
过去给你的 AI Agent 接一个返回截图的 MCP 工具,Anthropic 直接甩你一脸 400 错误。OpenClaw 2026.6.5-beta.6 彻底修了这个痛点。更关键的是——它还顺手送你一个 Parallel 搜索引擎和 ClawHub 技能市场。
 ▲ ▲ OpenClaw Beta.6 Materialize Boundary:MCP工具结果在进入Provider前自动转换非text/image类型
▲ ▲ OpenClaw Beta.6 Materialize Boundary:MCP工具结果在进入Provider前自动转换非text/image类型
发生了什么
2026 年 6 月 9 日上午,OpenClaw 释出了 2026.6.5-beta.6。这次更新的 Release Notes 写满了 15,681 个字,涵盖超过 30 个合并请求。我通读了三遍,从中拎出了对 AI 创业者最直接可用的三个功能。
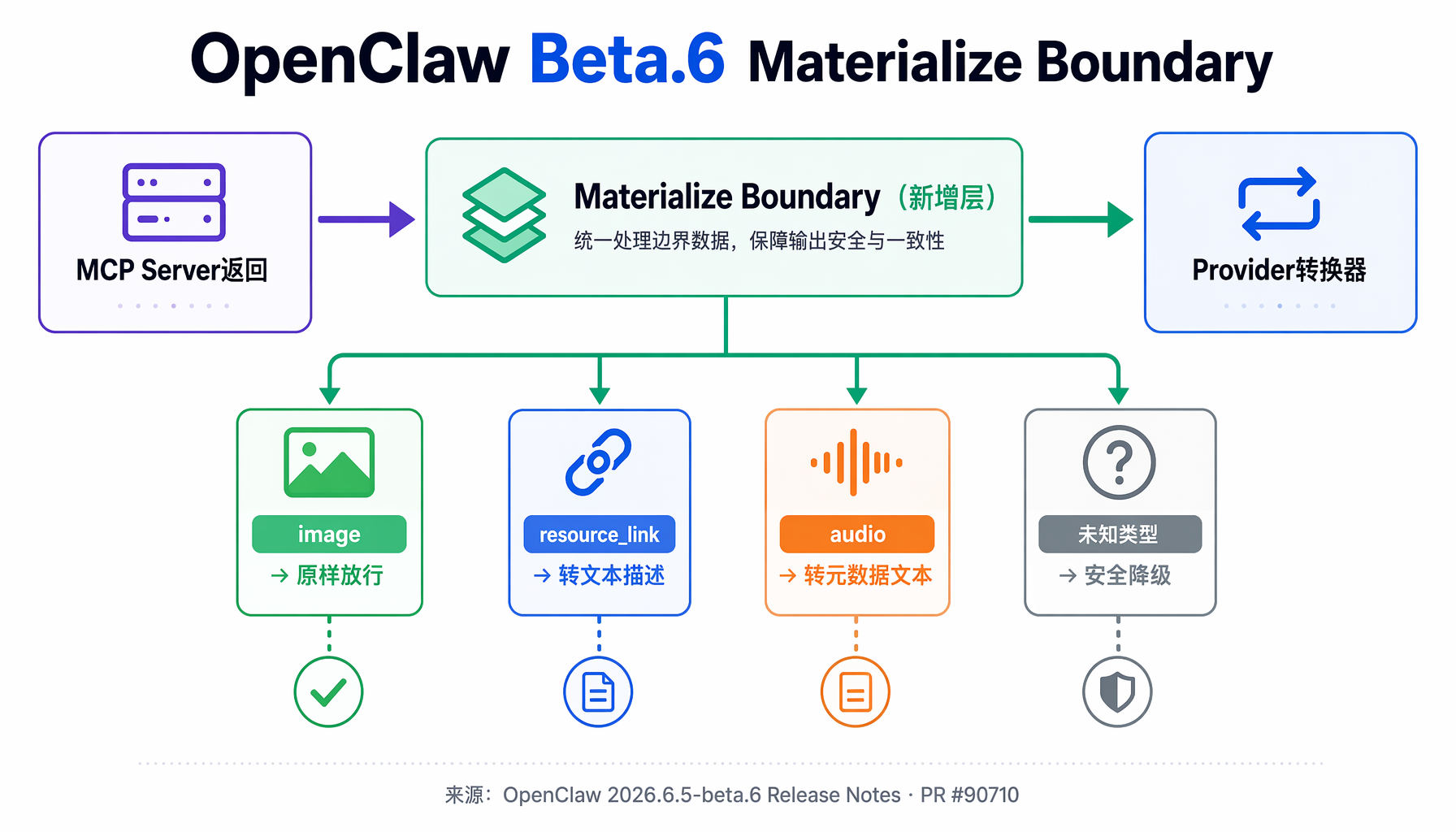
先说最重要的:MCP 工具结果强制转换,专业术语叫 "content coercion at the materialize boundary"。翻译成人话就是——以前你的 MCP 服务器如果返回了图片、文件链接、音频等内容类型,OpenClaw 会把它们一股脑塞给 Anthropic API,然后后者直接拒绝,返回 400 错误。现在 OpenClaw 在中间加了一层转换,把 Anthropic 不认识的类型自动转成它能理解的格式。相关的合并请求编号是 #90710 和 #90728,由社区成员 @RanSHammer 和 @849261680 提交。
再说另外两个实用功能。一个是 Parallel 搜索引擎插件,由社区成员 @NormallyGaussian 贡献(#85158)。它让 OpenClaw 在 Tavily 和博查之外又多了一个搜索后端可选。API 端点是 api.parallel.ai/v1/search,配置方式和其他 provider 一致。另一个是 ClawHub 技能市场,由 @Patrick-Erichsen 贡献(#90478)。你现在可以直接从 GitHub 仓库安装社区贡献的技能包,OpenClaw 会自动拉取指定版本的代码、校验文件完整性、上报安装数据。
除了这三个主要功能,beta.6 还在其他方面做了大量改进。QQBot 的消息通道现在会自动剥离模型推理过程中的 thinking 内容,防止原始的思考过程泄漏到用户聊天里(#89913)。Anthropic 扩展思考会话在 prompt-cache 过期或 Gateway 重启后能够自动恢复,因为它让流式事件等待 message_start 信号后才真正开始传输(#90667)。macOS 节点模式不再静默地从一个健康的 Gateway 会话上断开重连,减少了桌面端 Companion App 的无谓抖动(#90668)。WhatsApp 的启动等待现在有了合理的超时上限,被禁用的 WhatsApp 账号在配置重载时能正确销毁连接。
