
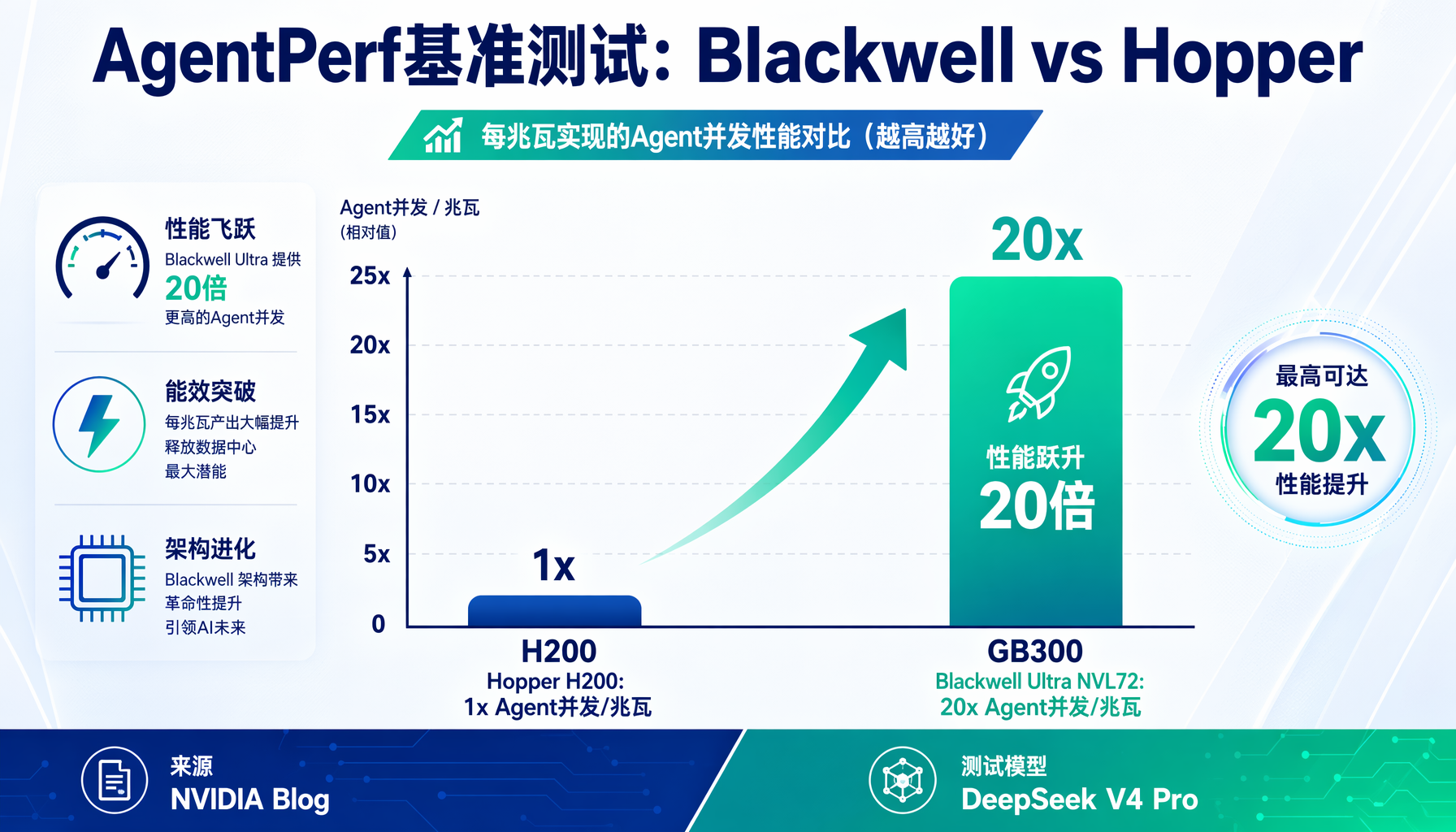
AgentPerf横空出世——这是AI行业第一个专门衡量"Agent推理效率"的基准测试。Nvidia Blackwell Ultra NVL72跑出了每兆瓦20倍于Hopper的Agent并发数,单token成本降低35倍。对于每天调用数万次LLM的AI创业者来说,这直接意味着:同样的钱,现在能跑35倍的Agent任务。
 ▲ ▲ AgentPerf基准测试:Blackwell Ultra vs Hopper — 每兆瓦Agent并发数20倍提升
▲ ▲ AgentPerf基准测试:Blackwell Ultra vs Hopper — 每兆瓦Agent并发数20倍提升
事件回顾:AgentPerf,第一个为Agent而生的基准测试
2026年6月13日,AI分析机构Artificial Analysis发布了AgentPerf——行业首个专门衡量Agentic AI基础设施性能的基准测试。首轮结果毫不意外:Nvidia Blackwell Ultra NVL72平台全面领先。
具体数据:
- 每兆瓦可运行的Agent数量:Blackwell Ultra NVL72是上一代Hopper H200的20倍
- 整体性能提升:GB300 NVL72相比Hopper平台,Agent吞吐量提升50倍
- 单token成本:降低35倍
测试使用的模型是DeepSeek V4 Pro——当前最具代表性的混合专家(MoE)模型,也是实际生产中驱动最先进Agent的主力模型。
这不是跑个分就完事。AgentPerf的设计逻辑直指AI创业者的核心痛:Agent推理和传统聊天推理本质上是两类完全不同的工作负载。
为什么Agent推理的基准测试这么重要
传统LLM推理是一个"短跑"——一次API调用,一个回复,结束。但Agent推理是一场"接力赛":一个任务被拆成几十到上百次LLM调用,每次调用都带着越来越长的上下文,中间还要穿插代码执行、数据库查询、网页浏览等工具调用。
这种区别意味着传统推理基准(测单次请求延迟和并发吞吐)完全不适用于Agent场景。一个请求延迟10ms的系统做Agent任务可能比一个延迟100ms但内存带宽更强的系统慢得多——因为Agent任务瓶颈在上下文传递和工具调用的协同效率,不在单次回复速度。
AgentPerf的设计直接取自真实编程Agent的轨迹:12种以上编程语言的公开代码仓库中,Agent接收任务→读取文件→编写和编辑代码→执行命令→根据结果迭代。所有工具调用的CPU消耗都精确模拟,确保测试结果只反映GPU加速计算的实际差异。
对于每天调用LLM数万次的AI创业者来说,AgentPerf的出现意味着:
- 选型有了标准:不再靠厂商PPT选硬件,有了可对比的第三方数据
- 成本可预测:35倍成本差异不是小优化,是足以改变商业模式的数量级变化
- 架构可规划:知道Agent推理的瓶颈在哪里,才知道该把钱花在什么地方
为什么是Blackwell Ultra:全栈协同设计的胜利
Blackwell Ultra NVL72不是简单地把72块GPU塞进一个机架。它的核心优势来自三个层面的协同设计:
第一层:机架级互联。 GB300 NVL72把72块GPU通过NVLink连接成一个单系统,让DeepSeek V4 Pro这样的MoE大模型能够高效地分布式执行——不同专家模型跑在不同GPU上,数据传输走NVLink而非慢得多的网络。
