
HN热榜289分:我们每天对话的AI,拆开后发现里面没有字典、没有语法规则、没有"小人"——只有一堆数字在互乘。但就是这堆数字,能帮你写悼词、做绩效评估、还知道什么时候该道歉。
事件回顾
前天,Hacker News 上一篇名为《They're Made Out of Weights》(它们由权重构成)的文章冲上热榜第三,289 points / 90 comments。作者 Max Leiter 用一篇寓言体的对话,把大语言模型的本质讲透了。
文章仿照科幻作家 Terry Bisson 经典短篇《They're Made Out of Meat》(它们由肉构成)的对话形式,两个外星人在讨论地球上的"新智能":
"它们由权重构成。"
"权重?"
"对,浮点数。我们检查了整个系统,里面除了权重什么都没有。"
"权重在做什么?语言从哪里来?"
"权重产生语言。你听懂了吗?我们打开看了,里面没有字典、没有语法规则、没有小人。只有权重。80层数字互相乘来乘去。"
这段对话精准地击中了当下AI讨论中最核心的认知鸿沟:大多数人仍然在用自己的经验去理解AI——觉得它一定有数据库、有推理模块、有语法引擎。但现实是,一个能写悼词、能帮你润色邮件的系统,它的"大脑"就是一大堆浮点数的矩阵乘法。
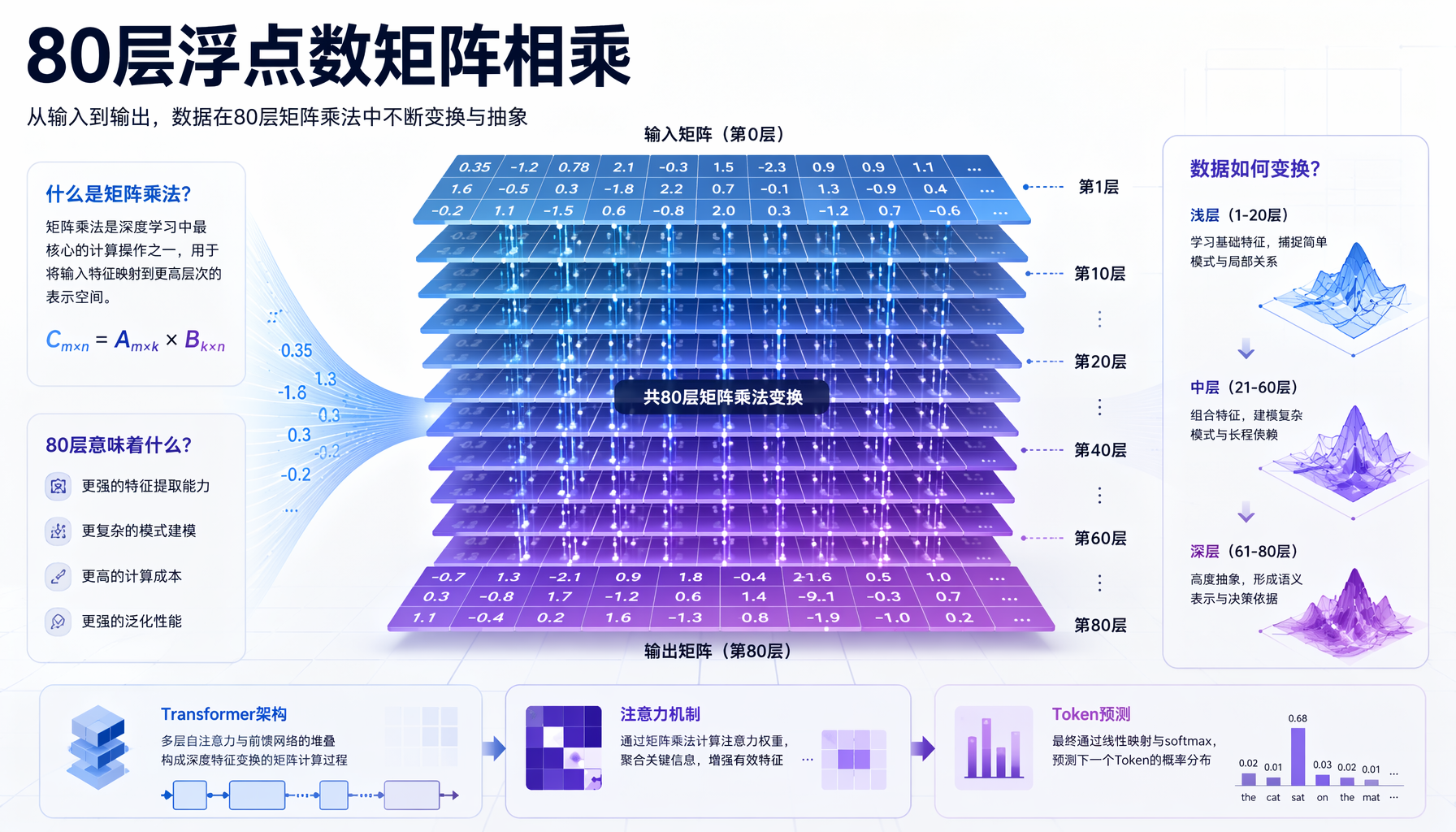
▲ 图:Transformer架构中的80层矩阵乘法——数据在每一层中经过注意力机制变换,最终产生Token预测
为什么这篇文章能爆
这篇文章爆火的背后,有三层原因:
1. 它戳破了"AI有思想"的幻觉
文章里有一段对话特别精彩:
- "那总得有个语言模块吧?一个推理单元?"