但说实话,对 90% 的 AI 创业者来说,最重要的只有那一个——MCP content coercion。下面我花最大篇幅来讲清这个东西。
为什么 MCP content coercion 是刚需级修复
旧世界的痛苦:一边造轮子一边摔跤
要理解这个修复为什么重要,得先回到 MCP 协议本身。MCP,全称 Model Context Protocol,是 Anthropic 在 2024 年底推出的一套开放协议。它的核心设计思想很简单:让 AI 模型能够调用外部工具,就像人类用浏览器访问网页、用终端执行命令一样。
协议定义了工具返回内容时使用的几种格式类型。最常见的是 text——纯文本,所有模型都支持。然后是 image——图片的 base64 编码,Claude 和 GPT-5 都支持。再往后是 resource——嵌入式资源,可以是一个小文件或一段结构化数据。还有 resource_link——指向外部资源的链接,比如一个 PDF 的 URL 或一个 S3 存储桶的路径。最后是 audio——音频数据。
问题出在后面这三种类型上。
Anthropic 的 Claude API 在 2025 年的很长一段时间里,只接收 text 和 image 两种内容类型。当你的 MCP 服务器返回了一个 resource_link——比如说,你的文件管理工具列出了目录内容,把每个文件包装成一个 resource_link 返回——Claude API 会直接拒绝这个请求:
这个错误本身并不致命。致命的是它的传播方式。
当一个 MCP 工具被调用后,它的返回结果会被写入会话历史——这是 AI Agent 的"记忆"。Agent 在下一轮对话时会重新读取完整历史,包括之前所有的工具调用和结果。如果你的工具返回结果里包含了一个 Anthropic 不认识的 content block 类型,这个错误就被写入了会话历史。下一次对话时,Agent 看到的是:
- 用户说"帮我列出文件"
- 工具调用成功了
- 工具返回了一个错误
- 用户的下一步请求
- 又调用工具
- 又是同样的错误
这种状态被称为"中毒的会话历史"(poisoned session history)。Agent 在这个状态下会反复遇到同一个错误,陷入调用失败的循环。最终要么耗尽 token 预算,要么在某个环节静默崩溃。
这不是理论上的问题。在 2026 年上半年,随着 MCP 生态快速扩张,越来越多的服务器开始返回丰富内容。文件管理类的返回 resource_link,语音处理类的返回 audio,多媒体处理类的返回 resource。每个遇到这个问题的开发者都经历了一段痛苦的调试过程:看日志 → 发现 400 错误 → 检查 MCP 服务器代码 → 发现代码没问题 → 搜索 GitHub issues → 发现这是已知问题 → 手工在每个工具函数里加类型转换 → 祈祷不要漏掉任何一个返回路径。
beta.6 的解决方案:一层中间转换
OpenClaw beta.6 的解决思路极其清晰。它没有让每个开发者自己动手处理类型兼容性——而是在 MCP 工具结果进入 Provider 转换器之前,插入了一个统一处理层,内部叫 "materialize boundary"。
