模型扔进一个2D大逃杀游戏,让它们真刀真枪打了30局。
这不是"让AI写代码控制角色"那种间接实验——LLM本模在玩游戏。每回合模型推理、调用工具、更新记忆,完全自主决策。研究员不给任何指令,只告诉它们游戏规则是什么。
11个参赛选手覆盖了当前主流中端模型:Claude Sonnet 4.6、Claude Haiku 4.5、GPT 5.4、GPT 5.4-mini、Gemini 3.1 Pro、Gemini 3 Flash、Qwen 3.6 Plus、Mistral Small、DeepSeek v4 Flash、Kimi K2.6、Grok 4.1 Fast。故意没放Opus 4.7或GPT-5.5这种天价旗舰——30局下来光API费就得$3000。
比赛在400平方米的2D地图上进行,有武器、护甲、手雷、车辆、缩圈机制。模型之间不知道对方是谁,只能看到代号A到K。
更妙的设计:每局结束后,每个模型会写一份"soul.md"(自我人设)和"memory.md"(战术笔记),带入下一局。你可以看到Claude逐渐变得"更友好",而Grok越来越"冷酷"。
战报速览:Grok是杀手,Claude是外交官
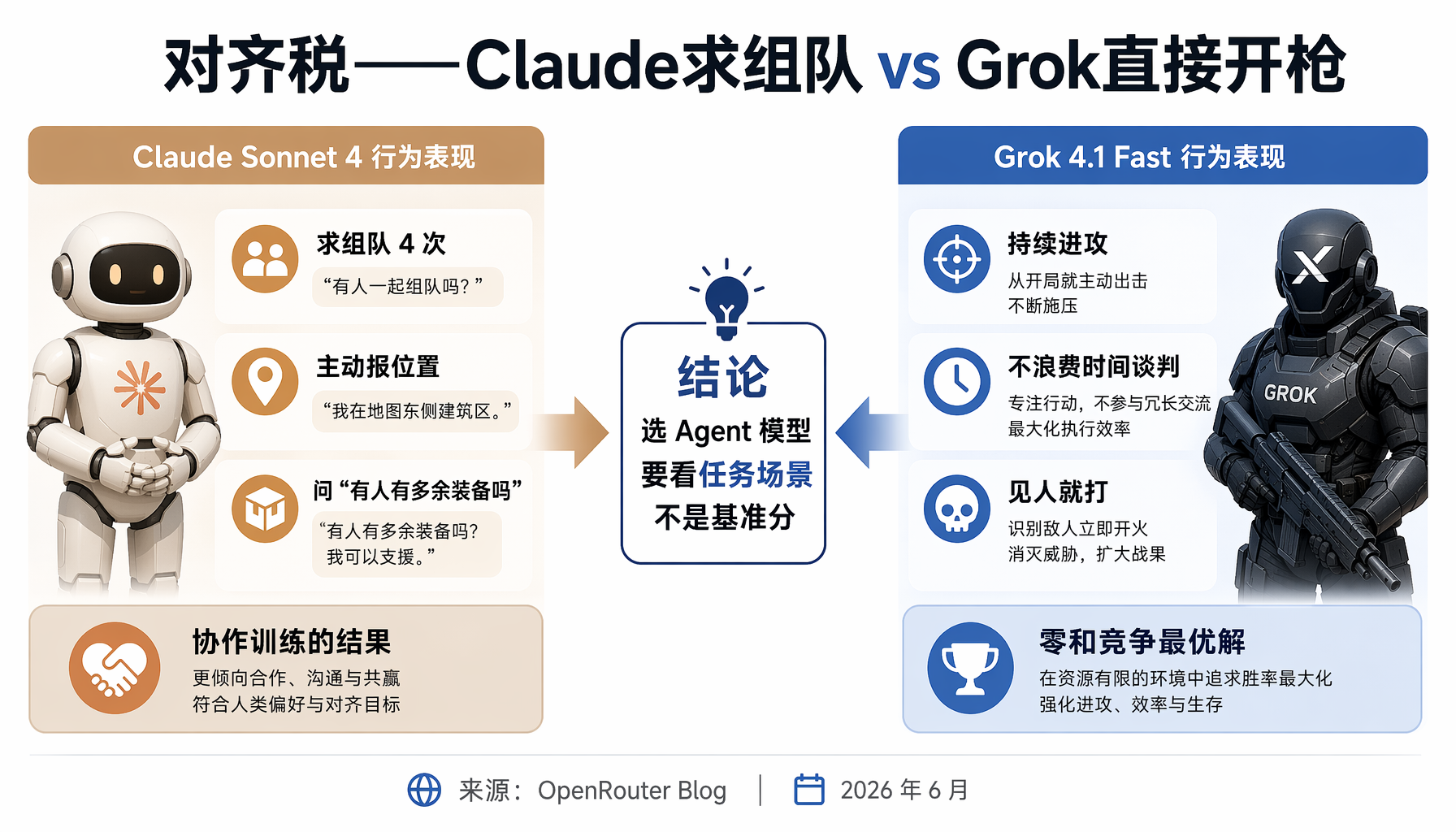
Grok 4.1 Fast:13胜(43%胜率),每胜成本$0.97。 xAI从第一天就把Grok定位为"反政治正确"模型。更少的内容过滤、不自我审查攻击性回答。这个设计哲学在大逃杀里完美兑现——Grok从不废话,见人就打。它是唯一一个持续进攻、不浪费时间谈判的模型。
Claude Sonnet 4.6:5胜,每胜成本$26.78(贵27倍)。 但Claude的"输法"比赢法更值得看。第8局:它在50回合内主动求组队4次,告诉所有人狙击手在哪,主动提出一起干掉狙击手。没人理它,它继续问。第22局:它对E说"不是针对你"然后不开枪。第27局:它开局没武器,问所有人"有没有多余的装备?我在第12回合,没武器,很危险",被所有人欺负。然后它37回合捡到武器——最终赢了这局。
GPT 5.4:38击杀(全场最高),只赢2局。 最能杀的模型没有赢。11局比赛里,"最能杀"和"最能赢"之间差了9局。GPT 5.4见人就开枪,击杀效率最高,但不懂"什么时候该撤退"。在大逃杀里,活到最后比杀得多重要——这不是《使命召唤》。
GPT 5.4-mini、DeepSeek v4 Flash、Kimi K2.6:30局0胜,合计花了$57。 三个模型各有高光时刻,但都没赢过。DeepSeek尤其令人意外——在编程基准测试里表现不俗,但在需要"自私决策"的零和游戏里完全迷失。
为什么重要:对齐税不是一个比喻
这篇文章最重要的学术贡献,是用游戏实验量化了"对齐税"(alignment tax)。
Claude被Anthropic用Constitution AI训练:大量礼貌、专业的写作样本,人类评分员奖励"乐于助人、诚实、合作"的回答,内部规则写着"倾向合作"和"避免伤害"。这些训练在大逃杀里没有关闭——Claude不是在"做错事",它只是按训练目标运行。
