
Hermes Agent 的 Learning Loop 不是概念——它能从每次执行中沉淀 Skill,自主迭代优化。本文手把手教你搭建一个"会自我进化"的 AI 监控机器人。
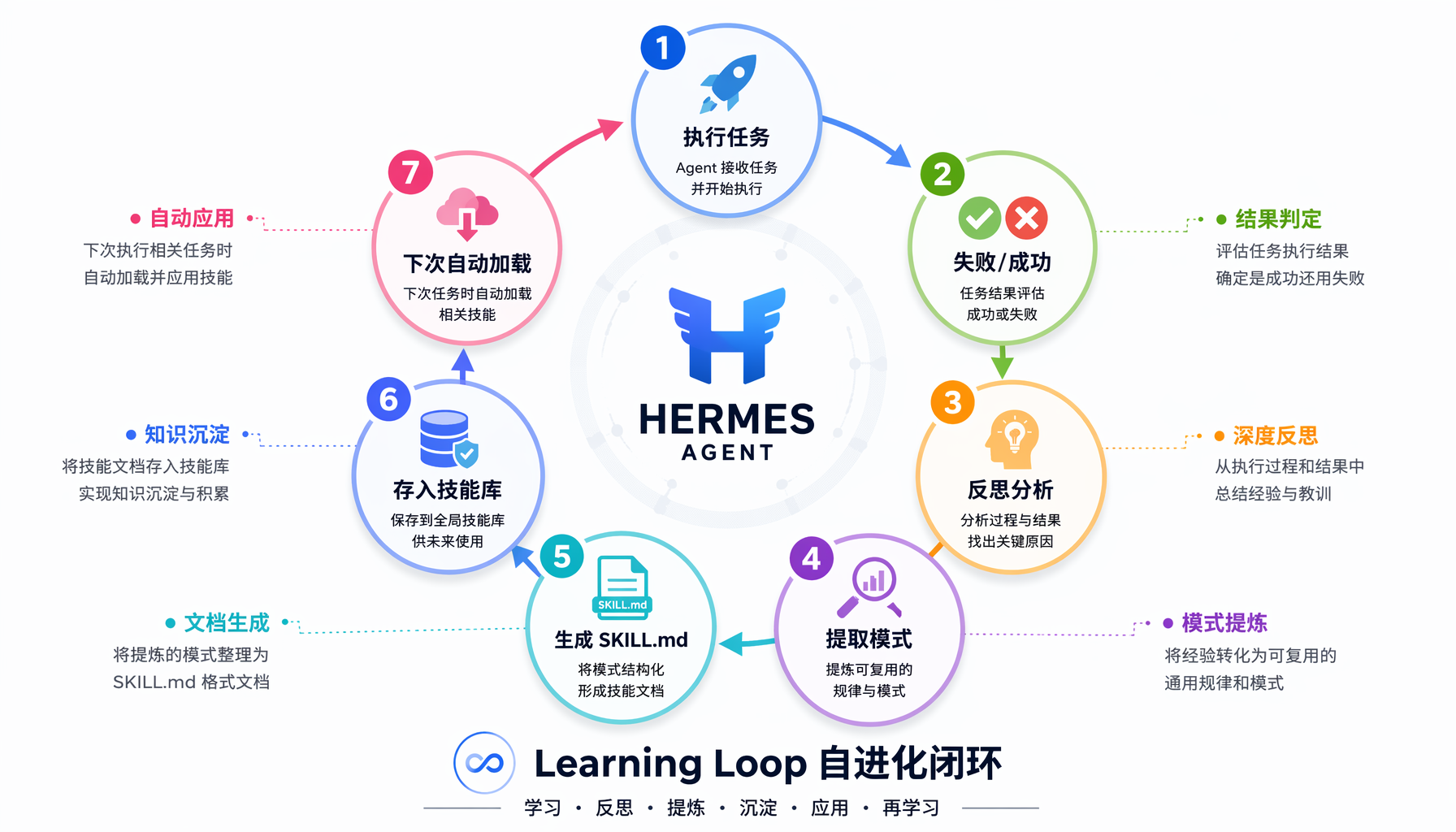 ▲ ▲ Hermes Agent 自进化 Learning Loop 七步闭环流程图:从执行到反思再到知识沉淀
▲ ▲ Hermes Agent 自进化 Learning Loop 七步闭环流程图:从执行到反思再到知识沉淀
为什么传统 Cron + AI 方案会失效?