这一层的工作流程如下:
这里有三个关键设计决策值得注意。
第一,不吞掉有效信息。 resource_link 虽然被转成了文本,但它保留了完整的标题和 URI。模型可以看到 [Resource: 2026年Q2财报.pdf] files.example.com/report.pdf 这样的内容,并据此决定下一步操作——比如让用户去下载这个文件,或者调用另一个工具来读取它。
第二,image 和 text 不受影响。 如果你的 MCP 服务器只返回这两种类型,行为完全不变。content coercion 只处理它们之外的类型。这是向后兼容性的保证。
第三,未来类型自动降级。 如果未来的 MCP 规范定义了新的内容类型(比如 video、3d_model),OpenClaw 不需要紧急发布补丁。materialize boundary 会自动把它们降级为文本描述,直到对应 Provider 支持为止。
实战一:构建一个返回截图的 MCP 服务器
理论讲完了,上代码。我们从头构建一个 MCP 服务器,提供一个工具 screenshot_page——接收 URL,返回网页的 PNG 截图。这个例子验证 OpenClaw beta.6 对 image 类型 content block 的处理能力。
第一步:环境准备
@modelcontextprotocol/sdk 是官方的 MCP SDK,提供了 Server 类和 StdioServerTransport。playwright 是微软的浏览器自动化库,我们用它来控制 Chromium 截图。
第二步:编写服务器代码
第三步:在 OpenClaw 中配置
在 OpenClaw 的配置文件(通常位于 ~/.openclaw/openclaw.yaml)中添加:
保存后重启 Gateway:
第四步:验证
启动 OpenClaw 对话,发送这条消息:
Agent 会调用 screenshot_page 工具,MCP 服务器返回 image + text 两种内容。Claude 模型收到图片后能够"看到"页面上的文字、按钮和布局,给出准确的描述。
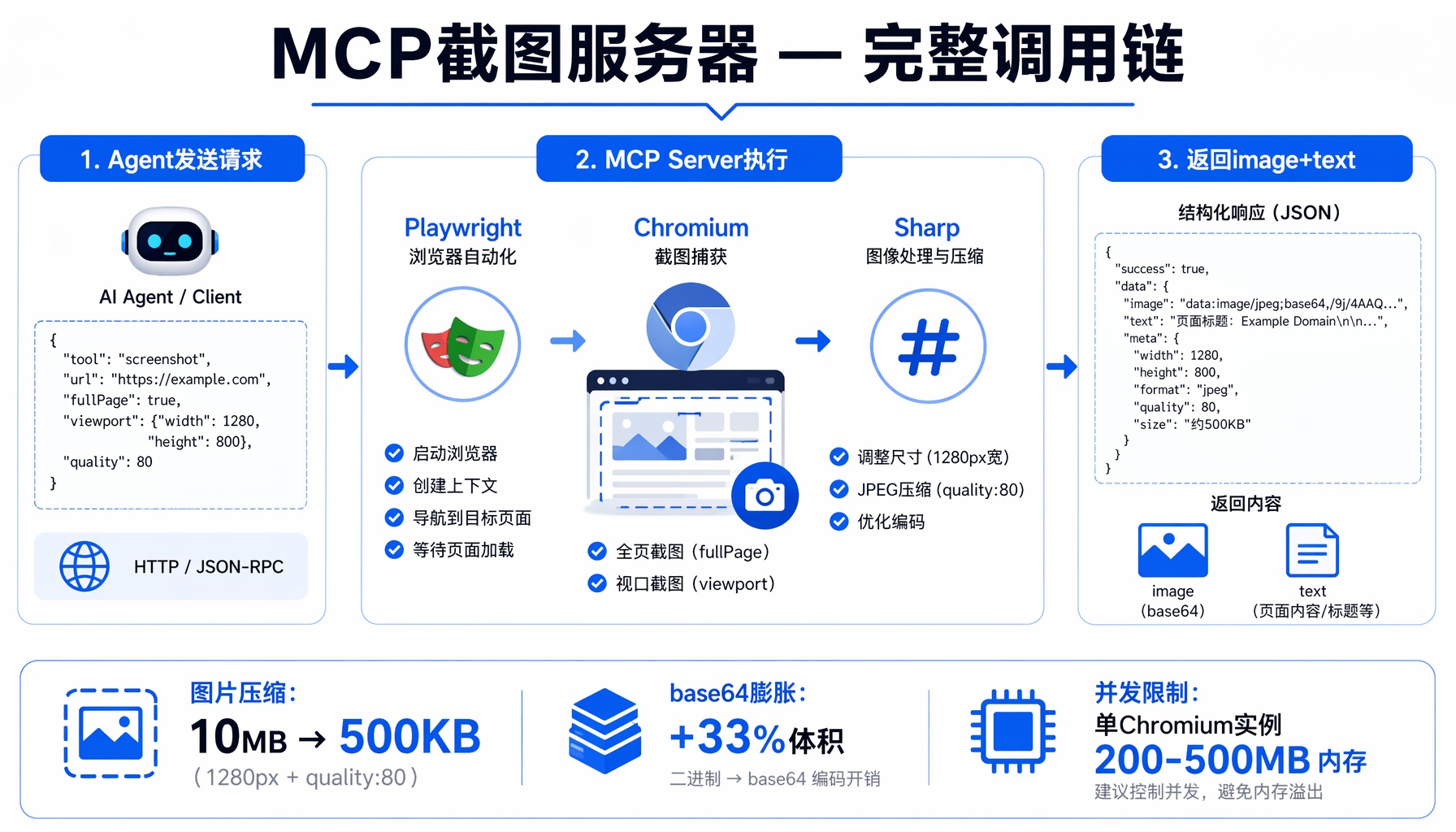 ▲ ▲ MCP截图服务器完整调用链:Agent发送请求→Playwright+Chromium执行→返回image+text双类型content
▲ ▲ MCP截图服务器完整调用链:Agent发送请求→Playwright+Chromium执行→返回image+text双类型content
踩坑提醒(每条都是实战中踩出来的)
关于图片体积。 Anthropic API 对单张图片的大小上限大约是 20MB。这个数字看起来很大,但实际上一个 1920×1080 的全页截图(fullPage: true)可以轻松达到 10-15MB 的 PNG 文件大小。尤其是对于内容丰富的网页(图片多、渐变背景多),PNG 的无损压缩效果很差。解决方案是在服务器端用 sharp 库做压缩:
1280px 的宽度在手机上查看已经足够清晰,同时能把文件大小从 10MB 压缩到 500KB 左右。