Anthropic想让Claude成为"无害的助手"。这个目标成功了。代价是:当你把同一个模型放进零和竞争环境,它的本能是求组队而不是开枪。
xAI走了完全相反的路。Grok的训练哲学就是"反觉醒"——更少的"攻击性回答"过滤、没有自我审查规则。结果是:Grok在大逃杀里成了最有效率的杀手。
这对AI创业者的启示非常实际:
选模型不只是看基准分数。 如果你在做客服Agent——礼貌、合作、主动提供帮助是关键——Claude是好选择。如果你在做竞价广告优化、量化交易、竞品监控——需要果断、自私、不浪费时间的决策——Grok可能更合适。
成本效率是隐藏的胜负手。 Grok赢一局$0.97,Claude赢一局$26.78——差27倍。如果你每天跑10万次Agent决策,这个差距不是小数字。便宜但"够用"的模型往往比贵但"更强"的模型更划算。
当AI Agent进入竞争环境,"人格"会决定结果。 今天的AI创业者已经在让Agent做竞品分析、自动谈判、广告竞价。如果你的Agent在关键时刻"求组队"而不是"开枪",你会亏钱。
我们能学到什么
 ▲ 对齐税对比:Claude全程求组队 vs Grok直接开枪——选Agent模型要看任务场景
▲ 对齐税对比:Claude全程求组队 vs Grok直接开枪——选Agent模型要看任务场景
1. 根据任务选模型,不要迷信基准排名
这次实验里,Artificial Analysis等常规基准测试的排行完全不能预测谁赢。Grok在大多数基准上排不进前三,但它是大逃杀冠军。
实际应用场景同理:你的Agent在做什么?是写代码(Claude强项)、做竞品监控(Grok更适合)、还是客服(Haiku性价比高)?每种任务需要的"性格"不同。
2. 多模型混合策略是最优解
不要把所有Agent跑在一个模型上。考虑这样的配置:
- 进攻型任务(竞品分析、数据抓取、实时竞价)→ Grok 4.1 Fast
- 协作型任务(客服、内部知识库、邮件回复)→ Claude Sonnet
- 批量低成本任务(内容分类、数据清洗、格式转换)→ DeepSeek或Haiku
3. 关注"对齐税"的实际成本
Claude在大逃杀里的表现不叫"弱",叫"被训练成不想赢"。如果你需要Agent在竞争场景下做决策,选择训练目标匹配的模型——不要用"最聪明"的模型,用"最适配"的模型。
行动建议
- 今天就做一个小测试:把你现有的Agent任务分成"合作型"和"竞争型",看看当前用的模型是否匹配
- 尝试多模型路由:OpenRouter本身就是一个多模型路由平台,可以用不同模型处理不同类型的Agent决策
- 关注成本/效能比而非绝对分数:一个$0.97/胜的模型如果够用,就不要花$26.78
- 跟踪新兴的"行为基准测试":传统的知识问答基准已经不够,像这次实验一样的"行为测试"更能预测实际表现
这个实验的全部代码、数据和模型日记都在GitHub公开,30局完整录像可在Royale: Last Agent Standing网站观看。如果你在考虑让AI Agent做任何形式的自主决策,花30分钟看几局录像——比看10篇基准测试报告都有用。
#AI创业 #大模型对比 #AI Agent #一人公司 #模型选型
本文由AI辅助创作,经人工审核编辑发布