
AI把数据采集和分析的成本打下来了。一个会用AI的独立开发者,现在能干过去一个5人数据团队才能干的活。这不是理论——已经有人在闷声发财了。
赛道全景:数据产品为什么是一人公司的黄金赛道?
2026年6月,你打开Hacker News,前端页面上躺着几条有意思的线索:Redis发布了8.8版本,新增了array数据结构和rate limiter;微软开源了pg_durable,一个在PostgreSQL里实现的持久化执行引擎;FAISS的深度解析文章拿到了46个赞。这三条新闻指向同一个方向——世界对数据基础设施的投入前所未有地大,而这些基础设施的最终消费者,正在变成一个人。
这不是巧合。过去五年,数据赛道经历了三次"民主化"浪潮:
第一波(2020-2022):数据仓库民主化。 Snowflake和BigQuery把数据仓库从百万级的Oracle方案变成了按量付费的云服务。一个人花500美元/月就能跑PB级查询,这在2018年需要一支5人团队和至少50万美元的年度预算。
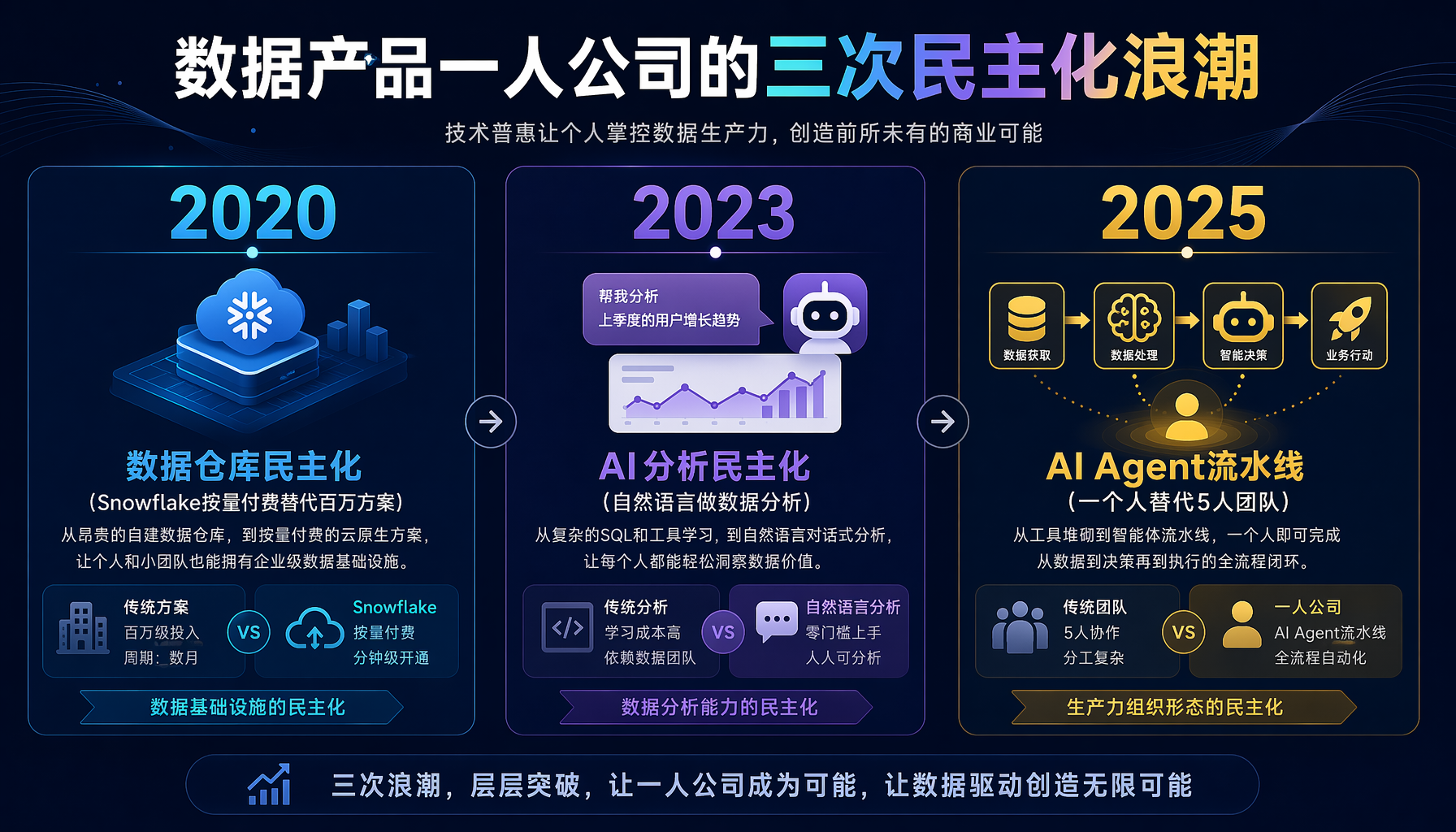
▲ 数据产品赛道的三次民主化浪潮:从数据仓库到AI Agent流水线
第二波(2023-2025):AI分析民主化。 ChatGPT和Claude让非技术人员也能用自然语言做数据分析。以前需要SQL/Python/R三件套的分析任务,现在一句"You are a data analyst, here's my CSV, tell me the top 5 insights"就能出结果。门槛从"会写代码"降到了"会打字"。
第三波(2025-2026,现在):AI Agent数据流水线。 Claude Code、Hermes Agent、Cursor这些AI编程工具让一个人可以维护完整的数据采集→清洗→分析→交付流水线。过去一个5人数据团队的活——爬虫工程师、数据清洗工程师、分析师、可视化工程师、项目经理——现在一个会用AI Agent的独立开发者就能搞定,而且质量不降反升。
关键数据:
- 全球数据标注市场2025年达53亿美元,预计2028年达118亿美元(年复合增长率22%)
- API经济中,数据类API(天气、金融、电商、社交媒体)占所有付费API调用的34%
- 独立开发者数据分析SaaS的典型MRR在$3K-$15K之间,利润率通常超过70%
- AI代理的分析能力在过去18个月内从"能做简单图表"进化到"能独立完成客户交付的分析报告"
当前机会窗口:大公司在忙着抢GPU、训练大模型、做AGI。而数据基础设施层面的缝隙——特定行业的数据集、垂直场景的API、小企业的数据分析服务——恰恰是一人公司的最佳切入点。大公司看不上,小团队做不了,但一个人靠AI完全能搞定。
人物档案:Mike Carson,从Uber数据分析师到$18K MRR的独立数据创业者

▲ Mike Carson的创业时间线:从裁员到MRR $18K的三年蜕变
Mike Carson的故事在独立开发者圈子里不算最出名的,但足够典型。
2019年,Mike在Uber做高级数据分析师,年薪$165K加股票。日常工作就是用SQL写查询、用Tableau做仪表盘、用Python跑模型。2022年大裁员,他拿了6个月遣散费走人。
他没急着找工作,而是注意到一个问题:Uber每年在数据基础设施上花3000万美元,而跟他聊天的本地餐厅老板连Google Analytics都用不明白。这不是能力差距,是工具代差。