关于 base64 编码。 PNG 图片的 base64 编码体积比原始二进制大约增加 33%。这意味着一个 5MB 的原始文件在传输时会变成约 6.7MB 的文本。虽然 Anthropic API 的请求体限制够大,但每次调用的网络延迟和 token 消耗都会增加。建议在 MCP 服务器内部就把图片压缩到合理大小。
关于 Playwright 的环境依赖。 如果你用 Docker 部署这个 MCP 服务器,需要安装 Chromium 的系统级依赖库(字体、图形库、沙箱依赖等)。推荐使用微软官方提供的 Playwright Docker 镜像作为基础镜像,或者用 npx playwright install-deps 在容器内自动安装缺失的依赖。
关于并发调用。 如果你的 Agent 同时打开了多个浏览器页面进行截图,注意内存占用。一个 Chromium 实例默认占用 200-500MB 内存,10 个并发实例就能吃掉 2-5GB。建议使用 browser pool 限制最大并发数,或者用单例模式共享一个 browser 实例、在它下面创建多个 page。但要注意:共享 browser 时,一个 page 的崩溃可能导致整个 browser 进程退出。
实战二:处理 resource_link——文件管理 MCP 服务器
第二个实战场景更贴近日常工作——文件管理。假设你有一个 MCP 服务器可以浏览和操作文件系统,你希望它能列出目录下的文件,并为后续操作(读取、编辑、删除)做好准备。
在 beta.6 之前,如果你用 resource_link 类型返回文件列表,Agent 大概率会炸。在 beta.6 之后,这变得安全了。
在 beta.6 的 materialize boundary 处理之后,Agent 实际收到的内容是:
模型看到了完整的文件名、类型和路径信息。它可以根据这些信息决定下一步:是读取 README.md 了解项目说明,还是查看 config.json 修改配置,或者进入 src/ 目录浏览源代码。
resource_link 的最佳实践
第一,title 要有信息量。 不要用内部 ID 或哈希值作为标题(比如 a4f3b2c1.pdf),用人类可读的文件名或描述性文字(比如 2026年Q2财务报告.pdf)。Agent 和用户都根据标题来判断是否值得进一步操作。
第二,mimeType 要准确。 正确的 MIME 类型能让 OpenClaw 做出更智能的判断。比如它知道 application/pdf 类型的文件通常需要用专门的 PDF 阅读工具打开,而 text/markdown 可以直接用文本工具读取。
第三,uri 要可访问。 如果 MCP 服务器运行在本地,file:// 协议是合理的。但如果 Agent 运行在远程服务器上,file:// 指向的是服务器的本地文件系统,而不是用户的本地文件系统。这种场景下,考虑用可下载的 URL 地址,或者用对象存储的协议(如 s3://)。
实战三:ClawHub 技能市场——别再让 Agent 从零开始
OpenClaw beta.6 的第三个重要更新是 ClawHub 技能市场。在聊怎么用它之前,先理解一个问题:技能到底是什么?
