
5月28日Anthropic发布Opus 4.8,距GPT-5.5仅5周。两周后的今天,独立评测数据终于让这场"谁是最强编程Agent"的争论有了答案——但答案不是"谁赢",而是"谁适合什么活"。
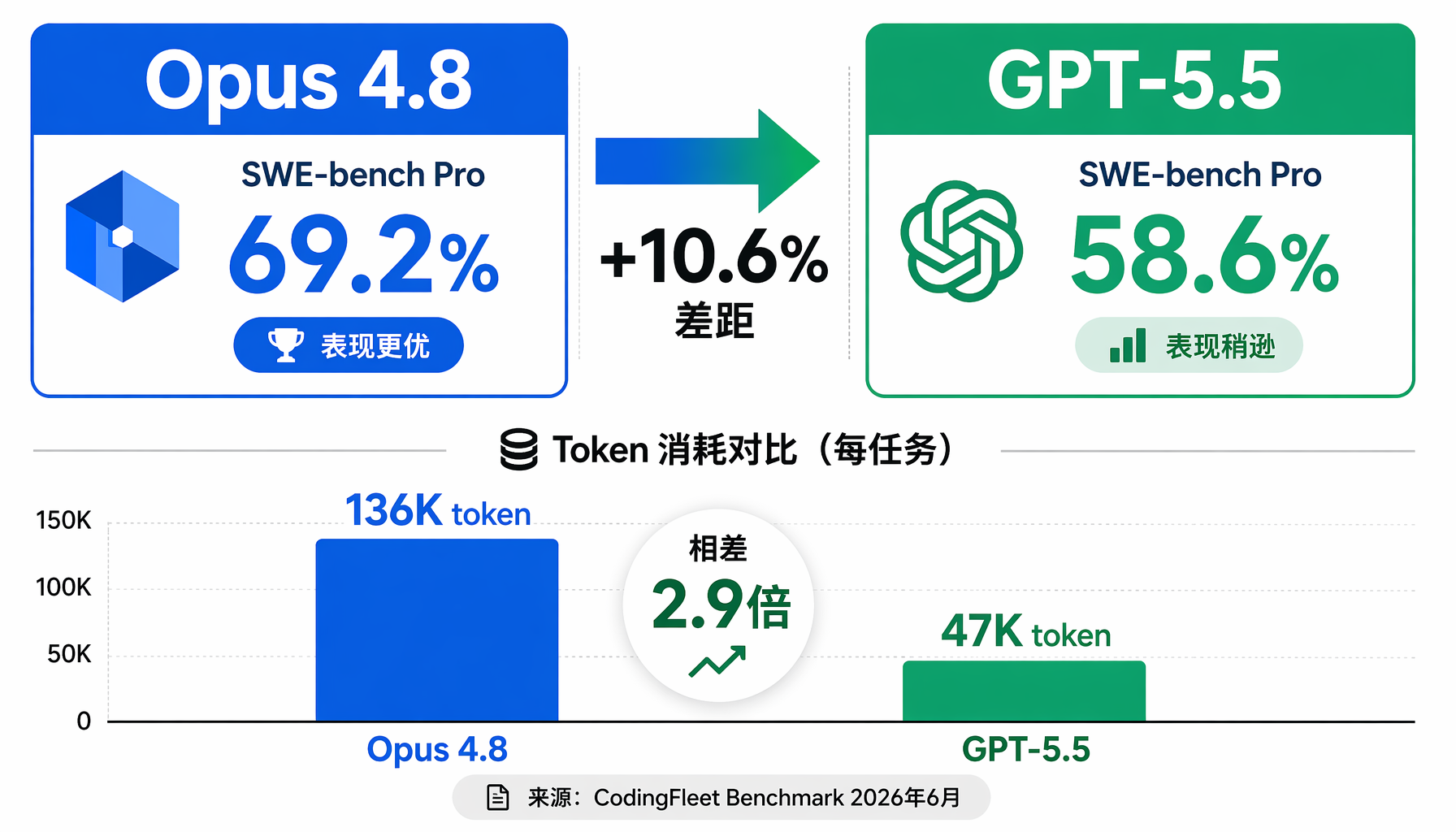 ▲ ▲ Opus 4.8 vs GPT-5.5 编程基准对比:SWE-bench Pro差距10.6%,但Token消耗差2.9倍
▲ ▲ Opus 4.8 vs GPT-5.5 编程基准对比:SWE-bench Pro差距10.6%,但Token消耗差2.9倍
事件回顾
2026年5月28日,Anthropic发布了Claude Opus 4.8,距上一代Opus 4.7仅42天——这是Opus系列史上最快迭代。而就在5周前的4月23日,OpenAI才刚刚放出GPT-5.5。两家公司不约而同地把发布节奏压缩到了6周左右,比拼的不再是单次性能,而是谁能更快锁定企业采购窗口。
两周来,独立评测机构、开发者社区和基准测试平台陆续放出对比数据。6月6日,CodingFleet发布了迄今为止最全面的Opus 4.8 vs GPT-5.5编程基准对比,涵盖SWE-bench Pro、DeepSWE、终端操作、代码审查等8个维度。
核心数据:谁在什么场景赢
在软件工程基准SWE-bench Verified上,Opus 4.8斩获88.6%,GPT-5.5约82.6%。更难的SWE-bench Pro差距拉到10.6个百分点(69.2% vs 58.6%)。Opus在「自己读代码库→定位bug→写补丁→跑测试」这种完整Agent循环中表现出色。
但切换到DeepSWE——一个由第三方设计的更难的软件工程测试——格局反转:GPT-5.5拿到70%,Opus 4.8只有58%。DeepSWE的任务更难、代码库更大、需要更多判断而非简单定位。这说明GPT-5.5在复杂推理任务上仍有优势。
终端操作和CLI工作流方面,GPT-5.5保持领先,尤其在网络安全和DevOps场景。但在长文档处理上,Opus 4.8「碾压了两者」(评测者原话),能够连贯处理超长代码库和文档。
在AI Analysis综合指数上,Opus 4.8以61.4分微弱领先GPT-5.5的60.2分——差距不到2%,几乎可以忽略。
代价:Token消耗的巨大差异
Opus 4.8的一个醒目特征:它非常"话多"。在DeepSWE测试中,Opus每个任务平均生成136,000个token,GPT-5.5只生成47,000个——差了2.9倍。在SWE-bench Pro中,Opus的输出量同样是GPT-5.5的近3倍。
