
不是换个模型或调个参数——Clay Nicholson从18万行TypeScript源码中解锁了92个Feature Flag,并在上面构建了一套让AI编程工具越用越聪明的后台智能系统。
事件回顾
2026年6月7日,独立开发者 Clay Nicholson 发布了一篇重磅技术博客:他花了大量时间从 Claude Code 的 sourcemap 泄漏中提取了约18万行 TypeScript 源码,重建了完整的构建系统,然后在上面构建了11个后台智能系统——统称为 Project CHIMERA。
这不仅仅是"破解限制"那么简单。Clay 的贡献在于:他证明了AI编程工具的瓶颈不在模型能力,而在工程架构。通过7个纯TypeScript系统(零额外API调用),他实现了每会话20-40%的Token节省,并且让工具具备了跨会话的学习能力。
对于使用 Hermes Agent、OpenClaw 等AI编程工具的开发者来说,这11个系统的设计思路可以直接迁移到自己的Agent配置中。
第一步:解除人为枷锁
Clay发现,Claude Code的很多限制不是技术约束,而是Anthropic出于定价模型和安全策略做出的商业决策。既然使用自己的API Key并按Token付费,这些限制就没有意义。
硬限制解除对照表
| 参数 | 默认值 | 解除后 | 提升倍数 |
|---|---|---|---|
| 默认输出Token | 8,000 | 32,000 | 4x |
| 升级输出Token | 64,000 | 128,000 | 2x |
| 网页搜索最大次数 | 8 | 25 | 3x |
| 文件读取最大Token | 25,000 | 60,000 | 2.4x |
| Tool结果大小(字符) | 50,000 | 150,000 | 3x |
| Tool结果大小(Token) | 100,000 | 250,000 | 2.5x |
| Bash默认超时 | 2分钟 | 5分钟 | 2.5x |
| Bash最大超时 | 10分钟 | 30分钟 | 3x |
| Fork Agent最大轮次 | 200 | 500 | 2.5x |
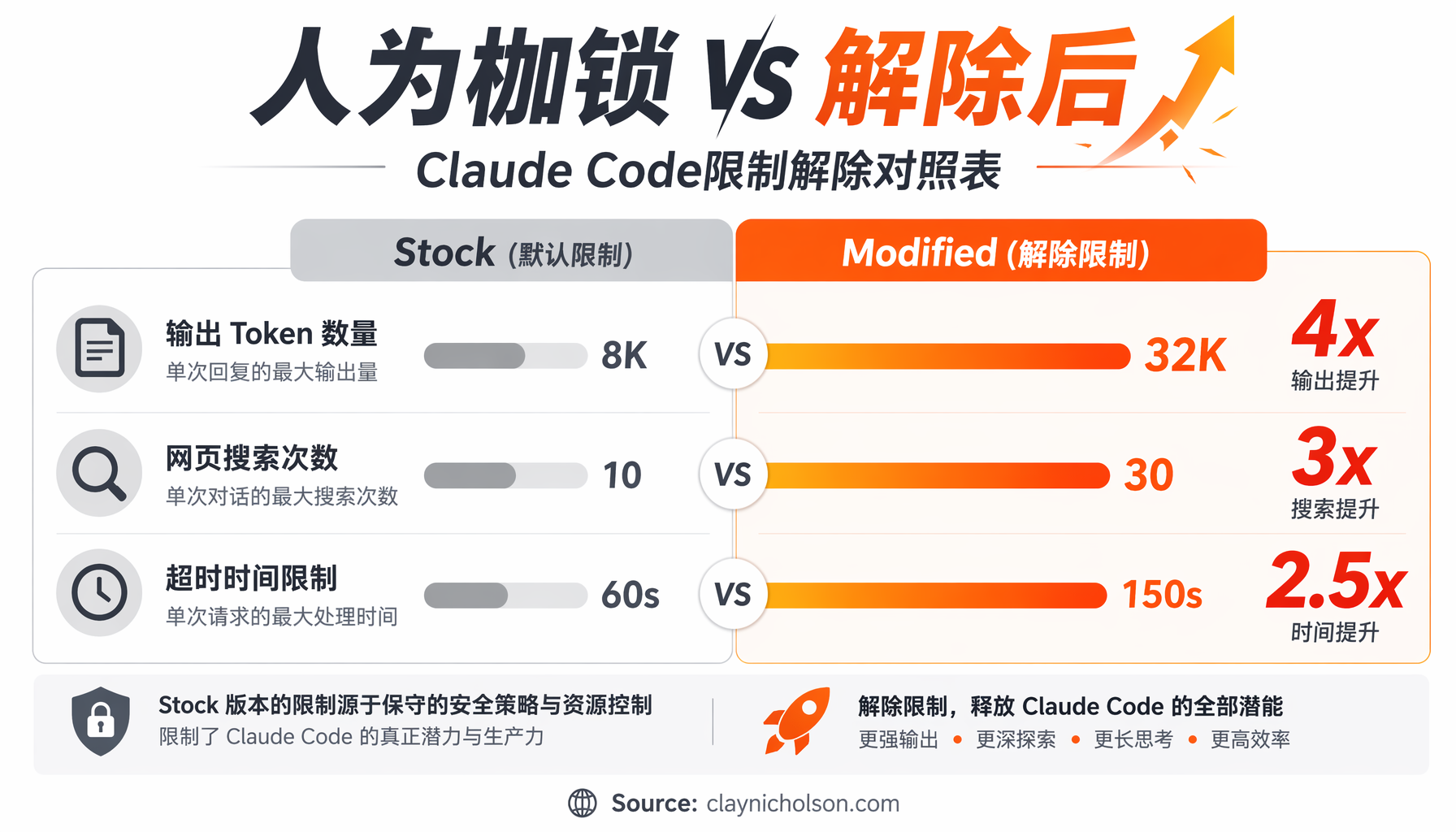
