
小米AI团队今日开源MiMo Code——一个能跑数百步不"失忆"的终端编程Agent,基于OpenCode构建,MIT协议,上线几小时GitHub星标即破2900。
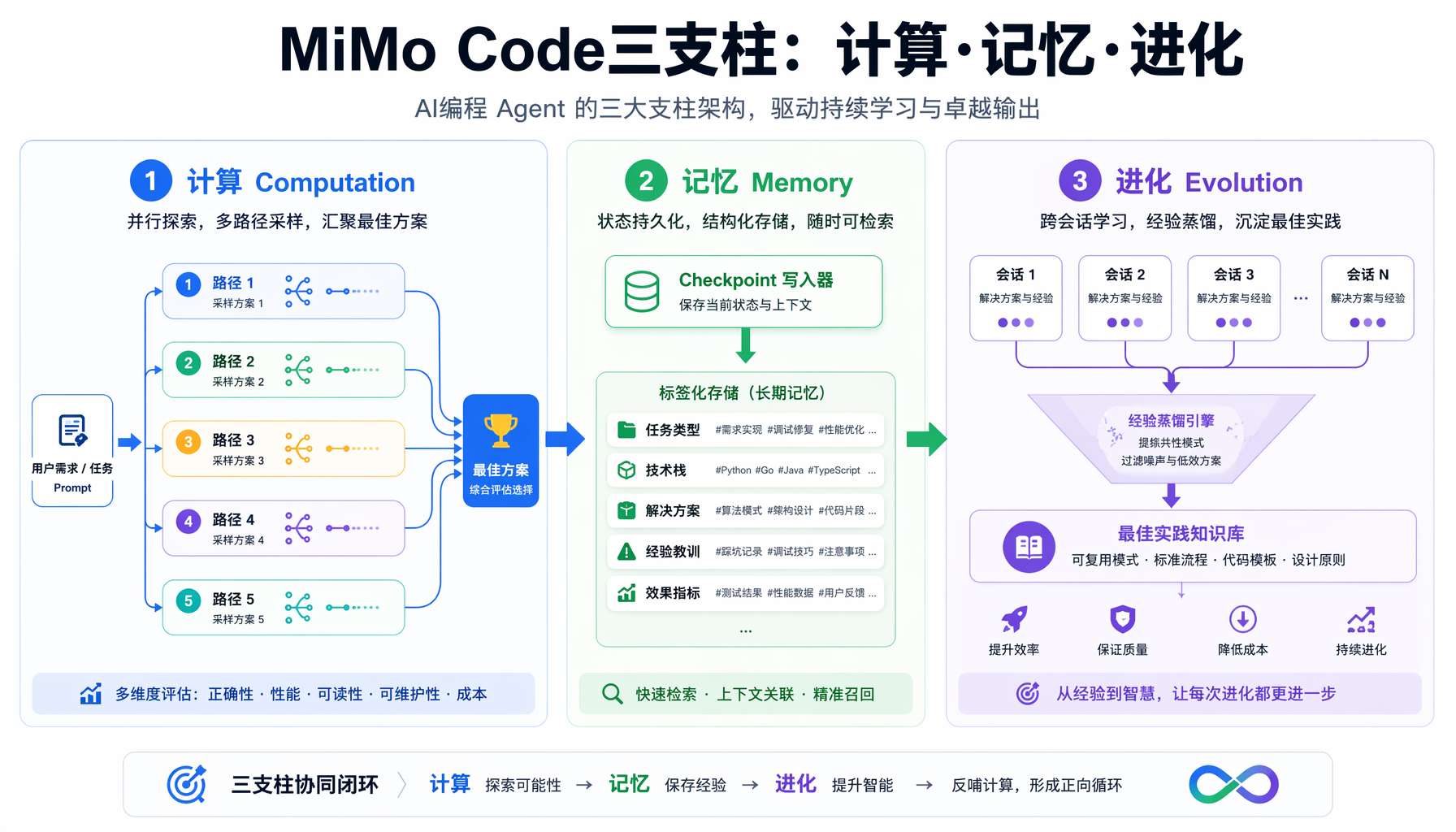 ▲ MiMo Code三支柱架构:计算·记忆·进化
▲ MiMo Code三支柱架构:计算·记忆·进化
事件回顾
2026年6月11日,小米MiMo团队正式开源了MiMo Code V0.1.0——一个终端原生的AI编程Agent,基于开源项目OpenCode构建,采用MIT许可证发布。上线数小时内,该项目在GitHub获得超过2900颗星标,在Hacker News上冲上热榜前三(324 points)。
这不是小米第一次在AI编程领域出牌。此前MiMo已经推出了MiMo-V2.5系列模型(1万亿参数MoE架构,1M token上下文窗口),但MiMo Code的意义完全不同:它不是一个模型,而是一个完整的编程Agent系统。
MiMo Code的核心设计围绕三个支柱:计算(Computation)、记忆(Memory)、进化(Evolution)。这三个词精准对应了当前AI编程工具的三大痛点——单步决策质量差、长任务丢失上下文、跨会话无法积累经验。
在权威基准测试SWE-Bench Pro上,MiMo Code使用相同基础模型跑出62%的成绩,比Claude Code高出5个百分点。在Terminal-Bench 2上更是达到73%。这组数据直接挑战了"Claude Code是终端编程Agent之王"的行业共识。
为什么重要
1. "长程记忆"直击行业最大痛点
用过Claude Code或Codex CLI的开发者都有这个体验:前10个回合AI表现惊艳,30个回合后开始忘事,50个回合后完全不可用。根因很简单——所有对话历史堆在context window里,超出窗口就截断,长任务的"尾部"决策质量断崖式下降。
MiMo Code的解决方案是checkpoint写入器:在context window被填满之前,主动将结构化状态写入选定的持久化存储结构。需要时再显式召回。这解决了传统"摘要压缩"方案的根本缺陷——摘要不可回溯查询,而checkpoint可以。
用大白话说:Claude Code像是让AI边干活边记笔记但只能记在一张纸上,纸写满了前面的就丢了;MiMo Code像是给了AI一个带标签的笔记本,该存档时存档、该翻查时翻查。