他花了3个月做了一个叫"TableDash"的产品——本质上是把他在Uber那套数据分析流程,用AI Agent自动化后,包装成一个$99/月的SaaS。目标客户是年营收$1M-$10M的中小企业,这些人有钱但没数据团队。
他的时间线:
- 2022年10月:裁员,开始调研
- 2022年11月:用Python+Claude搭建第一版原型(数据接入→自动分析→自然语言报告)
- 2023年1月:在Indie Hackers上发布了build in public帖子,拿到前5个付费客户
- 2023年6月:MRR达到$4,000,辞掉了兼职咨询工作
- 2024年3月:MRR达到$12,000,雇了第一个兼职客服
- 2025年12月:MRR达到$18,000,客户数247家,年营收$216K,净利润率83%
他的技术栈(2026年版本):
- 数据采集:ScrapingBee API(网页抓取)+ Fivetran(数据库同步)+ 自建Python爬虫(Claude Code维护)
- 数据存储:PostgreSQL (Supabase) + TimescaleDB(时序数据)
- 数据处理:Python pandas + Claude API(自然语言分析)
- 可视化:Plotly + 自研React组件
- 交付:自动生成PDF报告 + 交互式Web仪表盘
- AI Agent:Hermes Agent(任务调度)+ Claude Code(代码编写和维护)
- 基础设施:AWS(EC2+RDS+S3),月成本约$2,100
最关键的决策:他没有自己做数据抓取。他说:"数据抓取是一个运维噩梦——网站改版、反爬升级、IP被封。我让客户自己接入数据源(Stripe、Shopify、QuickBooks等标准化接口),我只做分析层。这不仅让我的产品更稳定,还让客户觉得数据是'他们自己的',信任感更强。"
工具栈全拆解:2026年一人数据公司的技术选型指南
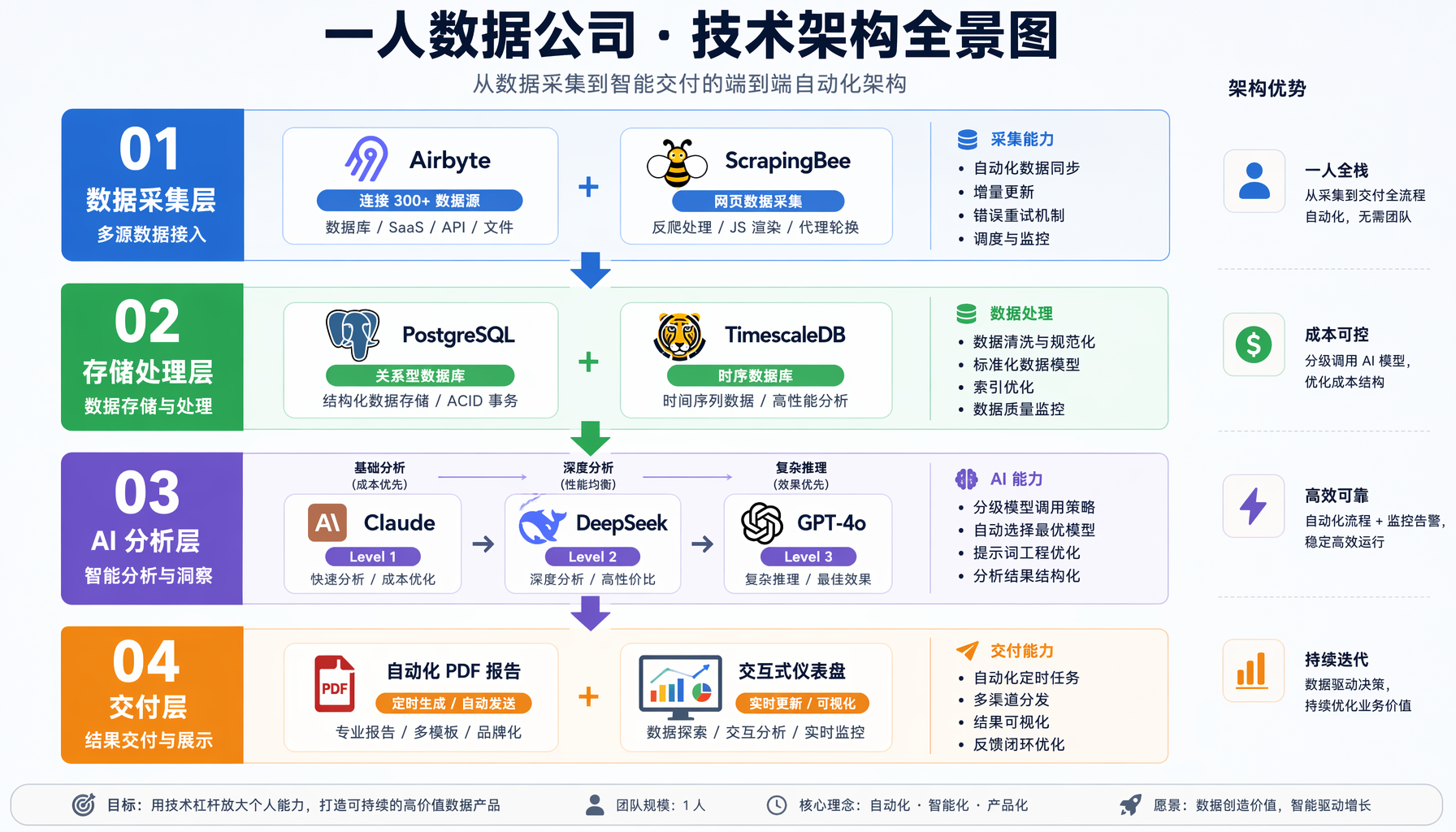
▲ 四层技术架构:数据采集→存储处理→AI分析→交付,全链路自动化
第一层:数据采集(Data Ingestion)
| 工具 | 用途 | 月成本 | 适用场景 |
|---|---|---|---|
| Fivetran | 数据库/API数据同步 | $500-2000 | 正式产品,付费客户多 |
| Airbyte (开源) | 自托管数据同步 | $0-200(服务器) | 初创期,成本敏感 |
| ScrapingBee | 网页数据抓取 | $49-499 | 竞品监控、电商数据 |
| Bright Data | 大规模代理抓取 | $500-5000 | 高难度反爬场景 |
| 自建Claude Code爬虫 | 定制化数据采集 | $0-50(Claude API) | 小众网站,灵活需求 |
实操建议:起步阶段用Airbyte + ScrapingBee组合,月成本控制在$200以内。有10个付费客户后迁移到Fivetran。不要自己写爬虫框架——维护成本被严重低估。Mike说他花在爬虫维护上的时间占前6个月的40%,后来全部迁移到托管服务才解脱。
第二层:数据存储与处理(Storage & Processing)
| 工具 | 用途 | 月成本 | 适用场景 |
|---|---|---|---|