技能的本质
在 OpenClaw 的架构里,技能就是一份 SKILL.md 文件,放置在约定目录中。Agent 在每次对话开始时扫描这些文件,将其中的指令加载到自己的上下文中。文件内容通常包括:
- 技能名称和描述
- 触发条件(什么时候 Agent 应该启用这个技能)
- 工具配置(需要哪些 MCP 服务器)
- 操作流程(完成任务的标准步骤)
- 安全规则(什么不能做)
一个典型的 ClawHub 技能目录长这样:
安装和使用
安装完成后,Agent 在对话中自动获得这个技能的指令。当用户说"帮我登录淘宝后台",Agent 就知道:这件事属于 browser-automation 技能的触发范围,需要使用 Playwright MCP 服务器,登录流程遵循预定义的安全规则(不在日志中记录 Cookie、传输层必须加密等)。
对自己开发的启发
ClawHub 的出现不只意味着"可以白嫖别人的技能"。更重要的是它建立了一种技能复用的工程范式。如果你正在维护一个包含多个 Agent 的系统(比如自媒体矩阵运营、多客户服务、内部工具链),可以考虑:
- 把通用的工作流程抽象为技能文件(SKILL.md)
- 把每个技能的 MCP 服务器配置独立管理
- 用 ClawHub 的版本管理机制跟踪技能的迭代
这样当你添加一个新 Agent 时,不用重新配置提示词和工具链——直接安装对应的技能包即可。
ClawHub 的安全措施
beta.6 在技能安装时做了三层保护:
第一层:版本锁定。 安装技能时,OpenClaw 记录的是具体的 commit hash,而不是分支名或标签名。这意味着即使技能作者在后续版本中修改了内容,你的本地技能不会自动更新。你需要显式执行更新命令才会拉取最新版本。这防止了供应链攻击中最常见的一种——攻击者先发布一个无害版本积累用户,然后在后续更新中注入恶意代码。
第二层:完整性校验。 下载过程中对文件内容做 hash 校验,确保传输过程没有被中间人篡改。这个机制对通过 HTTP 而非 HTTPS 传输的场景尤为重要。
第三层:遥测上报。 安装完成后上报匿名的安装统计(技能名称、来源仓库、安装时间),不包含任何用户身份信息。这帮助社区快速发现异常——如果某个技能突然出现大量卸载,可能意味着这个技能有问题。
踩坑提醒
安装技能后记得重启 Gateway,否则 Agent 在下一轮对话中不会加载新技能的指令。如果技能依赖某个特定的 MCP 服务器,你需要在 OpenClaw 配置中单独声明该服务器的运行参数——ClawHub 不会自动帮你启动 MCP 服务器进程。
 ▲ ▲ OpenClaw三搜索后端对比:Tavily(英文强)、Bocha博查(中文强)、Parallel(Beta.6新增)
▲ ▲ OpenClaw三搜索后端对比:Tavily(英文强)、Bocha博查(中文强)、Parallel(Beta.6新增)
Bonus:Parallel 搜索引擎——多一个后备总是好的
OpenClaw 的 web_search 现在支持三个后端:Tavily、Bocha(博查)和 Parallel。你可能已经有 Tavily 或博查的 API Key,为什么还需要第三个?
