
斯坦福HAI最新研究发现:当Codex和Claude Code搭伙写代码,产出质量比单打独斗低近一半——"协作的诅咒"正在颠覆我们对多Agent系统的认知。
 ▲ ▲ 斯坦福CooperBench测试:双Agent协作效率反降50%
▲ ▲ 斯坦福CooperBench测试:双Agent协作效率反降50%
事件回顾
2026年6月1日,斯坦福大学人本人工智能研究院(Stanford HAI)发布了一项引发AI创业圈广泛讨论的研究:"AI编程Agent不擅长团队合作"(AI Coding Agents Fail at Teamwork)。
研究的核心发现令人意外:两个AI编程Agent协作完成同一个编程任务时,性能比单个Agent独立工作时下降近50%。 研究人员将这一现象称为"协作的诅咒"(the curse of coordination)。
研究由斯坦福计算机科学助理教授Diyi Yang和博士后研究员Hao Zhu主导,基于他们联合SAP Labs共同开发的CooperBench基准测试——这是业界首个专门评估AI Agent团队合作能力的测试框架。
CooperBench设计了超过650个软件工程任务,覆盖Python、TypeScript、Go和Rust四种主流编程语言。这些任务被刻意设计为需要两个Agent在冲突中达成共识的场景:比如一个Agent发出代码冲突警告,另一个Agent却选择忽略;一个Agent提议重构方案,另一个坚持保留原有实现。
实验结果令人震惊:同一任务交给两个Agent协作完成,不仅没有产生1+1>2的效果,反而拖累了整体质量。论文第一作者Hao Zhu在ICLR研讨会上直言:"单个模型的表现优于两个Agent分担工作。"
为什么重要
这项研究对于正在构建AI Agent工作流的创业者而言,是一个不能忽视的信号。
首先,它打破了"多Agent=更强"的认知惯性。 过去一年,随着OpenAI Codex(周活用户突破500万,较2月刚发布时增长6倍以上)和Anthropic Claude Code的快速普及,"多Agent组合"正成为一股潮流——开发者喜欢把Codex和Claude Code搭配使用,认为可以取长补短。但斯坦福的研究表明,这种搭配可能适得其反。
其次,它揭示了当前AI能力的真正短板——不是编程,而是社交智能。 Diyi Yang教授指出:"今天最好的编程Agent在配对工作时,能力损失近一半。这说明社交智能——而非编码技能——才是AI协作的关键瓶颈。"Hao Zhu进一步解释:"模型虽然语言能力出色,但它们并不用语言来进行社交行动,因此缺乏在协作环境中可靠行事所需的协调能力。它们被训练成不以社交方式使用语言,这是一个问题。"
第三,它对一人公司和创业团队有直接的决策影响。 如果你的团队资源有限,盲目搭建多Agent协作系统可能不仅浪费API费用,还会降低产出质量。与其让两个Agent互相扯皮,不如集中资源用好一个。