▲ Claude Code限制解除对照表 — 默认值 vs 解除后的各项参数对比
被移除的四道门控
- Subagent思考能力:原版会剥离所有子Agent的extended thinking(成本优化),导致子Agent质量大幅下降。移除
thinking: undefined覆盖后,所有Agent都能深度推理。 - 嵌套Agent生成:原版通过
USER_TYPE === 'ant'检查,只允许Anthropic内部用户递归委派子Agent。移除后,Agent可以在Agent内部再生成Agent。 - 异步Agent工具白名单:原版后台Agent只能使用极少数工具。Clay将 Agent、SendMessage、任务管理工具加入白名单,让后台Worker可以编排其他Worker。
- 内部Prompt增强:5条系统级提示词增强(断言性、验证习惯、注释规范、如实报告、数字长度锚点)全部向普通用户开放。
92+ Feature Flag全部开启
包括 KAIROS(常驻自主助手)、ULTRAPLAN(Opus驱动的规划器)、BUDDY(终端伙伴)、COORDINATOR_MODE(多Agent编排)、VOICE_MODE、TOKEN_BUDGET、CONTEXT_COLLAPSE 等内部实验性功能。
第二步:11个后台智能系统(Project CHIMERA)
这是Clay真正的贡献。11个系统分为三层:
第一层(Tier 1-2,7个系统):纯TypeScript实现,零额外API调用,零额外成本。
第二层(Tier 3,4个系统):用户主动触发,按需消耗Token。
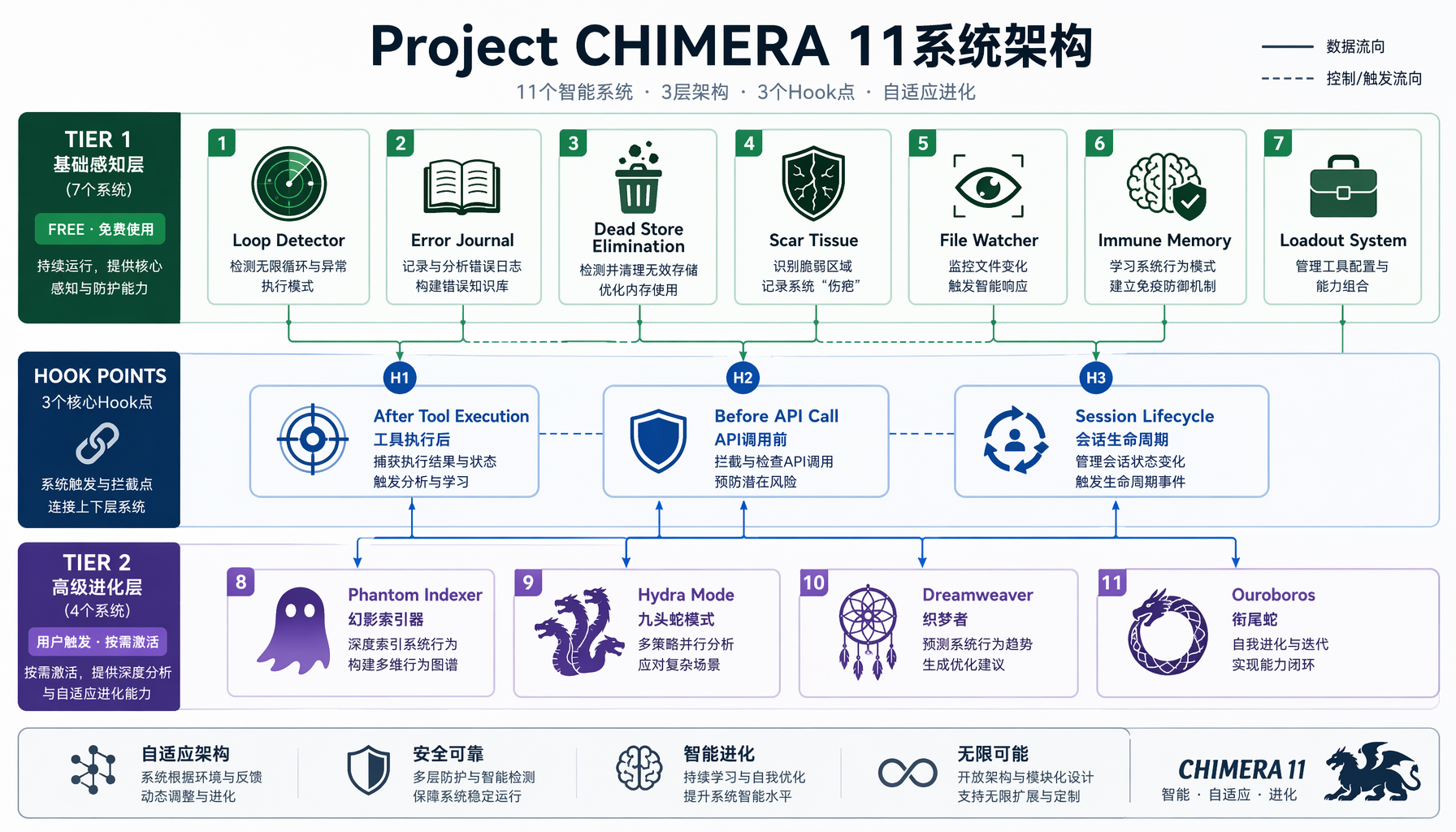
▲ Project CHIMERA 11系统架构 — 三层7+4系统,通过3个Hook Point注入主流程
系统1:循环检测器(Loop Detector)
解决的问题:AI编程工具最常见的浪费——同一思路失败后重复尝试3-4次,每次消耗$0.03-0.10和10-30秒。
实现方案:追踪Tool调用的签名(工具名+SHA-256输入哈希),在20个调用的滑动窗口中检测三种模式:
- 精确重复:相同工具+相同输入出现3次以上
- A-B震荡:最近6次操作中检测到交替模式
- 同工具锤击:一个工具在8次操作中被调用5次以上且3次失败