第二层:CUDA内核优化。 通信和计算重叠执行——协调各个专家的开销被"吸收"进计算时间,而不是叠加到延迟上。这直接提升了Agent并发数。
第三层:TensorRT LLM推理引擎。 把输入处理(prefill)和输出生成(decode)分离优化。随着并发Agent会话数量增加,这一优化的价值指数级放大。
已在使用Blackwell的推理服务商包括:Baseten、DeepInfra、Together AI。其中Together AI已经在为Cursor提供实时推理服务——SpaceX刚刚以600亿美元收购的那家公司,就是用Blackwell做Agent推理。
 ▲ ▲ Agent推理成本革命:35倍下降,50x性能提升 | 全栈协同设计
▲ ▲ Agent推理成本革命:35倍下降,50x性能提升 | 全栈协同设计
这对AI创业者意味着什么
如果你的产品是一个需要频繁调用LLM的Agent应用——无论是自动编程工具、客服机器人还是内容生成流水线——Blackwell Ultra NVL72带来的35倍成本下降不是"锦上添花",而是"地基重打"。
具体到三个场景:
场景一:编程Agent。 以Claude Code或Codex为例,一次编程任务动辄上百次LLM调用。如果单token成本降35倍,同样的月度预算可以支持的并发用户数直接乘以35。过去只能服务10个付费客户的硬件成本,现在能服务350个。
场景二:内容生成流水线。 AI内容创业的核心成本是模型推理。一条完整的公众号文章流水线(选题→搜索→写作→配图→排版)可能需要50-100次LLM调用。35倍成本下降意味着从"精打细算每篇文章成本"变成"批量生产不计成本"。
场景三:多Agent协作系统。 OpenClaw和Hermes Agent这类多Agent框架的算力需求是指数级的——每个子Agent都有自己的上下文和工具调用链。AgentPerf测试的"每兆瓦并发Agent数"直接衡量了这种场景下的实际承载能力。
行动建议
短期(1-3个月):
- 如果你是Together AI或Baseten的客户,尽快询问Blackwell实例的可用时间。先上车的Agent应用将拥有显著的成本优势
- 如果你的Agent应用还跑在H100/H200上,现在开始做性能基准——用你自己的Agent任务测出当前系统的"每元Agent数",为迁移做对比准备
中期(3-6个月):
- 重新做一次定价模型:35倍成本下降意味着你的利润模型需要重算。很多现在"算不过账"的Agent应用场景将变得可行
- 关注DeepSeek V4 Pro在Blackwell上的实际表现——AgentPerf用这个模型不是随便选的,它代表的是MoE模型在Agent场景下的最优解
长期(6个月+):
- 你的竞争对手也会拿到Blackwell。成本优势窗口期可能只有3-6个月,之后比拼的将回归产品体验和用户留存本身
- 关注Nvidia Vera Rubin(预计2026 Q3发货)和800V DC——这波硬件迭代远未结束
风险提示
- Blackwell Ultra NVL72目前主要面向云服务商和大企业,中小创业者可能需要通过推理API间接使用,成本优势会打折扣
- AgentPerf只测了DeepSeek V4 Pro一个模型,不同模型在Blackwell上的表现差异可能很大
- 35倍成本下降是相对于Hopper(H200),如果你的应用目前跑在更新的硬件上,实际优化幅度可能小于35倍
本文由AI辅助创作,经人工审核编辑发布