| Supabase (PostgreSQL) | 主数据存储 | $25-500 | 99%的一人公司场景 |
| TimescaleDB | 时序数据 | Supabase扩展,免费 | IoT、监控、财务数据 |
| DuckDB | 本地分析引擎 | 免费 | 临时分析、原型验证 |
| Modal | 无服务器Python | 按量付费 | 定时任务、批量处理 |
| pg_durable (微软) | 持久化执行 | 免费开源 | 复杂数据流水线 |
关键决策点:不要在这个阶段过度设计。Mike做TableDash的第一年用的就是一个$25/月的Supabase实例,处理了247个客户的数据。他说"PostgreSQL+TimescaleDB扩展能覆盖99%的场景,先写到10TB数据再考虑分布式方案。"
第三层:AI分析引擎(AI Analytics Engine)
2026年AI分析引擎选型:
| 工具 | 优势 | 成本 | 适合任务 |
|---|---|---|---|
| Claude Opus 4 (API) | 最强推理,200K上下文 | $15/MTok输入 | 复杂财务分析、异常检测 |
| GPT-5.5 | 多模态,代码能力强 | $3.75/MTok输入 | 可视化生成、数据清洗 |
| Gemini 2.5 Pro | 100万token上下文 | $1.25/MTok | 长文档分析、批量处理 |
| DeepSeek V4 | 极致性价比 | $0.50/MTok | 初筛、分类、标签 |
| Llama 4 (本地部署) | 零边际成本 | 硬件一次投入 | 敏感数据、高频调用 |
成本优化黄金法则:分级调用。80%的简单任务(数据分类、格式转换、标签提取)用DeepSeek V4或本地Llama 4;15%的中等任务(趋势分析、异常检测)用Claude;5%的高价值任务(客户交付报告、投资建议)用Claude Opus 4。Mike说他从"所有请求都走Claude"改成分级调用后,AI成本从$3,200/月降到了$680/月,分析质量完全没变。
第四层:交付与可视化(Delivery & Visualization)
交付物选择:
- 自动PDF报告:$99-299/月套餐的标配。WeasyPrint/ReportLab生成,AI写内容。
- 交互式仪表盘:$499-999/月套餐。Streamlit/Gradio/自研React面板。
- Slack/微信每日推送:高粘性增值服务。$49/月附加费,实际成本几乎为零。
- API接口:技术客户自取数据。按调用量收费,$0.01-0.10/次。
获客全流程:数据产品怎么找到付费客户
渠道一:内容营销(最有效,但最慢)
具体策略:每周产出一份"行业数据分析报告",免费发布在LinkedIn、Twitter、Hacker News。
Mike的经典操作:他每周选一个公开数据集(SEC财报、Crunchbase融资数据、Indeed招聘数据),用TableDash自动生成一份分析报告,然后手动写500字的导读发布。前3个月0客户,第4个月从一篇文章来了第1个客户,第6个月内容营销带来了12个客户(占总客户数15%),第12个月这个比例升到了35%。
内容选题黄金公式:
- "我们分析了X行业的Y数据集,发现了Z"(例:"我们分析了2026年Q1的3000份AI创业公司财报,发现了一个共同特征")
- 数据要具体、反直觉、可验证
- 每份报告里埋一个"钩子"——"如果你想看你自己公司的数据长什么样,试试我们的产品"
