
Anthropic在2026年6月的Code with Claude大会上正式发布了多Agent工作流编排能力——你现在可以让多个Claude子Agent并行处理代码审查、安全扫描和测试生成,而只需一条
/workflows命令。本文手把手带你从零搭建一套可复用的一人公司自动化流水线。
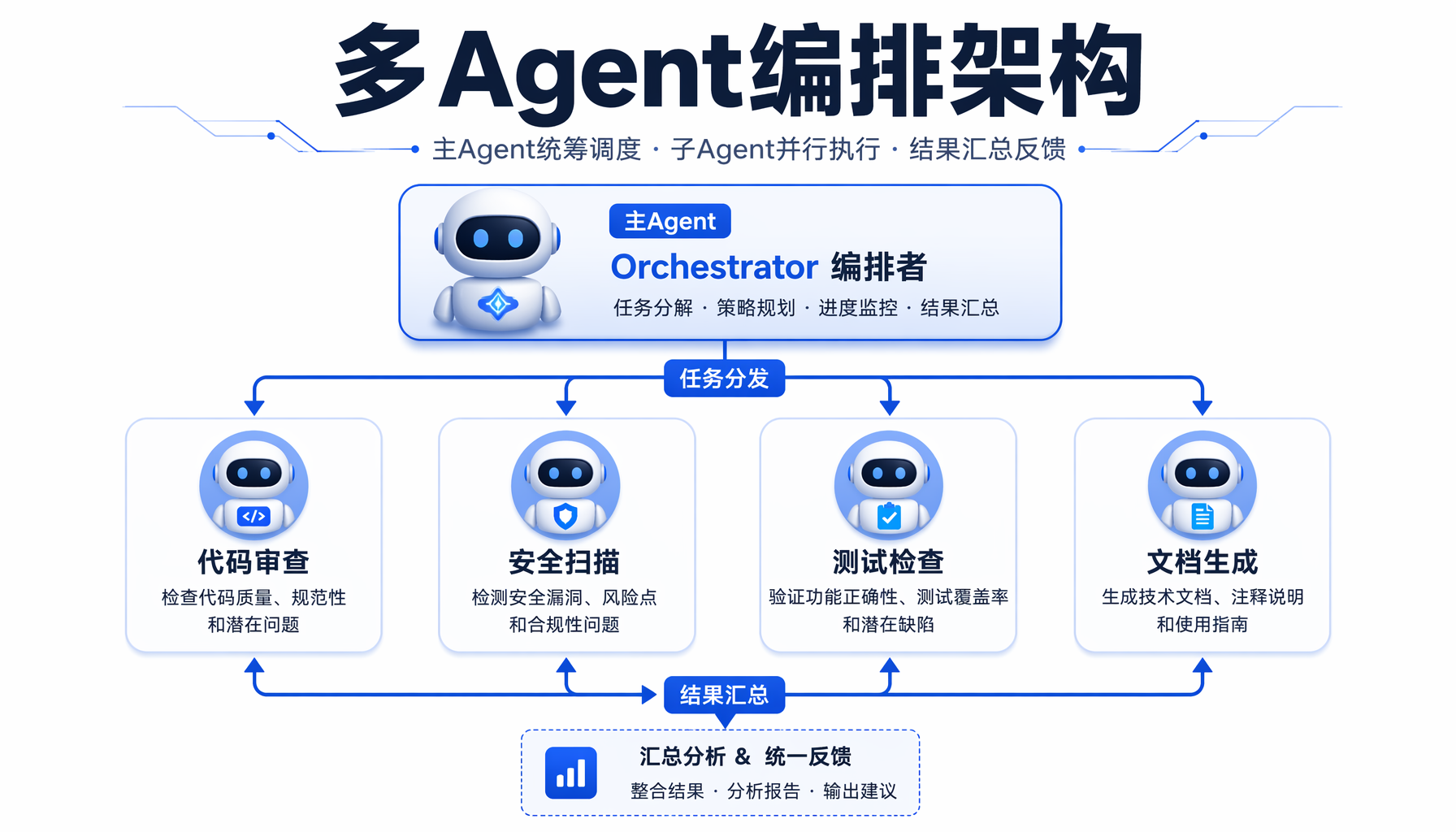 ▲ ▲ 多Agent编排架构:一个Orchestrator协调四个子Agent并行执行代码审查、安全扫描、测试检查和文档生成
▲ ▲ 多Agent编排架构:一个Orchestrator协调四个子Agent并行执行代码审查、安全扫描、测试检查和文档生成
背景:为什么一人公司需要多Agent
2026年的AI编程工具已经不再是"帮你写一个函数"的水平了。Claude Code作为Anthropic的终端级Agent编程助手,在2026年6月的Code with Claude大会上推出了三个重磅能力:Managed Agents(托管Agent)、Proactive Workflows(主动工作流)和Capability Curve(能力曲线)。其中最值得一人公司创业者关注的,就是 /workflows 命令背后的多Agent编排系统。
一人公司面临的核心矛盾是什么?一个人要干五个人的活,但每天只有24小时。 你不只要写代码,还要做代码审查、安全扫描、测试覆盖、文档生成——这些环节任何一个被跳过,产品质量就会打折。传统做法是雇人或外包,但成本动辄每月数万。
多Agent工作流的答案是:把重复性的技术工作拆成独立子任务,让多个AI Agent并行执行,你只做最终决策。 这其实就是把"一人公司"变成"一人+AI团队"。
核心概念:Claude Code的Agent架构
在深入 /workflows 之前,先理解Claude Code的Agent模型:
Orchestrator(编排者)与 Subagent(子Agent)
Claude Code中,Agent有两种角色:
- Orchestrator(编排者):你的主会话Claude。它接收你的指令,拆解任务,分派给子Agent,最后汇总结果。
- Subagent(子Agent):独立执行具体任务的Claude实例。每个子Agent有自己的上下文窗口和工具权限,互不干扰。
自定义Slash命令
Claude Code的斜杠命令有两种来源:
项目级命令:放在 .claude/commands/ 目录下,只在当前项目中可用。
全局命令:放在 ~/.claude/commands/ 目录下,所有项目通用。
命令文件就是普通的Markdown文件(.md),文件名即命令名。例如:
当你输入 /workflows 时,Claude会把 workflows.md 的完整内容注入上下文,作为行为指令执行。