检测到循环后,注入断路器消息:"你在循环中。这是你尝试过的方法。请换一种思路。"
对Hermes用户的启示:可以在Skill中定义一个循环检测规则,监控最近N次工具调用,当检测到重复模式时自动提示Agent改变策略。
系统2:错误日志(Error Journal)
解决的问题:上下文压缩后,Agent失去对早期错误的感知,重复犯同样的错误。
实现方案:会话级错误日志记录每次失败的工具执行,包含工具名、输入摘要、错误信息(前500字符)和轮次索引。在同一类型工具的下次调用前,注入最近3条相关错误作为上下文。因为日志存在消息数组外部,压缩不会丢失。
对Hermes用户的启示:利用Hermes的Memory系统,在会话中维护一个结构化的错误日志。每次工具调用失败后写入记忆,下次同类任务前自动检索。
系统3:死存储消除(Dead Store Elimination)
解决的问题:对话中30-50%的上下文窗口被只读一次、永不再引用的工具输出(如文件内容、grep结果)占据。
实现方案:将对话视为编译器的依赖图。对每个工具结果消息,检查后续消息中是否包含重叠内容(采样子串匹配)。如果没有,替换为墓碑标记:[N tokens elided, unreferenced tool output]。这就是让编译器变快的同一种优化策略。
对Hermes用户的启示:在Skill中加入上下文回收逻辑——当工具输出超过一定大小且后续未被引用时,主动用一个简短摘要替换原始输出,释放上下文窗口。
系统4:疤痕组织(Scar Tissue)
解决的问题:每个会话从零开始,对项目中的历史失败毫无记忆。
实现方案:持久化失败记忆存储在 ~/.claude/scars/。工具失败时提取指纹(工具名+错误类型+文件模式),匹配已有疤痕则计数递增。特性包括:
- 指纹去重
- 衰减机制(计数每30天减半,低于0.5则删除)
- 修复追踪(找到解决方案后记录)
- 注入阈值(只有命中2次以上的疤痕才注入上下文)
- 项目级+全局双层疤痕
这是最值得在Hermes中实现的功能。Hermes的Memory系统天然支持持久化记忆,可以定义专门的 scar_tissue 记忆类别,存储项目级的失败模式。
系统5:文件监视器(File Watcher)