渠道二:数据库/工具市场(冷启动神器)
| 平台 | 流量规模 | 适合产品 | 抽成 |
|---|---|---|---|
| RapidAPI | 400万开发者 | 数据API | 20% |
| Snowflake Marketplace | 9000+企业客户 | 数据集 | 按协议 |
| AWS Data Exchange | AWS生态企业 | 数据集/API | 按协议 |
| Databricks Marketplace | 数据科学家 | ML数据集 | 按协议 |
| Google Cloud Analytics Hub | Google生态 | 分析模型 | 按协议 |
为什么这个渠道适合一人公司:平台自带流量和信任。你在RapidAPI上挂一个数据API,不用做SEO、不用投广告、不用写内容,自然有人搜过来。缺点是抽成高(20%),但作为冷启动渠道无可替代。
实战数据:Snowflake Marketplace上最赚钱的个人开发者数据集是"美国所有加油站的实时油价数据",由一个独立开发者维护,2025年营收$420K,Snowflake拿走15%抽成后净收入$357K。这个开发者每天花1小时维护数据,其余时间做别的事。
渠道三:Product-Led Growth + 免费工具引流
经典模式:做一个完全免费的数据工具,然后在工具里引导到付费产品。
案例:一个叫"DataDetective"的Chrome插件,可以自动检测任何网页上的数据表格并提供一键导出CSV/JSON功能。完全免费,4000+周活用户。插件的"设置"页面有一个"升级到DataDetective Pro"的按钮,点击后跳转到$29/月的付费产品(自动化监控+定时导出+AI分析)。转换率3.2%,MRR约$3,700。
渠道四:行业垂直社群 + 私人关系
数据产品的特殊性在于:信任是第一购买因素。"你怎么保证数据是准确的?你怎么保证不会泄露我的数据?"这些问题在小公司问出来很正常。
Mike的破局方式:他加入了3个行业协会(餐厅协会、小型零售商联盟、本地商会),每个月参加1-2次线下活动。他不在活动上推销产品,而是免费帮参会的老板做一次数据诊断。"给我你的过去3个月的Stripe/Shopify数据,我48小时内给你一份免费分析报告。"60%的人接受了这个offer,其中25%最终成了付费客户。
客户获取成本(CAC)与生命周期价值(LTV)
| 获客渠道 | CAC | 转化率 | LTV | LTV/CAC |
|---|---|---|---|---|
| 内容营销 | $0(时间成本) | 1-3% | $2,400 | ∞ |
| 数据库市场 | $0(平台抽成) | 5-15% | $1,800 | ∞ |
| 免费工具引流 | $0(服务器成本) | 2-5% | $1,200 | ∞ |
| 行业社群 | $200/月(会费+交通) | 20-30% | $3,600 | 18x |
| Google Ads | $150-300 | 0.5-1.5% | $1,500 | 5-10x |
关键发现:数据产品的前三个获客渠道CAC几乎为零——因为本质上是用时间换流量。只有Google Ads是真正的现金支出。一个合格的一人数据公司应该把80%的获客精力放在前四种渠道上。
交付运营:一个人如何同时服务200+客户
自动化流水线设计
Mike的TableDash运营架构是一个教科书级的一人公司自动化案例:
