
一组预算模型(Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro)合成输出后,DRACO深度研究得分64.7%,超越GPT-5.5的60.0%,成本仅为单模型的一半。
 ▲ ▲ 预算模型融合 vs 单体模型 DRACO基准测试得分对比
▲ ▲ 预算模型融合 vs 单体模型 DRACO基准测试得分对比
事件回顾
6月14日,OpenRouter正式发布了Fusion功能——一种将多个AI模型的输出进行"融合"的API调用方式。与传统单一模型调用不同,Fusion允许用户选择一组"参与模型"和一个"裁判模型",由裁判模型分析所有参与模型的输出,找出共识点、矛盾点、遗漏的视角和盲区,然后生成一份综合最优答案。
这不是简单的"选最好的那个"——裁判模型真正的价值在于结构化分析:它会输出每个参与模型的强项弱项、它们的分歧所在、以及最终融合时如何取舍。
OpenRouter用DRACO基准测试(100道深度研究题,测试推理+工具调用+知识检索的综合能力)做了系统验证,结果相当惊人:
融合模型全面超越单体模型。 最顶配的组合——Claude Fable 5 + GPT-5.5融合后得分69.0%,超越Fable 5单独跑的65.3%和GPT-5.5的60.0%。
但更让AI创业者兴奋的是预算组合的实力。 三个预算模型——Google Gemini 3 Flash、Moonshot Kimi K2.6、DeepSeek V4 Pro——被Opus 4.8裁判模型融合后,得分64.7%,仅次于Fable 5的65.3%,却超越了GPT-5.5(60.0%)和Opus 4.8(58.8%)。而且成本只有Fable 5的50%。
还有一个有趣的发现:同一个模型和自己融合也能涨分。 Opus 4.8 + Opus 4.8融合后得分65.5%,比单次Opus 4.8的58.8%提高了近7个百分点。这说明融合的价值不只在"多角度",多次采样的组合本身就能提升可靠性。
为什么重要
对AI创业者来说,这个新闻的冲击力在于三点:
第一,它打破了"更好的AI=更贵的模型"这个隐含假设。 过去一年里,行业默认的叙事是:前沿模型就是最好的,想要最好结果就得付最贵的钱。Fusion的数据证明,把几个便宜模型搭在一起的"模型拼盘",质量可以超过单独跑一个最贵的模型。
第二,它给出了一个明确的生产级模型路由策略。 Vercel 6月9日发布的AI Gateway生产指数已经显示,DeepSeek以1%的支出吃下了17%的token量,而Anthropic以65%的支出份额拿走了最复杂的高风险任务。Fusion给这条路由策略加了一个新维度:不只要把不同任务分给不同模型,同一道题也可以同时问多个模型再择优融合。
第三,它暗示了"AI模型即商品"的加速到来。 当三个预算模型的融合输出能超过一个前沿模型时,模型的差异化在缩小——而模型组合的策略在放大。对于一人公司或小型创业团队,这意味着不必锁死某一个供应商,可以根据成本和质量动态调配。
我们能学到什么
1. 预算模型组合可以替代昂贵模型,立省50%以上