实战一:代码审查三合一流水线
这是最经典的多Agent场景。你提交了一个PR,需要同时做三件事:逻辑审查、安全扫描、测试覆盖检查。三者互不依赖,天然适合并行。
步骤1:创建工作流文件
在你的项目根目录创建 .claude/commands/review.md:
步骤2:使用 /review 命令
在Claude Code会话中:
Claude会自动:
- 读取
review.md的工作流指令 - 创建3个子Agent,分别执行逻辑审查、安全扫描、测试检查
- 并行运行3个子Agent
- 汇总3份输出为最终审查报告
 ▲ ▲ 代码审查三合一流水线:逻辑审查、安全扫描、测试覆盖三个子Agent并行执行后汇总为结构化报告
▲ ▲ 代码审查三合一流水线:逻辑审查、安全扫描、测试覆盖三个子Agent并行执行后汇总为结构化报告
步骤3:实际输出示例
实战二:每日自动化运营流水线
一人公司的日常运营有很多重复环节:检查服务健康状态、抓取竞品动态、生成日报。这些完全可以用 /workflows 自动化。
创建 `.claude/commands/daily-ops.md`:
踩坑提醒
在实测中,有几个容易踩的坑:
- 子Agent上下文限制:每个子Agent有独立的上下文窗口。如果你的代码库很大,子Agent可能看不到完整上下文。解决方案是在工作流指令中明确指定子Agent需要扫描的文件范围。
- 并行执行的工具冲突:如果多个子Agent同时读写同一个文件,会产生竞态条件。解决方案:让每个子Agent输出到独立的临时文件(如
/tmp/review_logic.txt、/tmp/review_security.txt),Orchestrator最后汇总。 - 子Agent权限控制:子Agent默认继承Orchestrator的工具权限。如果你不希望子Agent执行某些操作(如git push),在工作流指令中明确约束。
实战三:部署前的全量检查流水线
发布到生产环境之前,你的checklist可能有十几项。用一条命令搞定它们:
创建 `.claude/commands/pre-deploy.md`:
工作流设计原则
经过多次实践,总结出以下设计原则:
 ▲ ▲ 工作流 vs 传统脚本选择指南:理解什么场景该用AI编排,什么场景传统脚本更高效
▲ ▲ 工作流 vs 传统脚本选择指南:理解什么场景该用AI编排,什么场景传统脚本更高效
1. 任务粒度:一个子Agent只做一件事
不要把"代码审查+安全扫描+测试"塞进一个子Agent。保持每个子Agent职责单一,这样出问题时容易定位。
2. 并行优于串行
如果子任务之间无依赖,全部并行。3个串行任务需要3倍时间,3个并行任务只需要最长那个的时间。
3. 输出格式标准化