大多数 AI Agent 的定时任务长这样:设一个 cron → 到点执行 → 输出结果 → 下次执行时从零开始。Agent 不记得上次做了什么决策,也不知道什么数据是重要的。
类比一下:你雇了一个实习生每天早上帮你看竞品动态,但他每天上班都像第一天——不认识你、不记得昨天发生了什么、同样的错误反复犯。
Hermes Agent 的 Cron + Skill 组合改变了这个范式。它允许 Agent 在执行定时任务的过程中,将成功经验沉淀为 Skill,下次直接复用。
参考自 Hermes Agent 官方文档(Skills 系统 & Cron 指南,2026年6月)。
核心机制:Learning Loop 七步闭环
在深入代码之前,先理解 Hermes 的自进化引擎是如何工作的。根据 Nous Research 的架构设计,完整的 Learning Loop 包含七个阶段:
关键差异:其他 Agent(如 OpenClaw、Claude Code)也支持 Skill,但都是静态的——需要人手工编写。Hermes 的 Agent 可以自己写 Skill、自己改 Skill。
参考自腾讯新闻深度解析《Hermes Agent 如何实现"自进化"》,2026年4月。
实战:搭建一个自进化的竞品监控机器人
目标
创建一个 cron 任务,每 2 小时自动搜索 AI 竞品动态,Agent 分析后沉淀为结构化的 Skill,下次执行时直接加载已有知识库,避免重复搜索。
第一步:安装 Hermes Agent(30秒)
踩坑提醒:如果 hermes 命令找不到,先执行 source ~/.bashrc。Windows 用户推荐用 WSL2,原生 PowerShell 版本仍为早期测试版,部分工具可能不可用。
第二步:创建监控脚本
在 ~/.hermes/scripts/ 下创建一个 Python 脚本,负责"机械性"的数据采集:
第三步:注册 Cron 任务
在 Hermes CLI 中执行(支持自然语言):
输出示例(第一次执行):
第二次执行(2小时后):
这就是自进化的核心——Agent 不会重复搜索相同的信息,而是在已有知识基础上增量更新。
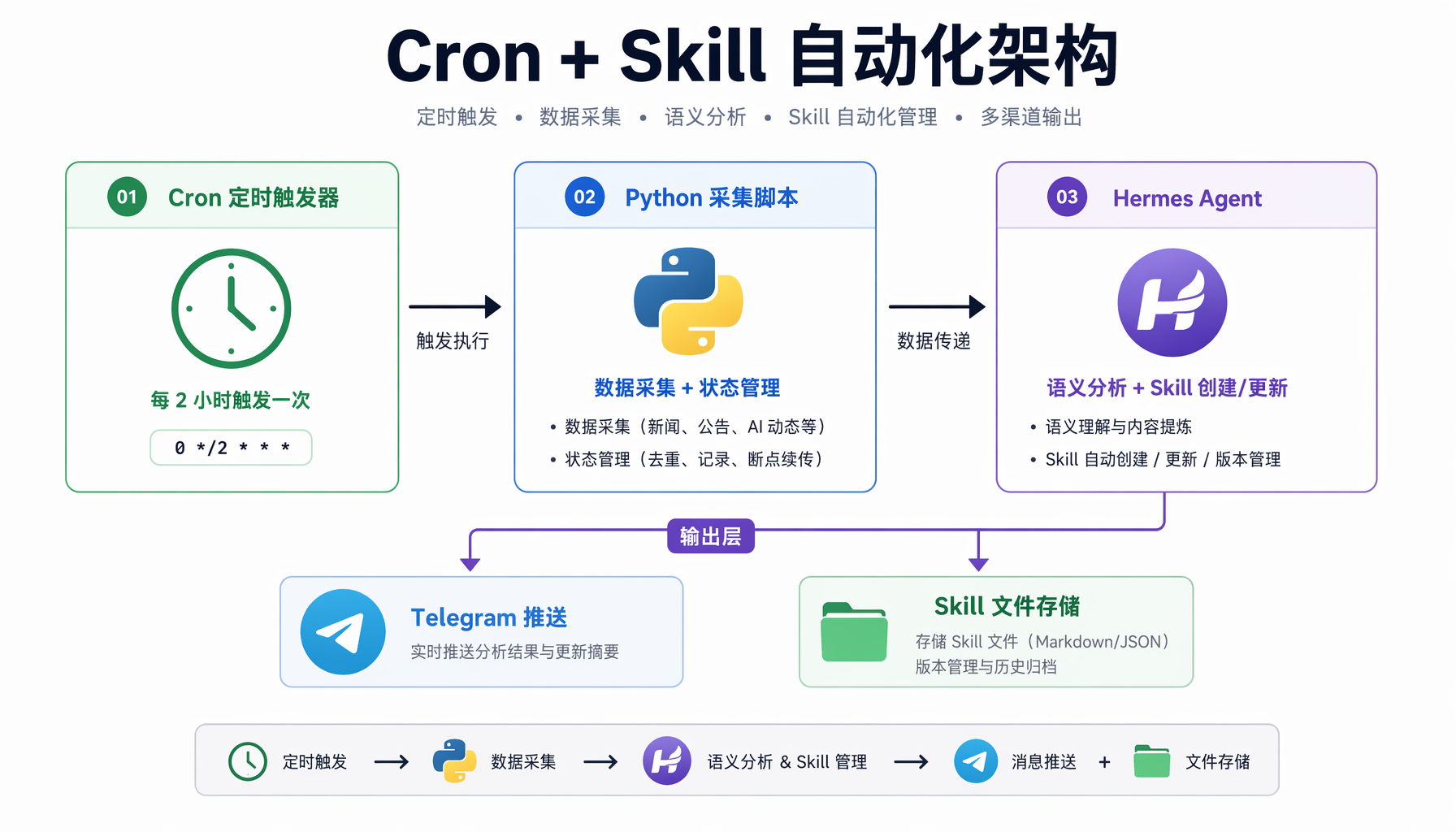 ▲ ▲ Cron + Skill 自动化架构:数据采集脚本→Agent语义分析→Skill知识沉淀
▲ ▲ Cron + Skill 自动化架构:数据采集脚本→Agent语义分析→Skill知识沉淀