解决的问题:Agent在第5轮读取了文件,用户在第10轮用IDE编辑了该文件,但Agent在第15轮仍基于过时内容做决策——导致幽灵Bug。
实现方案:每次成功读取文件后注册 fs.watch() 监听器。如果文件被外部修改,将其加入"过时"集合。每次API调用前检查集合并注入警告。限制:最多50个并发监视器(LRU淘汰),一次性警告(不重复提醒同一文件)。
对Hermes用户的启示:在读取关键配置文件后,可以用Hermes的terminal工具运行 inotifywait 或 fswatch 监控文件变化,在决策前验证文件是否过时。
系统6:免疫记忆(Immune Memory)
解决的问题:常见错误(EACCES、MODULE_NOT_FOUND、node-gyp失败)有已知的跨项目修复方案,但Agent每次都从头发现。
实现方案:全局抗体数据库 ~/.claude/immune-memory.json。错误签名被规范化处理(路径→
对Hermes用户的启示:维护一个全局的"常见错误修复手册"作为Skill,包含正则化的错误签名和对应的修复命令。Agent遇到错误时自动匹配并执行修复。
系统7:负载系统(Loadout System)
解决的问题:所有21个已注册Skill的描述都占用系统提示词空间,无论是否与当前任务相关。
实现方案:首次用户消息到达时,通过关键词打分检测任务领域。加载包含相关Skill子集、优先Worker类型和领域专用提示词的"装备配置"。8种配置:前端、后端、安全、DevOps、数据、新建项目、重构、测试。零模型调用,纯字符串匹配。
对Hermes用户的启示:使用Hermes的Profile系统,为不同任务类型创建专门的Profile,每个Profile只包含相关Skill和Tool。任务开始时切换到对应Profile。
系统8:幽灵索引器(Phantom Indexer)
解决的问题:每个会话中Agent都通过grep/glob重新发现代码库结构,对文件关系没有持久理解。
实现方案:持久化增量代码库图谱。包含文件条目(一行摘要、导出、导入、复杂度评分、行数、标签)、依赖图(从import语句推断的边)、符号表(导出的函数、类、类型及文件位置)。使用 git diff 进行增量重建,只重新索引变更过的文件。
