
HN技术社区近700人参与的实战讨论揭示了残酷真相:高端硬件跑本地模型依然太慢,云端AI编程助手短期内无可替代——但这不意味着你该放弃自建。
 ▲ ▲ 本地AI编程模型性能对比:4个开源模型 vs 云端标杆
▲ ▲ 本地AI编程模型性能对比:4个开源模型 vs 云端标杆
事件回顾
2026年6月15日,一位开发者在Hacker News上抛出一个直击灵魂的问题:"有人用本地模型替代Claude/GPT做日常编程了吗?"这个帖子在24小时内引爆了整个技术社区——694个点赞、339条评论,登顶HN热榜前三。
这不仅仅是一个技术问题。这背后是每一个AI创业者都在算的一笔账:Claude Code每月200美元、GPT-5.5按token计费、Cursor Pro每月20美元……如果本地部署能省下这笔钱,谁会不愿意?
讨论热度超乎想象。从拥有双RTX Pro 6000 Blackwell的企业级玩家,到只有M4 MacBook的独立开发者;从用Qwen 3.6 27B跑了三个月的老兵,到刚开始用Ollama试水的初学者——所有人都在这条帖子里贡献了自己的真实数据。
为什么重要
第一,这是AI编程工具市场走向的分水岭信号。 694个点赞不是小数字——这代表了一大批开发者在认真考虑"逃离云端订阅"。如果本地模型在某一天真的追上了云端水平,Anthropic和OpenAI的订阅收入将受到直接冲击。
第二,讨论揭示了一个被市场忽略的"效率鸿沟"。 根据评论区的实测数据,即使是DeepSeek V4 Flash在双RTX Pro 6000 Blackwell上也只能跑到160 tok/s的"裸速度"——注意,这是推理模型,实际可用输出远低于此。而Claude Code和GPT-5.5的云端响应时间通常以毫秒为单位。一位用户直言:"用local模型跑通宵写一个函数,生成速度只有0.7 tok/s,这是把白天的工作拖到晚上。"
第三,硬件成本账比想象中更残酷。 评论区反复出现的硬件配置是:至少需要80GB+ VRAM的GPU。这意味着起步价就是一张企业级显卡——RTX Pro 6000 Blackwell售价约6800美元(中国市场约5万元人民币),而128GB内存的Strix Halo平台用户也抱怨"模型根本装不下"。
一位名叫arjie的开发者分享了最接近"成功"的配置——双RTX Pro 6000 Blackwell跑DeepSeek V4 Flash——但结论是:"快是快,但更多是习惯让我继续用Claude Code和Codex。"
本地模型的真实表现:来自一线的五条硬数据
1. Qwen 3.6 27B:最接近可用的开源选手。 用户K0balt的实测结论是"大约等于Claude Haiku 4.5的水平,在某些任务上接近Sonnet"。但注意,这是27B的dense模型——能在消费级硬件上跑的最高规格了。