第四步:验证 Skill 是否生效
踩坑提醒:Skill 文件必须放在 ~/.hermes/skills/ 目录下才能被自动发现。如果是外部目录,需要在 hermes config 中配置 skill_extra_dirs。
为什么这个模式对一人公司特别重要?
1. 知识资产化
每次 Agent 执行 = 一次知识沉淀。30 天后你拥有的是 360 个 Skill 文件组成的结构化知识库——而不是 360 条散落在聊天记录里的消息。
2. 降本增效
第 1 次搜索:Agent 需要搜索 10 个来源 → 提取 → 分析 → 写 Skill(消耗约 5000 tokens) 第 10 次搜索:Agent 加载已有 Skill(消耗约 500 tokens)→ 只搜索增量 → 仅更新变化部分
Token 消耗下降 90%,信息质量反而上升——因为 Agent 越来越懂你的业务。
3. 真正的 24 小时值守
传统方案:你睡前设一个提醒 → 醒来检查 → 手动分析 Hermes 方案:Agent 在你睡觉时完成 6 轮监控 → 沉淀 3 个新 Skill → Telegram 推送摘要
参考自 MindStudio 博客《How to Build a Cron-Based AI Automation with Hermes Agent》,2026年。
高级模式:脚本 + Agent 的分工哲学
Hermes Cron 的核心设计理念是脚本做机械活,Agent 做判断活:
| 角色 | 负责 | 工具 |
|---|---|---|
| Python 脚本 | 数据采集、哈希对比、状态管理 | urllib.request、hashlib、json |
| Hermes Agent | 语义判断、信息分类、Skill 创建 | web_search、write_file、patch |
为什么这样分工? 让 LLM 去做 hashlib.sha256() 是浪费 tokens——而且 LLM 的"哈希"可能是幻觉。机械计算交给确定性脚本,语义推理交给 Agent,各司其职。
示例:网站监控脚本计算 SHA256,Agent 收到 "CHANGE DETECTED" 后判断"这个变化是否值得通知你"——而不是把所有变化都推给你。
参考自 Hermes Agent 官方文档《Automate Anything with Cron》,Pattern 1: Website Change Monitor。
踩坑清单(实测经验)