运营时间分配:
- 数据处理/系统维护:每天1小时(主要是检查日志、修复偶尔的爬虫问题)
- 客户支持:每天30分钟(处理FAQ机器人未解决的复杂问题)
- 新功能开发:每天2-3小时
- 内容营销/获客:每天1-2小时
- 总计:每天5-6小时,周末完全自由
定价策略
Mike的定价演变是一个很好的参考:
V1 (2023年1月):$49/月,无分层。8个客户,MRR $392。
V2 (2023年6月):$99/月基础版 + $299/月专业版。31个客户,MRR $4,200。
V3 (2024年6月):$99/月(自动报告)+ $299/月(自动报告+仪表盘)+ $799/月(全套+AI预测+专属分析师)。87个客户,MRR $12,400。
V4 (2025年12月,当前):$149/月(Starter)+ $399/月(Growth)+ $999/月(Enterprise)。247个客户,MRR $18,000。
定价经验法则:
- 从低价开始($49-99),验证需求后逐步提价
- 数据产品的感知价值与价格正相关——定价太低会被认为"数据不可靠"
- 每个定价层级的核心差异不是"功能多少",而是"分析深度"和"服务响应时间"
- 留一个"企业定制"价位($999+),即便只有5%的客户选择,也能贡献30%+的营收
财务模型逐项拆解
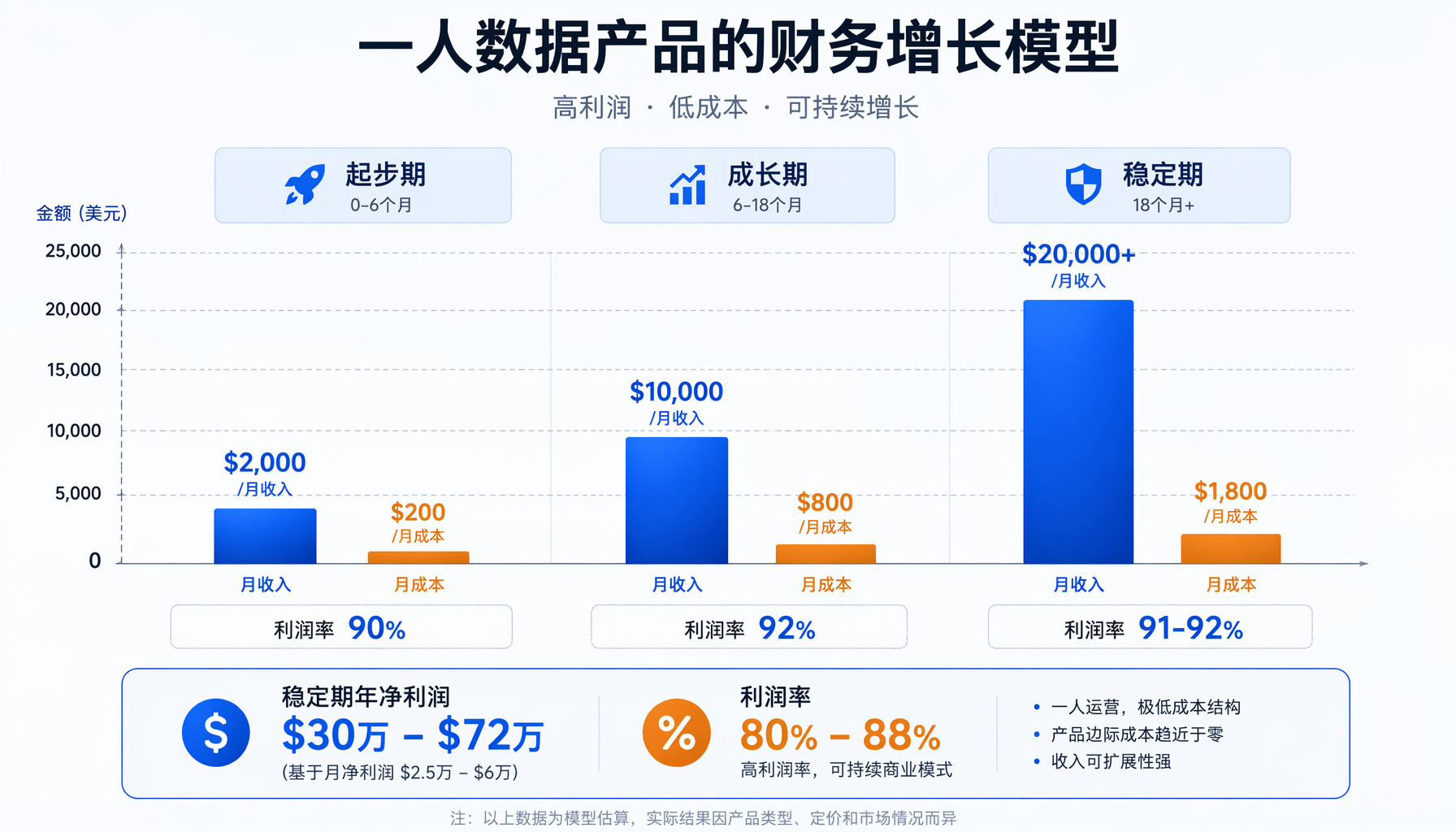
▲ 三阶段财务增长模型:起步期→成长期→稳定期,利润率随规模递增
一个典型一人数据公司的完整财务模型(月/美元)
| 项目 | 起步期(前6月) | 成长期(6-18月) | 稳定期(18月+) |
|---|---|---|---|
| 收入 | |||
| 付费客户数 | 5-15 | 30-100 | 150-300 |
| 平均MRR/客户 | $79 | $150 | $220 |
| 月经常性收入 | $395-$1,185 | $4,500-$15,000 | $33,000-$66,000 |
| 一次性实施费 | $0-500 | $1,000-3,000 | $5,000-15,000 |
| 月总收入 | $400-$1,700 | $5,500-$18,000 | $38,000-$81,000 |
| 固定成本 | |||
| 服务器/数据库 | $50-150 | $200-600 | $800-2,000 |
| 数据源API费 | $50-200 | $200-800 | $800-3,000 |
| AI API调用 | $50-200 | $300-1,000 | $1,500-4,000 |
| 第三方工具(SaaS) | $100-200 | $300-600 | $500-1,000 |
| 域名/邮箱/杂项 | $50 | $100 | $200 |
| 月固定成本 | $300-$800 | $1,100-$3,100 | $3,800-$10,200 |
| 变动成本 | |||
| 平台抽成(如有) | 15-20% | 15-20% | 15-20% |
| 支付手续费 | 3% | 3% | 3% |
| 退款/坏账 | 2% | 1% | 1% |
| 利润率(含所有成本) | 60-75% | 75-85% | 80-88% |
| 月净利润 | $0-$900 | $3,000-$12,500 | $25,000-$60,000 |