2. Gemma 4 on M4:token速度显著低于云端。 用户tumetab1的测试显示"每秒token数明显低于云端"。同时提醒:缺乏帮助企业选择本地模型和工具链的基础设施——这不是技术问题,是生态问题。
3. Kimi 2.6和GLM 5.1:在AVX-512矩阵转置测试中双双翻车。 用户HappySweeney的测试场景非常实际:把一个标量函数改成AVX-512优化的bit-matrix转置——云端模型轻松搞定,两个开源模型完全失败。这说明本地模型在"底层优化类任务"上与云端差距最大。
4. MiniMax 2.7 (Q3量化) on Strix Halo:220 tok/s预处理但生成极慢。 用户_davide_的实测是30 tok/s的生成速度,结论是"Strix Halo在AI用途上感觉像玩具"。
5. GLM 4.7 Flash:代码智能体任务表现最接近可用的本地模型。 用户ecshafer的对比结论是"GLM在agent式编程上最好",但仍然认为远不及GPT-5.5或Claude Opus 4.8。
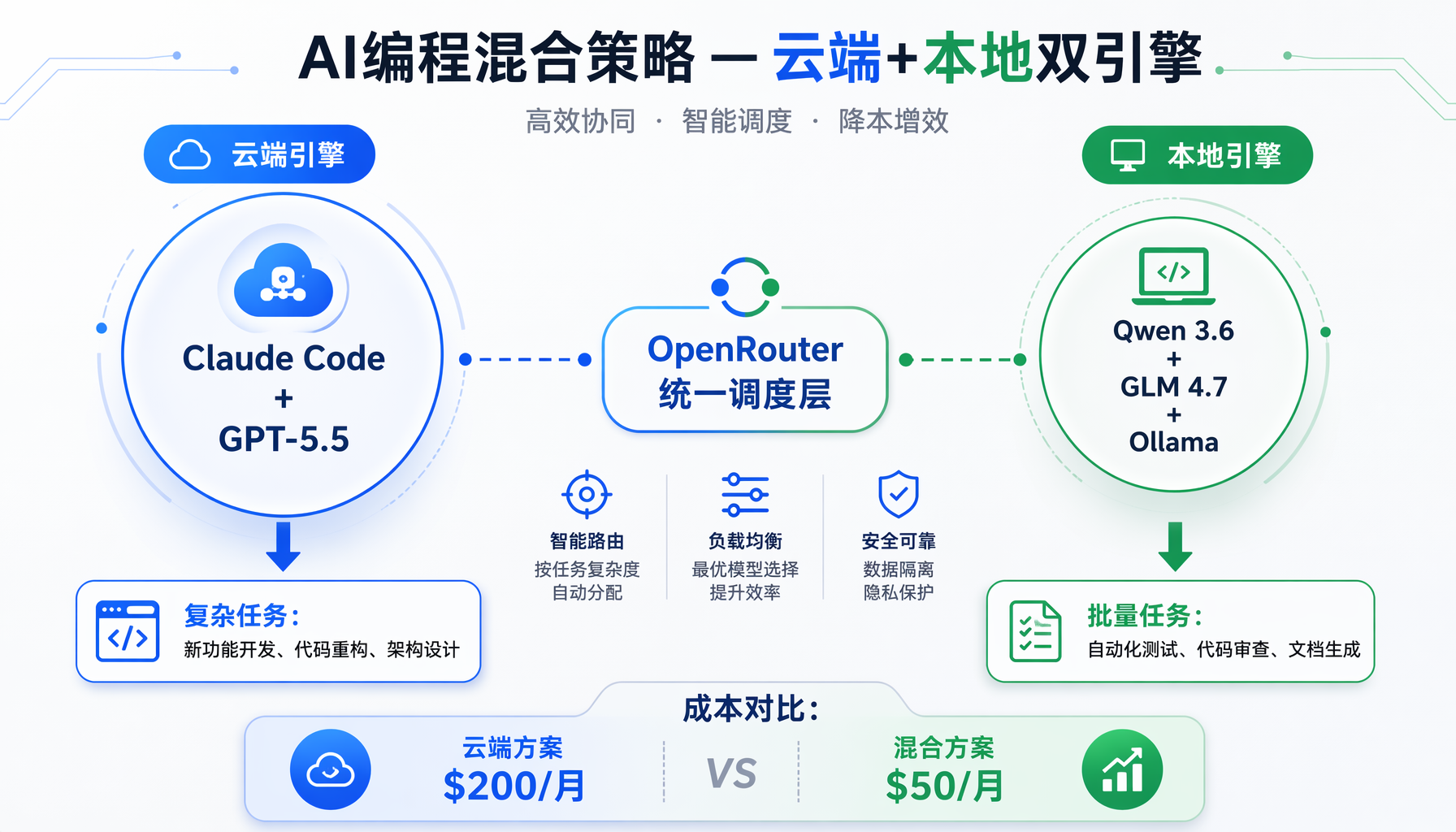
 ▲ ▲ AI编程混合策略架构:云端主力+本地辅助双引擎方案
▲ ▲ AI编程混合策略架构:云端主力+本地辅助双引擎方案
矛盾的真相:想逃但逃不掉
这场讨论最讽刺的结论来自用户ryandrake的精准吐槽:
"这类帖子的回复永远不够具体,能用的人说'我用Qwen 3.5效果很好!'但从不告诉你用的什么量化、什么参数、什么上下文长度、什么GPU、多少VRAM……"(来源:HN评论)
这正是本地模型生态的核心问题:碎片化。云端AI编程工具是"开箱即用"的——打开终端、敲claude、开始写代码。本地部署则需要你在模型选择、量化方案、硬件配置、推理框架、上下文管理之间反复试错。
用户system2的评论一针见血:"在我能买到80GB VRAM的GPU之前,我不会尝试。本地LLM总是缺少一些需要更大模型才能完成的东西。"
三条出路:一人公司和独立开发者的务实策略
面对这个"想逃逃不掉"的困局,HN评论区也浮现出了三条务实的路线:
路线一:混合策略——云端主力+本地辅助。 日常编码用Claude Code/Codex解决复杂问题,本地模型跑自动化测试、代码审查、批量重构等不需要即时响应的任务。用户arjie的双卡方案就是这个思路——本地跑DeepSeek V4 Flash做自动写码+自动审查。
路线二:OpenRouter中转——低成本试错。 用户kertoip_1的建议非常实操:"把你的编程工具接到OpenRouter上自己试。"OpenRouter聚合了所有主流开源模型,按token付费,不需要买硬件就能对比Qwen、Gemma、GLM、DeepSeek等所有选手的实际表现。成本远低于买一张企业级GPU。