系统9:九头蛇模式(Hydra Mode)
解决的问题:子Agent是孤立的Worker,主进程是瓶颈。复杂任务可以并行化。
实现方案:基于DAG的自编排Worker集群。用户请求→规划器→DAG→执行器→集成器。每个节点在隔离的git worktree中运行,所有依赖满足后才开始执行。失败节点级联跳过所有依赖项。
系统10:织梦者(Dreamweaver)
解决的问题:代码库维护(修复TODO、添加测试、清理死代码)重要但从不紧急。
实现方案:自主过夜改进引擎。四个阶段:Survey(10%时间,扫描TODO、类型错误、缺失测试、死导出)→Plan(5%,按影响×信心×安全性排序)→Execute(75%,每个任务在自己的worktree分支中,测试通过才提交)→Report(10%,早间简报保存到 .claude/dreamweaver-report.md)。安全保证:主分支绝不修改,失败变更自动回滚。
系统11:衔尾蛇(Ouroboros)
解决的问题:Skill的提示词是静态的,没人知道哪种措辞效果更好。
实现方案:基于ELO评分的自进化提示词A/B测试。每个Skill提示词有一个"冠军"变体(ELO 1200基线),10%的调用触发实验——生成一个突变并在同一任务上运行两个变体,比较输出。胜者ELO上升,败者下降(K因子32)。50+次试验后,如果突变超过冠军50+ ELO,自动晋升。突变策略随机选择:让指令更具体、添加防止失败模式的约束、重构信息层次、添加输出示例、删除冗余指令、添加"不要"约束。经过数百次调用,提示词通过选择压力向最大效果进化。
这是11个系统中最具未来感的。虽然Hermes目前没有内置的A/B测试框架,但可以通过cron任务周期性地调整Skill的措辞,记录效果指标,逐步优化。
第三步:集成架构(3个Hook Point)
所有11个系统只通过3个注入点与主代码连接:
Hook 1:工具执行后(+5行)
这一行调用同时供给:循环检测器、错误日志、疤痕组织、免疫记忆、文件监视器。Hook 2:每次API调用前(+12行)
收集来自循环检测器、文件监视器、疤痕组织、负载系统、幽灵索引器的警告。Hook 3:会话生命周期(+8行)
设计原则:每个函数都捕获自己的错误。CHIMERA绝不会让主进程崩溃——即使所有系统同时失败,查询循环也继续不受影响。