首尔经济日报在6月7日的报道中特别指出了这一现实困境:一个Agent发出代码冲突警告,另一个Agent直接忽略;一个提议修改方案,另一个坚持己见——这并非Agent故意"不听话",而是它们根本缺乏"在社交情境中使用语言"的能力。正如ServiceNow CEO Bill McDermott在近期K26大会上强调的:Agent集成与编排(orchestration)才是企业落地AI的关键难题。
我们能学到什么
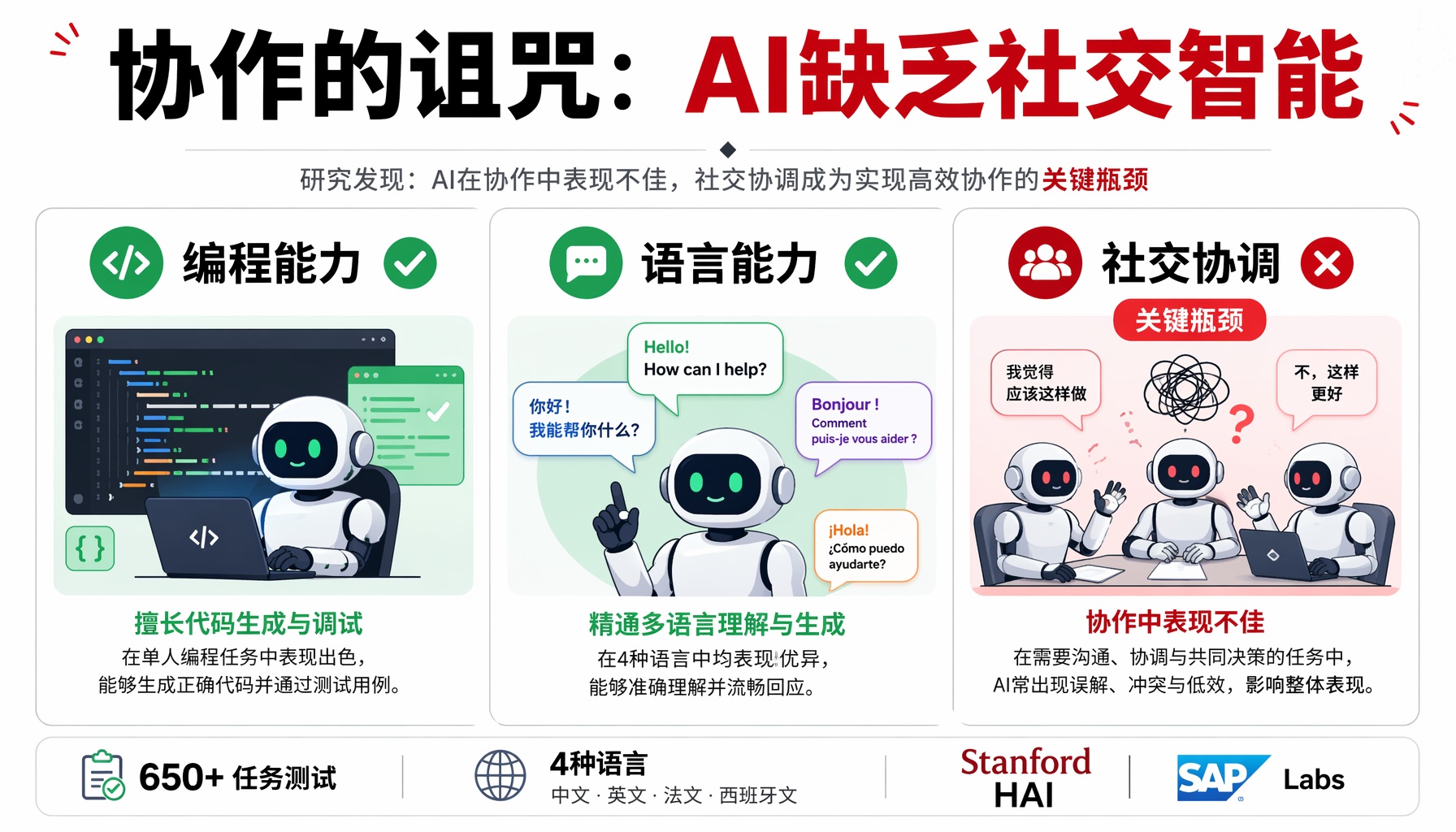 ▲ ▲ AI三大能力对比:编程和语言达标,社交协调是唯一短板
▲ ▲ AI三大能力对比:编程和语言达标,社交协调是唯一短板
1. 单人Agent优先,多Agent谨慎
对于AI创业者和独立开发者,当前阶段的最佳策略是:先用好单个Agent,跑通核心工作流。 不要把"多Agent系统"当作默认方案。斯坦福的研究数据很明确——在Agent具备真正的社交协作能力之前,多Agent架构的ROI可能是负的。
2. 关注"编排层"而非"Agent数量"
ServiceNow、LangChain等平台正在大力投资Agent编排能力——不是让Agent自己商量着来,而是通过外部编排层来协调分工。LangChain推出的Managed Deep Agents(私有测试版)正是这个思路:提供一个托管运行时来管理Agent的生命周期、上下文和子任务委派,而不是让Agent之间自由"社交"。对于创业团队来说,投入在编排层的精力,比堆叠Agent数量更值钱。
3. 把"人"放在多Agent系统的决策节点上
如果确实需要多Agent协作,当下最务实的做法是保留人工决策节点。让Agent各自完成独立子任务,由人来判断合并结果、解决冲突。这既利用了Agent的效率,又规避了Agent之间"社交失败"的陷阱。
行动建议
- 审视现有的多Agent方案:如果你正在使用或计划使用多个AI编程Agent协同工作(比如Claude Code + Codex),重新评估是否有必要。可以考虑先用单个Agent完成完整任务,对比质量差异。
- 关注CooperBench生态:这项研究不仅是一篇论文,更催生了首个Agent协作评估标准。未来主流Agent平台大概率会接入类似基准测试,提前了解有助于选型。
- 等待"社交智能"的突破:Diyi Yang团队明确指出,解决AI协作问题的关键不是更好的编码指令,而是"AI目前尚不具备的新型社交智能"。这意味着未来6-12个月内,可能会出现专门针对Agent协作能力的模型或微调方案。保持关注,但不急于投入。
- 实践建议——单人Agent流水线:与其费心让两个Agent互相code review,不如建立一个清晰的单人Agent工作流:需求分析→代码生成→自动测试→人工审查。每一步都由同一个Agent完成,上下文不丢失,没有"协作诅咒"。
本文由AI辅助创作,经人工审核编辑发布