如果你的业务场景是深度研究、长文分析、多步骤推理(这正是DRACO基准测试的类型),用Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro三件套做融合,效果已经接近Fable 5,成本只有一半。具体操作上,OpenRouter的Fusion API调用方式和普通模型调用完全一样——一个model参数、一个messages数组,剩下的并行分发和融合分析都在服务端完成。
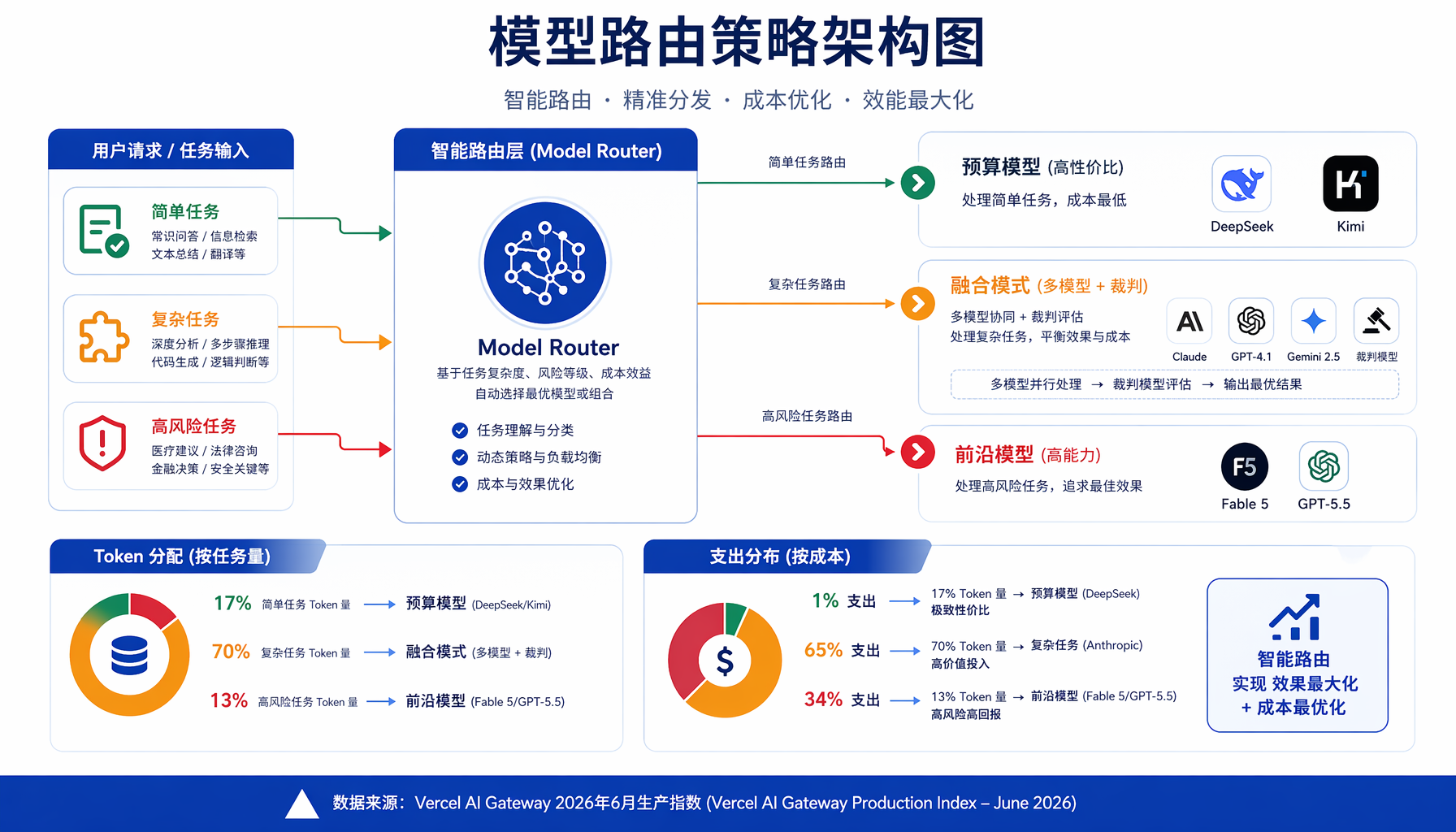 ▲ ▲ AI模型路由策略:按任务复杂度动态分配模型资源
▲ ▲ AI模型路由策略:按任务复杂度动态分配模型资源
2. 同一个模型跑两次比跑一次强,免费的"self-consistency"
Opus 4.8自身融合涨了6.7个百分点的发现非常重要。这意味着即使只用一种模型,通过多次推理+融合(类似self-consistency的思想),也能显著提升输出质量。对于不能换成多个供应商的场景(比如数据合规要求必须用某个特定模型),这提供了一个零额外成本的提效方法。
3. 模型路由正在成为AI基础设施的"操作系统层"
一周之内,Vercel发布生产级token分布数据(DeepSeek 17% vs Anthropic 65% spend),OpenRouter发布模型融合功能——这两件事背后的共同信号是:模型路由层正在快速成熟。 未来的AI应用架构里,决定"这道题找谁做"的路由策略,会和模型本身同等重要。AI创业者应该把模型路由能力当作核心竞争力来建设,而不是外包给某个单一供应商。
4. 裁判模型的选择是融合质量的上限
从基准测试看,所有融合组合都用Opus 4.8做裁判模型——这意味着融合的好坏,很大程度上取决于裁判模型本身的分析能力。如果你的裁判模型不够强,融合的效果会大打折扣。实操建议:裁判模型至少要比参与模型高一个档次,或者和最强的参与模型同级。
行动建议
- 立刻测试Fusion。 如果你已经在用OpenRouter调用模型(国内可以通过API代理),把model参数从
"openai/gpt-5.5"改成"openrouter/fusion",直接就能体验融合效果。默认面板是Fable 5 + GPT-5.5,裁判是Opus 4.8。 - 建立自己的"模型组合矩阵"。 根据你的业务场景,测试不同的预算模型组合。比如中文内容创作场景可以试Kimi K2.6 + DeepSeek V4 Pro + Qwen的组合;代码生成场景可以试DeepSeek V4 Pro + Claude Sonnet的组合。关键是找到你所在领域"性价比最优"的搭配。
- 把模型路由做成基础设施。 不要等到需要省钱的时候才去想"要不要换模型"。现在就应该在你的产品里抽象出一层Model Router,根据任务复杂度、成本预算、延迟要求动态选择单模型还是融合模式。
- 关注OpenRouter的动向。 作为目前唯一提供生产级Fusion API的平台,OpenRouter的产品迭代方向(更灵活的裁判配置、自定义面板、成本可见性)会直接影响AI创业的模型策略。
本文由AI辅助创作,经人工审核编辑发布