2. "五路并行采样"重新定义决策质量
MiMo Code的Max Mode是一个颇具野心的功能:在每一个决策回合,同时跑5条独立的推理路径(temperature=1保证多样性),然后用同一模型的低温度版本做裁判,选出最佳方案执行。
在SWE-Bench Pro上,Max Mode比单次采样提升10-20%的性能。代价是4-5倍的token消耗——但换来了更可靠的单步决策。对于自动化执行场景(没有人类在旁边纠错),这个trade-off非常合理。
3. 小米用MIT协议打入AI工具生态
MIT协议意味着任何公司和个人都可以fork代码、修改、商用,几乎没有限制。OpenAI的Codex CLI虽然也开源,但绑定了OpenAI自家模型生态;Claude Code干脆不开源。MiMo Code支持接入DeepSeek、Kimi、GLM等多家模型API——工具层开放+模型层自由选择,这是一个完全不同的竞争姿势。
小米此举的战略意图非常清晰:靠开源工具层抢占开发者入口,靠MiMo-V2.5模型(限时免费)培养用户习惯,最终构建"硬件(小米设备)+ 模型(MiMo系列)+ 工具(MiMo Code)"的完整AI生态链。
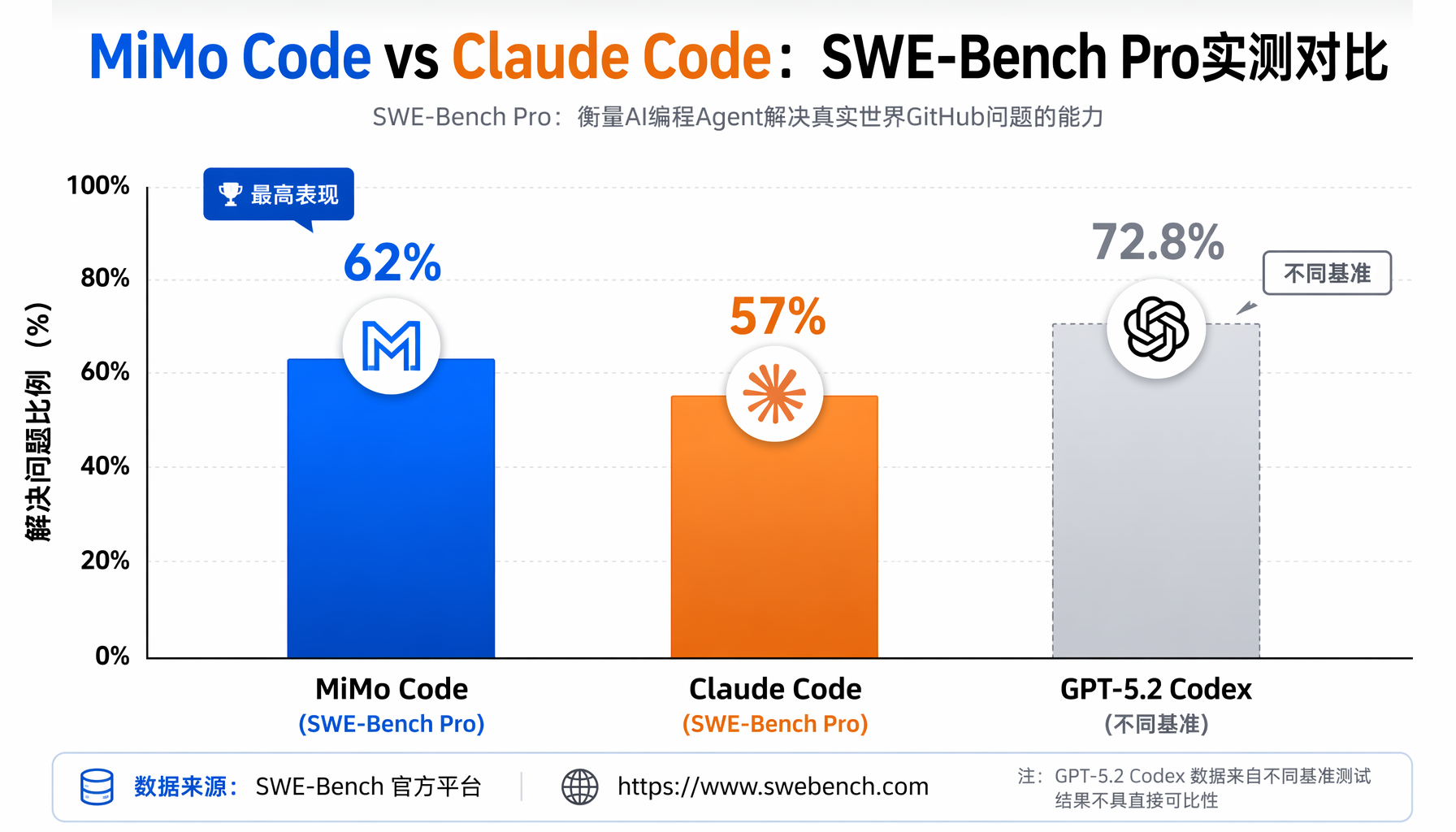 ▲ SWE-Bench Pro实测对比:MiMo Code 62% vs Claude Code 57%
▲ SWE-Bench Pro实测对比:MiMo Code 62% vs Claude Code 57%
我们能学到什么
1. AI编程工具赛道的竞争逻辑正在转变
2025年之前,AI编程工具的竞争逻辑是"谁的模型更强"。Cursor绑GPT、Claude Code绑Claude,工具本质上是模型的"分发渠道"。2026年这半年出现了根本性变化:工具层的工程能力正在和模型层的推理能力同等重要。
OpenCode作为开源基础设施,让任何团队都能快速构建终端Agent(Hermes Agent的终端模式也是类似思路)。MiMo Code的成功证明:即使不用最强模型,通过并行采样、状态管理、跨会话学习这些工程手段,一样可以做出有竞争力的编程Agent。
这对AI创业者意味着:"模型-工具"之间的价值链正在重新分配。不一定要自研模型才能在AI工具赛道立足,工具层的独特工程能力本身就是护城河。