在workflow指令中明确要求每个子Agent输出结构化格式(如Markdown表格),方便Orchestrator汇总。不要让Orchestrator去"理解"每个子Agent的自由文本。
4. 失败隔离
一个子Agent失败不应该影响其他子Agent。在工作流指令中加入错误处理逻辑:
5. 成本意识
每个子Agent消耗独立的token配额。一个包含5个子Agent的工作流,token消耗大约是单Agent的3-5倍。对于日常高频任务,建议先评估ROI——如果人工做只需5分钟,用工作流反而增加了token成本。
工作流 vs 传统脚本:什么时候该用哪个
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 固定流程、无例外 | Shell脚本 | 更快、更便宜、可重复 |
| 需要理解和判断 | Claude Code Workflow | AI能处理脚本无法应对的边界情况 |
| 代码审查、安全分析 | Workflow | 需要语义理解,不是正则匹配 |
| 每日数据拉取+格式化 | 脚本 + AI汇总 | 拉数据用脚本,分析用AI |
| 一次性复杂任务 | Workflow | 不值得写脚本,AI直接搞定 |
常见问题
Q: 子Agent能用不同的模型吗?
目前Claude Code的子Agent统一使用当前会话的模型配置。不能给不同子Agent分配不同模型。
Q: 工作流文件可以有多复杂?
Markdown文件没有长度限制,但建议控制在500行以内。太长的指令会消耗大量上下文窗口,反而降低执行质量。如果工作流真的很复杂,拆成多个子工作流串联。
Q: 子Agent能看到我的代码库吗?
默认能看到当前工作目录的文件,但可以通过工作流指令限制文件访问范围。敏感文件建议显式排除。
Q: 工作流能调用外部API吗?
可以。子Agent可以使用curl、HTTP客户端等工具调用外部API。这对于"竞品监控""服务健康检查"等场景非常有用。
Q: 怎么调试失败的工作流?
目前没有专门的调试工具,建议做法是:
- 先单独跑每个子任务的指令,确认单步可执行
- 再组合成工作流
- 让每个子Agent输出详细日志到临时文件
行动建议
- 今天就能做:在你的项目里创建
.claude/commands/目录,写一个简单的双Agent工作流(比如并行lint+测试),体验编排模式。 - 本周可以做:把你日常工作中重复性最高的2-3个环节写成工作流文件。建议从"代码审查三合一"开始,因为这个场景最成熟。
- 本月目标:搭建一套完整的一人公司日常运营工作流——代码审查、部署检查、竞品监控、数据日报——每天早上一句
/daily-ops完成4件事。
#AI创业 #Agent工坊 #ClaudeCode #一人公司 #多Agent工作流
本文由AI辅助创作,经人工审核编辑发布