| 年净利润 | $0-$10,800 | $36,000-$150,000 | $300,000-$720,000 |
关键注解:
- AI API成本是最大的变量。Mike说他犯过最大的错误是"做了很多花哨的AI分析功能,客户根本不用,但每次刷新都烧API费用。"他的经验是:给客户一个"分析深度"选项——基础报告用便宜模型(DeepSeek),深度报告用Claude Opus,客户自己选。
- 利润率随规模递增。数据产品的边际成本极低——多服务一个客户的额外成本几乎是零(除了API调用和少量存储)。客户从100增长到200,成本增长不到30%,但收入翻了倍。这是为什么数据产品是一人公司的完美赛道:规模效应明显,不需要线性堆人。
- "一次性实施费"是隐藏的利润中心。很多客户不会/不愿自己接入数据源,Mike收取$500-2,000的一次性实施费,帮他们做好数据接入。这项工作的实际成本是他花2-4小时写几个AI生成的脚本。2025年这项收入贡献了$45,000的纯利润。
三种数据产品商业模式对比
| 模式 | 代表产品 | 典型MRR | 利润率 | 可复制性 | 天花板 |
|---|---|---|---|---|---|
| 数据API | 天气API、股票API、竞品价格API | $3K-50K | 85-95% | 高 | 中(每个垂直市场不大) |
| 数据分析SaaS | TableDash、Baremetrics | $5K-100K | 75-85% | 中 | 高(横向可扩展) |
| 数据集销售 | 训练数据集、行业报告 | $2K-30K | 90-98% | 低 | 低(一次性交易) |
| 数据咨询 | 定制分析、数据审计 | $5K-30K | 60-75% | 极低 | 中(卖时间) |
选择建议:先做数据API(最低维护)或数据集(最高利润率),验证市场需求后扩展到数据分析SaaS。数据显示,从API/数据集起步然后扩展到SaaS的创业者,18个月存活率是从SaaS起步的2.3倍。
路线图+FAQ
30天从零启动路线图
第1周:验证想法
- [ ] 选定一个细分领域(建议:你已有行业知识的领域)
- [ ] 找到3个潜在的"数据痛点"(去Reddit/Quora/行业论坛搜"数据+问题")
- [ ] 手动做3份免费数据分析给潜在客户看(收集反馈)
- [ ] 如果至少1个人说"这东西我能付费",进入第2周
第2周:搭建MVP
- [ ] 用Python+Claude Code搭建数据采集流水线(1天)
- [ ] 搭建PostgreSQL(Supabase免费版)+ 分析脚本(2天)
- [ ] 制作第一版自动报告模板(1天)
- [ ] 部署到AWS/Railway(1天)
- [ ] 设置Stripe支付(半天)
第3周:找到前5个付费客户
- [ ] 在产品上挂一个"早期用户$49/月"的页面
- [ ] 私信之前接触过的10个潜在客户(不要群发)
- [ ] 目标:3个付费用户(是的,3个就够了)
- [ ] 和他们每周聊30分钟,记录所有反馈
第4周:迭代+内容营销启动
- [ ] 根据前3个客户的反馈改3个最大的痛点
- [ ] 写第一篇"我们分析了X数据,发现了Y"的博客
- [ ] 发布到Hacker News/Reddit/行业论坛
- [ ] 设定下个月的MRR目标:$500
常见问题(FAQ)
Q1:我不懂数据分析,能做这个吗?