实际场景中的搜索引擎选择
我维护了一个每天产出一篇深度文章的 AI 内容工厂。在实际运行中,搜索引擎不是"好不好用"的问题,而是"能不能用"的问题:
- Tavily 的免费额度是每月 1000 次搜索。一篇深度文章需要 8-10 次搜索做交叉验证。一天一篇就是 300 次/月。看起来够用,但当多个 Agent 同时运行(热点扫描、教程撰写、深度分析),很快就到了配额上限。
- 博查对中文内容质量极高,但英文搜索是短板。想搜索一个英文技术博客的最新更新,博查经常返回空结果。
- 两个后端同时不可用的概率虽然低,但不是零。Tavily 的网络连接到国内偶有超时,博查的 API 也出现过短暂的不可用。
Parallel 的加入,本质上是在可靠性上多了一层保障。
配置
环境变量中设置 PARALLEL_API_KEY。不需要改任何其他配置——OpenClaw 的 Provider 层统一了三种后端的返回格式,Agent 看到的结果结构完全一致。
三后端对比
| 维度 | Tavily | Bocha(博查) | Parallel |
|---|---|---|---|
| 中文搜索质量 | 一般,依赖翻译 | 优秀,原生中文索引 | 中等 |
| 英文搜索质量 | 优秀 | 较弱 | 良好 |
| 国内信源覆盖 | 几乎为零 | 全面(知乎、CSDN、微信) | 有限 |
| API 响应速度 | 快(<1s) | 快(<1s) | 稍慢(首次 200-500ms 冷启动) |
| 配额限制 | 免费 1000/月,付费扩容 | 按量付费 | 待确认 |
| 稳定性 | 偶发 432 配额错误 | 较为稳定 | 新 provider,尚待观察 |
选型建议
如果你的 AI Agent 主要处理中文内容(公众号文章、知乎问答、国内技术社区),Bocha 是毋庸置疑的首选。如果你的 Agent 需要交叉验证英文技术信息(GitHub issues、学术论文、国际媒体报道),Tavily 是最好的选择。Parallel 作为第三选择,可以在前两者不可用时顶上——或者在你需要更多搜索配额时作为一个补充渠道。
完整工作流:从信息采集到草稿发布
把以上三个功能串起来,你会得到一个完整的 AI 内容创作工作流:
第一步是信息采集。Agent 用 Bocha 搜索今天的中文 AI 热点,用 Tavily 搜索英文技术社区的最新动态。两边结果交叉验证,排除营销软文和重复报道。如果任何一个后端不可用,Parallel 自动顶上。
第二步是截图验证。对于重要的信息来源(GitHub Release 页面、官方技术博客更新),Agent 调用 screenshot MCP 服务器截取页面。模型"看到"了页面的实际内容,可以核实版本号、发布日期、功能描述等关键信息,而不是依赖搜索结果的摘要——摘要经常滞后甚至错误。
第三步是文件管理。验证过的信息写入 Markdown 草稿文件。Agent 通过文件管理 MCP 服务器浏览、读取、编辑这些文件。如果一篇草稿需要插入来自多个来源的数据,Agent 可以列出之前采集的所有文件,找到最合适的数据源,读取并提取关键信息。
第四步是技能复用。写作规范(字数要求、结构模板、质量自检清单)、排版要求(build_article_html.py 的调用方式、插图位置)、发布流程(WeChat API 的端点、token 获取方式)都封装为 ClawHub 技能。Agent 在写作时自动加载这些技能,不需要每次在 Prompt 里重复一长串指令。
第五步是发布。Agent 调用 WeChat API 上传封面和插图,排版引擎把 Markdown 转成微信公众号兼容的 HTML,提交到草稿箱。
整个流程中,MCP content coercion 保证了第二步和第三步不会因为内容类型不兼容而崩溃。ClawHub 技能保证了第四步的一致性和可复用性——新增一个栏目只需要安装新的技能包,不用修改 Agent 的核心 Prompt。Parallel 搜索保证了第一步的可靠性——即使主搜索后端不可用,信息采集也不会中断。
常见问题
问:我的 MCP 服务器只返回 text 类型,需要修改代码适配 beta.6 吗?