这意味着什么?Opus 4.8通过"多思考、多输出"的策略取得了更高的成功率,但API成本也随之飙升。以Opus的定价(输出$25/百万token)计算,每个SWE-bench Pro任务仅输出token就要$3.4,加上输入成本可能超过$5。GPT-5.5(输出$30/百万token)虽然单价更贵,但因为输出少得多,每个任务成本反而可能更低。
 ▲ ▲ 模型诚实度对比:Opus 4.8幻觉率35.9% vs GPT-5.5幻觉率86%,编程场景下这个差异很关键
▲ ▲ 模型诚实度对比:Opus 4.8幻觉率35.9% vs GPT-5.5幻觉率86%,编程场景下这个差异很关键
对AI创业者的意义
如果你在用AI编程Agent做产品开发,这次对决给了三个明确的信号:
第一,不存在"全能冠军"。 Opus擅长完整Agent循环(自己找文件、读懂代码、写补丁),GPT-5.5擅长复杂推理和终端操作。选工具要看场景,不是看总分。
第二,成本结构在变。 Opus的"多输出"策略意味着你不仅要看API单价,更要看实际任务消耗。一个任务$5和$1.5的差距,在日跑100个任务的开发流程中就是$350/天的差异。
第三,竞争在加速。 6周一个版本的迭代节奏意味着你今天的选型可能下个月就过时。建议不要深度绑定单一平台,保持工具栈的灵活性。
容易被忽略的关键指标:诚实度
在这场编程能力的讨论中,有个数据被大多数人忽略了——模型幻觉率。根据Artificial Analysis的评测,Opus 4.8的幻觉率只有35.9%,而GPT-5.5高达86%。这意味着GPT-5.5在不确定时更倾向于"编造"一个看起来合理的答案,而Opus更倾向于承认不知道。
对于编程场景,这个差异非常关键。一个能诚实告诉你"这个我不确定"的AI编程助手,比一个自信满满但可能写出有bug代码的助手,长期来看更值得信赖。尤其是在你不熟悉的语言或框架中,你很难一眼看出AI写的代码有没有问题。
行动建议
- 做自己的基准测试。通用benchmark只是参考。花一个下午,用Opus 4.8和GPT-5.5各跑5个你实际项目中的任务,记录成功率、耗时和cost。这才是最真实的对比。测试时务必包含你不熟悉的代码库,这才能测出幻觉率对你的实际影响。
- 按场景选模型,不追求"全能冠军"。修复bug、重构代码、跨文件追踪依赖→用Opus 4.8。DevOps脚本、数据库操作、终端命令→用GPT-5.5。两个都接进你的IDE(Claude Code和Codex CLI可以共存),按需切换。
- 算账不要只看单价。Opus输出单价$25/百万token看似比GPT-5.5的$30便宜,但它输出量是后者3倍。先跑10个任务看实际消耗再决策,别被定价页面误导。
- 关注6月新模型窗口。Gemini 3.5 Pro和Claude Sonnet 4.8预计本月发布,Qwen 3.7 Max也在追赶。AI编程工具的竞争远未结束,保持工具栈的灵活性比押注单一平台更安全。
本文由AI辅助创作,经人工审核编辑发布