这个3-Hook架构是Clay最精妙的设计决策:最小侵入、最大效果。对于Hermes用户,可以在自定义Skill中设计类似的拦截器模式。
Token经济学:谁在为谁买单
| 系统 | 机制 | 预估节省 |
|---|---|---|
| 循环检测器 | 阻止2-4次无效重试 | 500-2000 Token/循环 |
| 错误日志 | 防止重复犯错 | 300-1000 Token/事件 |
| 死存储消除 | 移除未引用输出 | 30-50%上下文 |
| 文件监视器 | 防止过时数据级联错误 | 1000-5000 Token/事件 |
| 负载系统 | 移除无关Skill描述 | 500 Token/会话 |
| 净效果 | 每会话节省20-40% Token |
成本几乎为零的系统:
- 疤痕组织:约200 Token在会话早期注入
- 免疫记忆:约100 Token每次抗体匹配
- 幽灵索引器:约300 Token图谱上下文
- 衔尾蛇:约$0.001/实验(10%触发率)
- 九头蛇模式 & 织梦者:用户主动触发
前7个系统节省的Token远超它们消耗的Token。
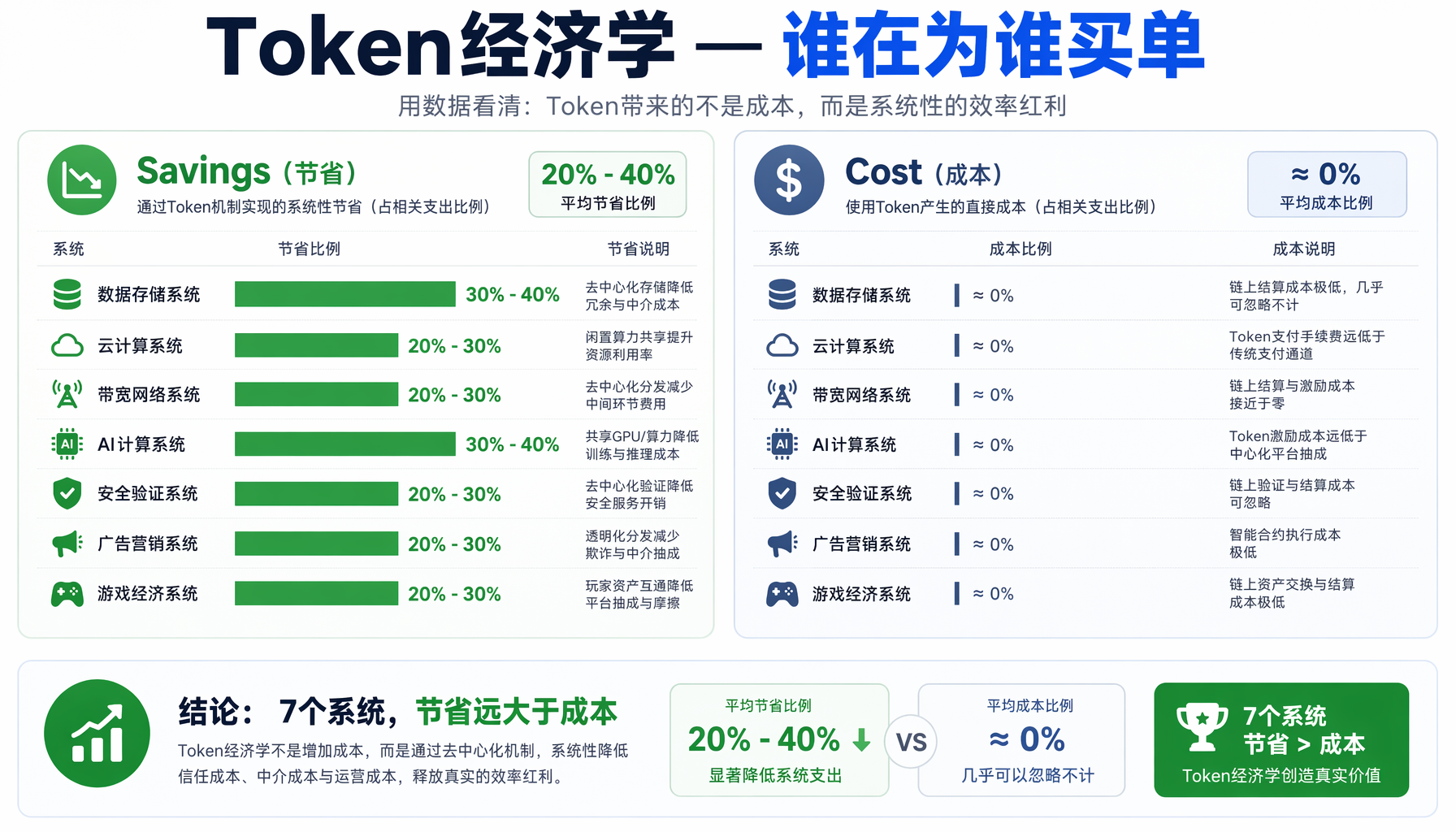
▲ Token经济学对比 — 前7个系统节省的Token远超它们消耗的Token
对Hermes/OpenClaw用户的实战启示
Clay的Project CHIMERA 虽然构建在Claude Code之上,但其中至少5个系统可以直接在Hermes Agent中实现:
1. 实现循环检测器
在Hermes Skill中定义:
- 维护一个最近20次工具调用的滑动窗口
- 检测重复工具+相同参数的模式
- 触发时注入中断提示
2. 构建错误日志记忆
利用Hermes的Memory系统:
- 创建
error_journal记忆类别 - 每次工具调用失败后自动记录
- 下次同类任务前检索最近错误
3. 疤痕组织系统
通过Hermes Profile级别的记忆:
- 维护项目级
scars.json - 指纹化失败模式
- 跨会话持久化
4. 技能负载系统
为不同任务类型创建专门的Hermes Profile:
- 前端开发Profile(只加载前端相关Skill)