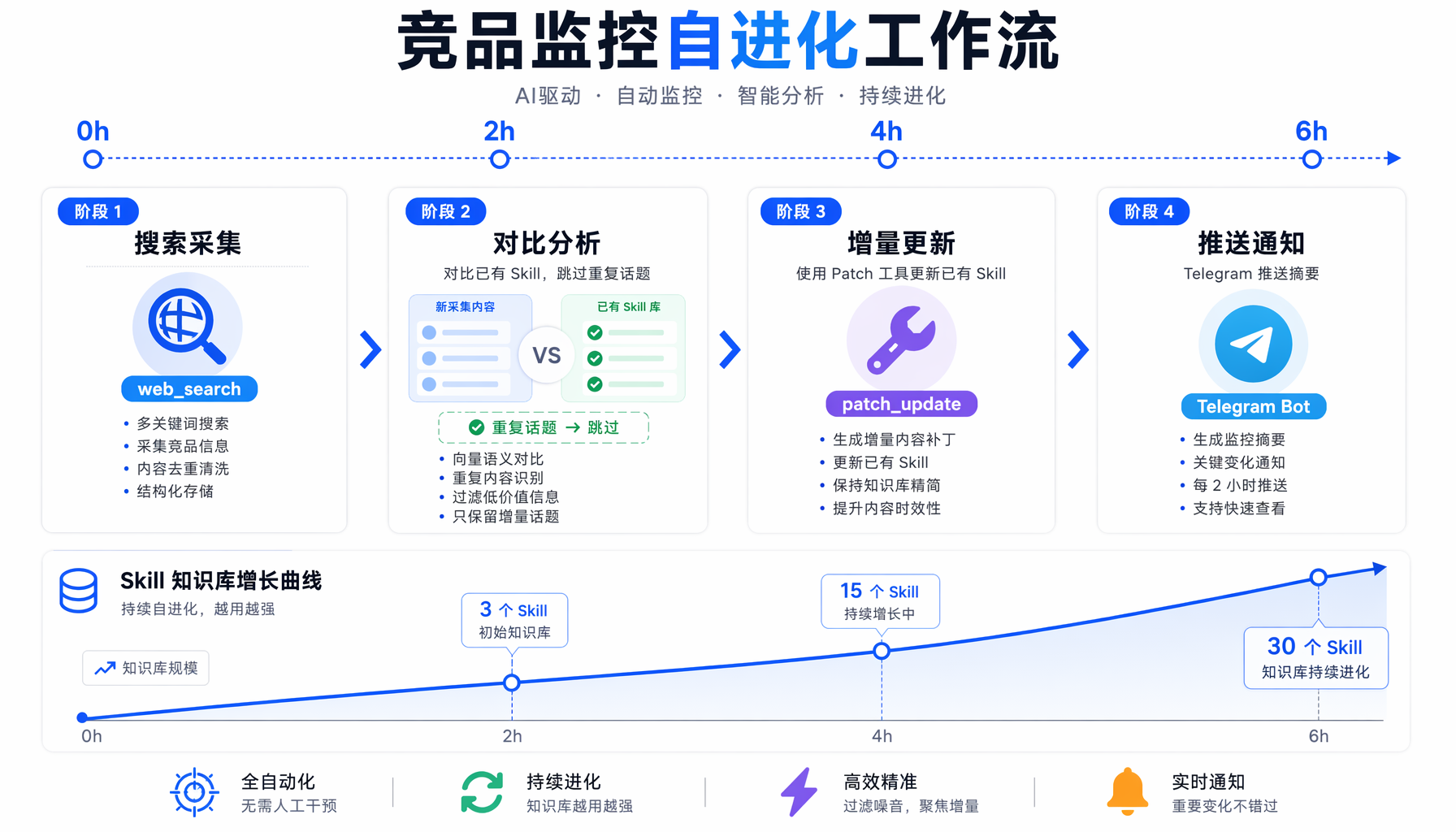 ▲ ▲ AI竞品监控机器人完整工作流:搜索采集→对比已有Skill→增量更新→推送通知
▲ ▲ AI竞品监控机器人完整工作流:搜索采集→对比已有Skill→增量更新→推送通知
坑1:Cron Agent 无记忆,Prompt 必须自包含
Cron 任务每次在全新会话中执行——Agent 不记得你上次说了什么。所有上下文必须通过 --script 参数传入的 Python 脚本 stdout 提供。
错误示例:
正确示例:
坑2:Skill 文件被覆盖
多个 Cron 任务可能同时修改同一个 Skill 文件。解决方案:
- 每个 Cron 任务操作不同的 Skill 命名空间(如
competitor-、pricing-、traffic-) - 用
patch工具做增量编辑而非write_file全量覆盖
坑3:[SILENT] 的正确用法
当 Cron 任务的最终回复只有 [SILENT](且没有其他内容)时,消息投递被抑制。中间步骤的输出不受影响——只有 final response 会触发沉默规则。
坑4:国内网络下的 API 访问
如果使用 Tavily 搜索 API(web_search 默认后端),国内服务器可能遇到 432 配额错误或连接超时。解决方案:
- 使用博查(Bocha)作为搜索后端:
hermes config set web.backend bocha - 或使用 Kimi 大模型(国内可直接访问)
行动建议:30 分钟搭建你的第一个自进化 Agent
- 安装 Hermes(5 分钟):复制上面的 curl 命令
- 选择监控目标(5 分钟):竞品动态?价格变化?GitHub Star 数?选一个你最需要的信息源
- 写采集脚本(10 分钟):用上面的模板,修改 URL 和数据提取逻辑
- 注册 Cron(5 分钟):用自然语言描述任务
- 验证(5 分钟):等第一轮执行完成,检查 Skill 是否正确生成
推荐起步场景(从简单到复杂):
- 入门:监控一个竞品 GitHub 仓库的 Release(参考 Pattern 3)
- 进阶:监控 3 个数据源 + 自动分类 + 创建 Skill
- 高级:多 Agent 协作——监控 Agent 采集 → 分析 Agent 写日报 → 分发 Agent 推送到各平台
常见问题(FAQ)
Q:Skill 会被 Agent "污染"吗?如果 Agent 写了一篇错误信息的 Skill,怎么恢复?