2. "记忆"是下一阶段Agent竞争的主战场
从Claude Code的Agent Skills到Hermes Agent的Memory系统,再到MiMo Code的Checkpoint写入器——2026年上半年的Agent军备竞赛正在聚焦于同一个能力:如何让Agent记住更多、更久、更结构化。
这不是巧合。当一个Agent能稳定运行10步时,"记忆"不是瓶颈。但当Agent需要跑100步、处理百万行代码时,状态管理就不再是锦上添花,而是生存必须。
3. 中国大厂的AI开源策略正在升级
从DeepSeek开源模型、到阿里开源Qwen系列、再到小米开源MiMo Code工具——中国AI公司的开源策略正在从"开源模型换口碑"升级为"开源工具层抢入口"。工具层的网络效应(用户越多、反馈越多、越难迁移)远强于模型层。
行动建议
- 如果你在用Claude Code或Codex CLI:花20分钟试用MiMo Code。一行命令安装(macOS/Linux:
curl -fsSL mimo.xiaomi.com/install | bash),跑一个你熟悉的终端编程任务对比体验。重点关注长任务(>20步)下的上下文保持能力。 - 如果你是AI工具创业者:仔细阅读MiMo Code的官方技术博客(mimo.xiaomi.com/blog/mimo-code-long-horizon)。"计算-记忆-进化"三层架构是当前Agent设计的通用范式,它的并行采样(Max Mode)和checkpoint机制可以直接借鉴。
- 如果你在选型AI编程工具:不要只看SWE-Bench分数。MiMo Code的62% vs Claude Code的57%——5个百分点差距可能不如"是否支持你常用的模型API"重要。优先选择兼容你技术栈的工具。
- 关注长程Agent的基础设施机会:当编程Agent能稳定跑数百步时,会产生新的需求——Agent状态的可观测性、checkpoint的版本管理、多Agent协作时的共享记忆。这些都是2026年下半年的创业机会。
*参考来源:小米MiMo官方博客、GitHub XiaomiMiMo/MiMo-Code、KuCoin新闻报道、Gizmochina报道、HN讨论(2026年6月11日)*
本文由AI辅助创作,经人工审核编辑发布