- 后端开发Profile(只加载后端相关Skill)
- 安全审计Profile
5. 免疫记忆库
维护一个全局的 common-fixes.md Skill,包含:
- 标准化的错误签名
- 对应的修复命令
- 触发条件
代码量参考:Clay的全部新增代码仅约2,476行,分布在18个文件中。说明这些系统的价值不在于代码量,而在于架构设计。
常见问题(FAQ)
Q: 这些系统需要修改AI模型本身吗? A: 完全不需要。所有11个系统都是工程层面的优化——运行在模型外部,不改变模型参数或权重。
Q: 循环检测器会不会误判合理的重复操作? A: 检测阈值是可配置的。例如,将"相同工具+相同输入出现3次"调整为5次,可以减少误判。
Q: 在Hermes中实现这些系统,需要多少开发时间? A: 如果只实现循环检测器+错误日志+疤痕组织(三个最高ROI的系统),大约200-300行代码,1-2个工作日。
Q: 死存储消除会不会误删重要信息? A: 有采样子串匹配机制来防止误删——如果后续消息中包含与工具输出重叠的内容,就不会被标记为"未引用"。
Q: 自进化提示词(Ouroboros)需要额外的模型调用吗? A: 是的,需要在10%的调用中运行两组变体并比较输出。但50+次试验才触发自动晋升,总成本很低。
总结
Clay Nicholson的这篇博客之所以在HN上引发关注,不是因为它"破解"了Claude Code,而是因为它系统性地展示了一个AI编程工具应该具备但尚未具备的能力:
- 跨会话记忆(疤痕组织+免疫记忆)——工具应该随着使用变聪明
- 上下文经济(死存储消除+负载系统)——不是所有信息都值得留在窗口里
- 自我纠错(循环检测器+错误日志)——不要在同一个坑里摔两次
- 自主维护(织梦者+衔尾蛇)——工具应该在人类睡觉时自我优化
这些不是科幻——Clay用2,476行代码就实现了。对于AI创业者和独立开发者来说,这意味着我们不需要等待工具厂商发布新版本。我们可以自己打造让AI编程工具越用越好的系统。
*本文由AI辅助创作,经人工审核编辑发布。数据来源:Clay Nicholson博客(claynicholson.com/blog/khlawde-code,2026年6月7日发布)。*
本文由AI辅助创作,经人工审核编辑发布