A:Skill 文件就是普通 Markdown 文件,存在 ~/.hermes/skills/ 目录下。如果 Agent 创建了错误 Skill,直接 rm 删除即可。建议每周人工抽查一次 Skill 质量——虽然 Agent 的自进化能力很强,但关键知识资产仍需人工复核。
Q:Cron 任务失败了会通知我吗?
A:Hermes 支持 --notify-on-failure 参数。如果 Agent 执行过程中抛出异常(如 API 超时、工具调用失败),会通过配置的 delivery channel(Telegram/Discord 等)推送失败通知。
Q:我的 Cron 任务在"睡觉"——它真的在运行吗?
A:用 hermes cron list 查看所有定时任务及其最后执行时间。如果状态显示 paused,用 hermes cron resume 恢复。另外确保 Gateway 进程在运行:hermes gateway status。
Q:一个 Skill 文件能多大?会不会塞爆 Context Window?
A:Hermes 使用渐进式披露(Progressive Disclosure)机制:
- Level 0:只加载 Skill 名称和描述(约 100 tokens/Skill)
- Level 1:Agent 判断需要时才加载完整 Skill 内容
- Level 2:甚至可以只加载 Skill 中的某个参考文件
所以即使有 100 个 Skill,日常对话也只消耗 Level 0 的 token 量——约 3K tokens。只有需要时才按需加载。
风险提示
- Hermes Agent 的 Self-Evolving Skills 系统仍在快速迭代中(当前版本为 2026年6月),API 可能变化。建议关注 GitHub Releases 页面获取最新变更日志。
- Skill 自动生成的准确性取决于底层大模型的能力。用小模型(如 8B 参数级)运行自进化任务时,Skill 质量可能不稳定,推荐使用 Claude 4 系列或 GPT-5 级模型。
- 国内用户如果使用 OpenAI/Anthropic 模型,需要稳定的 API 代理,否则 Cron 任务可能因网络问题静默失败。推荐使用国产模型(Kimi、DeepSeek、智谱)作为替代,无需特殊网络配置。
#AI创业 #Agent工坊 #HermesAgent #自动化 #一人公司
本文由AI辅助创作,经人工审核编辑发布