路线三:等Strix Halo成熟——AMD的桌面APU革命。 用户christkv在等待antirez的ds4项目(一个专为Strix Halo优化的本地LLM推理引擎)稳定。Strix Halo是AMD下一代桌面APU,集成40CU GPU+统一128GB内存架构,理论上能把"本地跑大模型"的成本从5万元降到1万元以内——但目前仍是"未来时"。
行动建议:六个你现在就能做的事
- 立刻去OpenRouter上做一次横向对比。 用你今天正在写的代码,把同一个任务发给Qwen 3.6 27B、Gemma 4、GLM 4.7 Flash、DeepSeek V4 Flash——看看哪个最接近你的工作流。成本不到5美元。
- 计算你的"云端账单"。 把你过去三个月的Claude Code/Codex/Cursor订阅费用加总。如果超过200美元/月,考虑混合策略(主力云端+部分任务本地化)已经值得。
- 不要买硬件,先租云GPU测试。 在决定买一张5万元的RTX Pro 6000之前,花500元在云GPU平台租同样配置跑一周。评论区大量用户买了硬件后发现"装不下想用的模型"。
- 关注两个关键指标:上下文窗口和工具调用能力。 本地模型最大的两个短板不是生成质量,而是(a)不足以容纳整个代码库的上下文窗口;(b)无法像Claude Code那样调用shell、读写文件、搜索代码——这些是AI编程助手的核心能力,不只是"生成代码"。
- 如果只用AI做代码补全,本地模型已经够用。 对于Tab键补全级别的需求(非agent式编程),Qwen Coder系列在消费级GPU上已经能做到100ms以内的响应——比任何云端API都快。
- 记住最诚实的结论:2026年6月的本地模型,在agent式编程上离Claude Code/GPT-5.5还有至少一代的差距。 不是"做不到",也不是"做不好"——是"你会在等待生成的过程中失去耐心,然后切回云端"。但差距正在以肉眼可见的速度缩小。
一个值得关注的暗流:Anthropic的"本地化"布局
就在这场讨论爆发的同一周,Anthropic宣布了Claude Corps——一个1.5亿美元的国家级AI人才计划,将在未来一年内向400+非营利组织派驻1000名AI研究员。表面上是公益,本质上是在培养整整一代"Claude原住民"——这些研究员经过一年的Claude深度使用后进入就业市场,他们的肌肉记忆将深度绑定Anthropic生态。
这与本地模型的"去依附"诉求形成了有趣的镜像:一边是开发者追求技术自主权,另一边是大厂通过人才管道锁定生态粘性。2026年下半年,这场"云端vs本地"的角力只会更加激烈。
#AI创业 #AI编程 #本地模型 #一人公司 #ClaudeCode
本文由AI辅助创作,经人工审核编辑发布