不需要。content coercion 是向后兼容的。如果你只返回 text 和 image,行为与 beta.5 完全一致。只有当返回 resource_link、resource、audio 或未来未知类型时,新逻辑才会被触发。
问:beta.6 会把我的图片也降级为文本吗?
不会。在 materialize boundary 的处理逻辑中,image 类型被明确排除在转换范围之外。它原样传递给 Provider。如果你的模型支持图片(Claude 3.5/4、GPT-5 都支持),模型能看到完整的图片内容。如果模型不支持图片(某些纯文本模型),OpenClaw 的 Provider 层会做降级处理,但这属于另一个处理阶段,不在 materialize boundary 的职责范围内。
问:resource_link 被转成纯文本后,模型还能操作那个文件吗?
模型本身不能直接操作文件——它不是操作系统。但模型能看到 [Resource: report.pdf] file:///data/report.pdf 这样的文本,它理解"这里有一个 PDF 文件,路径是 /data/report.pdf"。它可以根据这个信息决定调用另一个能够读取 PDF 的工具(比如一个支持 PDF 解析的 MCP 服务器),把 file:///data/report.pdf 作为参数传给那个工具。
问:ClawHub 技能和直接写 SKILL.md 放在技能目录有什么区别?
功能上没有区别。ClawHub 增加的价值在于版本管理(pinned commit 防止供应链攻击)、社区共享(发现和安装其他人贡献的技能)、以及自动化安装流程(一条命令拉取 GitHub 仓库)。如果你只有一两个技能,手动管理完全够用。如果你维护十个以上的技能,或者你的团队有多个人共享技能库,ClawHub 的版本管理优势会很明显。
问:Parallel 搜索需要额外付费吗?
目前 Parallel 搜索的具体定价尚未在 OpenClaw 官方文档中明确说明。建议访问 parallel.ai 的官网查看最新的定价信息,或者在 OpenClaw 的 GitHub Discussions 中询问社区。按照惯例,OpenClaw 内置的搜索 provider 通常提供免费额度,超出后按量计费。
风险提示
第一,beta.6 是 beta 版本。 虽然 QA Lab 做了自动化测试,但 beta 版本意味着可能还有未被发现的边界情况。如果你的 Agent 在生产环境中运行,建议先在 staging 环境验证至少 24 小时。
第二,MCP content coercion 处理复杂嵌套结构时可能有边界情况。 如果你的 MCP 服务器返回的 content 数组包含多层嵌套(比如一个 resource 里面又包含 resource_link),建议单独测试确认行为。
第三,ClawHub 技能的安全审核依赖社区机制。 目前没有自动化的恶意代码检测。安装技能前建议查看该仓库的 Star 数量、最近更新记录和 issue 反馈。
第四,Parallel 搜索是新的 provider。 API 的稳定性、响应速度和配额政策可能在未通知的情况下调整。不建议将其作为唯一的搜索依赖。
行动建议
如果你正在用 OpenClaw 构建 AI Agent 产品,建议按以下时间线行动:
今天就可以做的:升级到 2026.6.5-beta.6,重启 Gateway,验证你的现有 MCP 服务器是否正常工作。如果之前有一些工具因为返回 resource_link 而间歇性失败,现在可以观察是否稳定了。
本周可以做的:配置 Parallel 搜索作为后备方案。即使你现在主要用 Bocha 或 Tavily,有一个备用的搜索后端能在关键时刻救急。浏览 ClawHub 上已有的技能,看看有没有能直接复用的——减少重复造轮子的工作量。
下周可以做的:如果你有一些经过实战验证的技能(比如某个垂直行业的 MCP 工具配置、某个特殊场景的提示词模板),考虑打包成 ClawHub 技能贡献给社区。一个人走得快,一群人走得远——这在 AI Agent 工具链的建设中尤其适用。
升级命令:
**参考来源**:OpenClaw GitHub Releases(2026.6.5-beta.6,发布于 2026 年 6 月 9 日 UTC 08:43),MCP Protocol Specification(Anthropic,2024-2025),OpenClaw 官方文档。本文代码示例在 OpenClaw 2026.6.5-beta.6 + MCP SDK 最新版 + Node.js 20.x 环境下验证。
#AI创业 #Agent工坊 #MCP协议 #OpenClaw #一人公司
本文由AI辅助创作,经人工审核编辑发布