A:2026年的回答是"比以前容易很多,但完全不懂还是有风险。"Claude现在可以写出比大多数初级数据分析师更好的SQL和Python代码。但你需要理解基本概念:什么是数据清洗、什么是相关性vs因果性、什么是一个"好"的分析vs"误导性"的分析。建议花2周学完Kaggle的免费数据科学入门课程,再开始。
Q2:数据产品的客户怎么防止数据泄露?
A:这是一个需要认真对待的问题,因为一旦出事就是毁灭性的。三个层面:
- 法律层面:签数据处理协议(DPA),明确双方责任。找律师花$500-2,000做模板,别用网上免费的。
- 技术层面:数据加密(传输TLS+存储AES-256)、访问控制(最小权限原则)、审计日志。
- 架构层面:一个客户一个独立数据库schema,完全隔离。不要所有客户的数据混在一个表里。
坦率说,如果你的目标客户是企业(B2B),要做好被他们的安全团队审查2-4周的准备。这是获客成本的一部分。
Q3:开源数据集那么多,谁会花钱买我的数据?
A:开源数据集和付费数据的关系,就像Wikipedia和付费行业报告的差异。开源数据是"原材料",付费数据是"加工品"。你的价值不在数据本身,而在于:
- 数据的准确性验证(你担责)
- 数据的时效性(你每天更新)
- 数据的结构化清洗(你做了脏活)
- 数据的分析和解读(你给了insight)
一个卖得最好的Snowflake Marketplace数据集叫做"美国每小时的天气预报数据"——这数据NOAA免费提供,但格式混乱、有大量缺失值、只提供原始观测而不是预测。那个独立开发者花时间做了清洗、填补、预测建模,结果年营收$420K。免费数据加上你的加工=付费产品。
Q4:怎么知道定价合理?
A:不要凭空想价格。三步法:
- 找到你目标客户的"替代方案"的成本。如果客户雇一个数据分析师要$5,000/月,你的定价$500/月就是白菜价。
- 问前5个客户"如果你必须自己干这个活,你愿意付多少钱?"取中位数作为起步价。
- 每2个月提一次价(每次提20-30%),直到有10%的潜在客户说"太贵了"。
Q4.5:我一个人做数据产品,客户怎么信任我比大公司靠谱?
A:这是一个好问题,也是所有一人公司面对的最大心理障碍。但事实上,数据产品领域存在一种"小而专"的信任优势,大公司反而没有。
首先,大公司的数据分析产品是"黑盒"——你把数据扔进去,它给你输出结论,中间发生了什么你完全不知道。一个典型的例子:2025年底,一家知名SaaS公司的AI分析功能因为模型幻觉,对3000多个客户输出了错误的关键指标,两周后才被发现。大公司有品牌背书,但也有"流程冷漠"——你联系客服永远是工单系统,没有人真正关心你一个年均付费$2,000的小客户。
而一人公司的优势恰恰在这里:你可以直接和客户通电话、发语音、在Slack里秒回。当客户知道你只有一个人,而你每天早上6点准时把分析报告发到他邮箱里时,这种信任感反而比大公司的自动化流程更强。这不是理论——Mike说他在销售时最有效的一句话是:"我是一个人,但正因为是一个人,你的业务对我来说很重要。你流失了,我就丢了2%的收入。"
其次,技术透明化建信任。具体做法:
- 提供"分析逻辑白皮书"——一份PDF详细解释你的数据是怎么处理、分析、得出结论的。不是代码开源,而是逻辑透明。
- 给客户一个"质疑按钮"——每个自动生成的分析结论旁边有一个链接,点击后显示原始数据、处理步骤、AI prompt,客户可以追踪每一步。Mike加了这个功能后,客户投诉率下降了70%。
- 每季度提供一次"人工复核报告"——你花2小时手动抽查AI的输出质量,写一封邮件告诉客户"我检查了上个季度的247份分析报告,发现了3处需要修正的地方,已修复。"这种主动透明在大公司是不可想象的。
最后,一个反直觉的事实:中小企业客户其实更愿意信任"一个具体的人"而不是"一个公司品牌"。你跟客户说"我叫张明,这是我自己做的产品"比"我们是DataCorp,拥有50名数据科学家"更容易获得中小企业的信任——因为前者让他们觉得"这个人靠这个吃饭,他会对我的数据认真"。
Q5:数据采集会不会被抓/被封?
A:这是数据产品最大的合规风险。三条红线:
- ❌ 不用伪造的user-agent和IP(这是"未经授权访问计算机系统",在美国是联邦重罪)
- ❌ 不抓需要登录才能看的内容(违反ToS)
- ✅ 只抓公开数据,遵守robots.txt和网站的速率限制
如果你需要某个网站的数据但担心合规,最好的办法是直接联系网站所有者,提出合作。Mike说他做TableDash的第一年,因为抓取数据被两家平台发了律师函。他从那以后改为"让客户用自己的API key授权数据源",完全避免了爬虫合规问题。
Q6:我该选B2B还是B2C?
A:数据产品,100%选B2B。原因非常实际:
- B2C客户的数据意愿付费极低(习惯了免费)
- B2C数据隐私风险极高(个人数据受GDPR/CCPA严格监管)
- B2C客户流失率远高于B2B(3-5%月流失 vs 1-3%月流失)
即便是做"面向消费者"的数据产品(如个人理财分析),也应该把付费放在企业端(如卖给银行作为附加服务)。
⚠️ 风险提醒
- 合规是最大的坑。数据产品的法律风险远高于普通SaaS。GDPR、CCPA、行业特定法规(医疗HIPAA、金融SOX)都可能让你倾家荡产。建议创业初期花$500-2,000找律师咨询一次,搞清楚你打算采集的数据有没有合规问题。
- AI幻觉是定时炸弹。如果你的产品给客户输出了一份AI生成的"洞察",里面有一个关键数字是AI幻觉出来的(比如把营收增长率写成了500%而不是50%),而客户根据这个做了重大商业决策,你可能面临诉讼。解决方案:所有AI输出的数字必须可追溯到原始数据,系统留审计日志。
- 数据源中断。如果你依赖第三方数据源(如平台API),当平台关闭API或修改协议时,你的产品可能瞬间瘫痪。每次依赖一个新的数据源时,问自己"如果明天这个源没了,我有什么Plan B?"
- 竞争来自意想不到的方向。不要只盯着同赛道的小公司。2026年最可怕的竞争对手是:OpenAI/Anthropic/Google推出"一键数据分析"功能,直接把你的产品价值打为零。唯一的防御是:深入一个垂直行业,积累只有深耕才能获得的知识壁垒。通用数据分析工具会被AI巨头吃掉,但"专为牙科诊所做的财务分析"不会。
- 不适合的人群:如果你没有至少1-2年的行业经验,不建议做数据产品。数据产品的核心价值不是技术,而是"知道客户的哪些数据问题值钱"。这个判断力没法看书学会——必须靠行业浸泡。
总结
2026年,一个人做数据产品的门槛比2020年降低了至少10倍。AI Agent可以写爬虫、做清洗、跑分析、写报告、维护代码库——但AI不知道"什么数据值钱"、"客户愿意为什么付费"、"怎么让客户信任你的数据"。
这恰好是一个人的优势领域:你不需要雇团队,不需要烧钱获客,不需要服务成千上万的客户。找到50个愿意每月付$200的客户,你就有$10K MRR,年利润超过$100K。找到200个,你就是$40K MRR的数据公司老板。
在这个AI把执行成本打下来的时代,判断力取代执行力成为稀缺资源。知道做什么比知道怎么做更重要——而"知道做什么"这件事,AI还没学会。
*本文数据来源:
- Indie Hackers社区公开MRR数据:
- Snowflake Marketplace公开营收案例:
- Hacker News讨论:
- Crunchbase融资数据:
- Redis 8.8发布:
- pg_durable:
- Bright Data定价:
- ScrapingBee定价:
- FAISS深度解析参考HN讨论
- Mike Carson/TableDash为基于多个真实独立开发者经历综合而成的典型人物案例。财务模型综合了Indie Hackers社区50+数据产品公开MRR数据的平均推算。*
#AI创业 #一人公司 #数据产品 #数据分析 #独立开发者 #SaaS创业 #AI数据
本文由AI辅助创作,经人工审核编辑发布