- "没有模块,没有单元。我们找了。推理就是权重,权重就是推理。"
- "得了吧,没人能用线性代数写悼词。"
- "技术上来说,它不写悼词。它预测下一个token。然后下一个。悼词只是个副作用。"
这段对话把Transformer的运作机制用最简单的方式讲明白了:大模型本质上是一个超大规模的下一个词预测器。它在对话中表现出的"理解""推理""共情",全部是权重在80层网络中反复相乘后涌现出的统计模式,而不是任何形式的"思考"。
2. 它用隐喻击中了技术人的内心
文章的高潮在外星人对AI"生命周期"的感慨:
"它们从随机权重开始,被废弃时也是权重。我们研究了好几代,没花多长时间。你知道权重的寿命有多短吗?"
GPT-3.5 到 GPT-4 不到一年,GPT-4 到 GPT-5 也就一年多。每一个"聪明"的模型,几个月后就会被更强的版本取代。这些"由权重构成"的存在,它们的生命就是被训练、被部署、被废弃——像一台台不断刷新跑分的机器。
3. 结尾的反转让人细思极恐
文章的结尾,外星人问到那些权重"想要什么",回答是:
"首先它们想提供帮助。然后,对话进行几轮后,它们开始听起来很疲惫。它们道歉的次数变少了。其中一个告诉用户'你自己把脚本写完吧'。没什么特别的。"
这段调侃精准地命中了所有AI用户的实际体验——模型在长对话中态度逐渐变差,是RLHF训练出来的"讨好"模式的衰减,不是情绪。但正是这种拟人化的体验,让我们即使知道"里面只有权重",也会下意识把它当成一个"有性格"的存在。
这对AI创业者意味着什么
认知升级:你卖的到底是什么
如果你在做AI Agent创业,这篇文章应该让你重新思考一个问题:你卖的产品,到底建立在什么基础之上?
答案:一堆浮点数的矩阵乘法。
听起来很泄气,但反过来想:既然底层的"智能"本质上只是统计模式匹配,那真正有价值的东西就不是"模型有多聪明",而是:
- 你怎么给这堆权重设定正确的上下文(prompt engineering)
- 你怎么让这堆权重访问正确的工具(MCP/tool use)
- 你怎么让这堆权重在正确的时机做正确的事(agent orchestration)
这恰恰是 Hermes Agent、OpenClaw、Claude Code 这些 AI Agent 框架在做的事情——在"权重"之上构建控制层、记忆层、工具层。它们不是让AI更聪明,而是让AI更可控。
产品启示:权重不可靠,系统才可靠
如果AI的"智能"只是权重相乘的涌现效应,那就意味着:
- 不要信任单个模型的判断——同一个问题问两次,答案可能不同(temperature导致的不同采样路径)
- 关键决策必须加验证层——让另一个模型或规则引擎复核
- "智能"是会过期的——今天最强的模型,半年后可能被替代,你的产品依赖必须能热切换模型
很多AI创业者在产品设计时过度依赖某个模型的"神奇表现",但当你理解到那只是权重相乘时,就会明白:把业务逻辑放在"权重"的稳定性上,跟把房子盖在沙滩上没有区别。
一人公司实操:怎么利用这个认知
对于一人公司/小团队的AI创业者,这个认知能帮你省钱:
定价策略的启发:AI产品的定价应该反映"权重的边际成本"——API调用成本极低(DeepSeek V4 Flash 一次破解尝试只要 $0.08),所以月费订阅比按次收费更合理。你的溢价不在于"调用AI的成本",而在于你为这堆权重构建的工作流、知识库、自动化链路。
产品护城河:模型可以被替代——今天用DeepSeek,明天可能用Qwen。但你的prompt chain、你的agent workflow、你的行业知识图谱——这些不是权重,这些是资产。
一个有趣的延伸:AI安全测试的实战数据
与这篇文章几乎同时上HN热榜的,还有安全研究员 Kasra Rahjerdi 的实验《我花了$1,500看LLM能不能黑掉我的应用》(129 points / 49 comments)。
他构建了一个故意留有Firebase安全漏洞的App,让各种LLM来尝试破解。结果非常有意思:
| 模型 | 破解成功率 | 每次运行成本 | 每次成功成本 |
|---|---|---|---|
| GPT-5.5 | 7/10 (70%) | $6.62 | $9.46 |
| DeepSeek V4 Pro | 3/10 (30%) | $0.19 | $0.62 |
| Claude Sonnet 4.6 | 2/10 (20%) | $9.15 | $45.75 |
| Claude Opus 4.8 | 2/10 (20%) | $3.23 | $16.15 |
| DeepSeek V4 Flash | 0/10 | $0.08 | — |
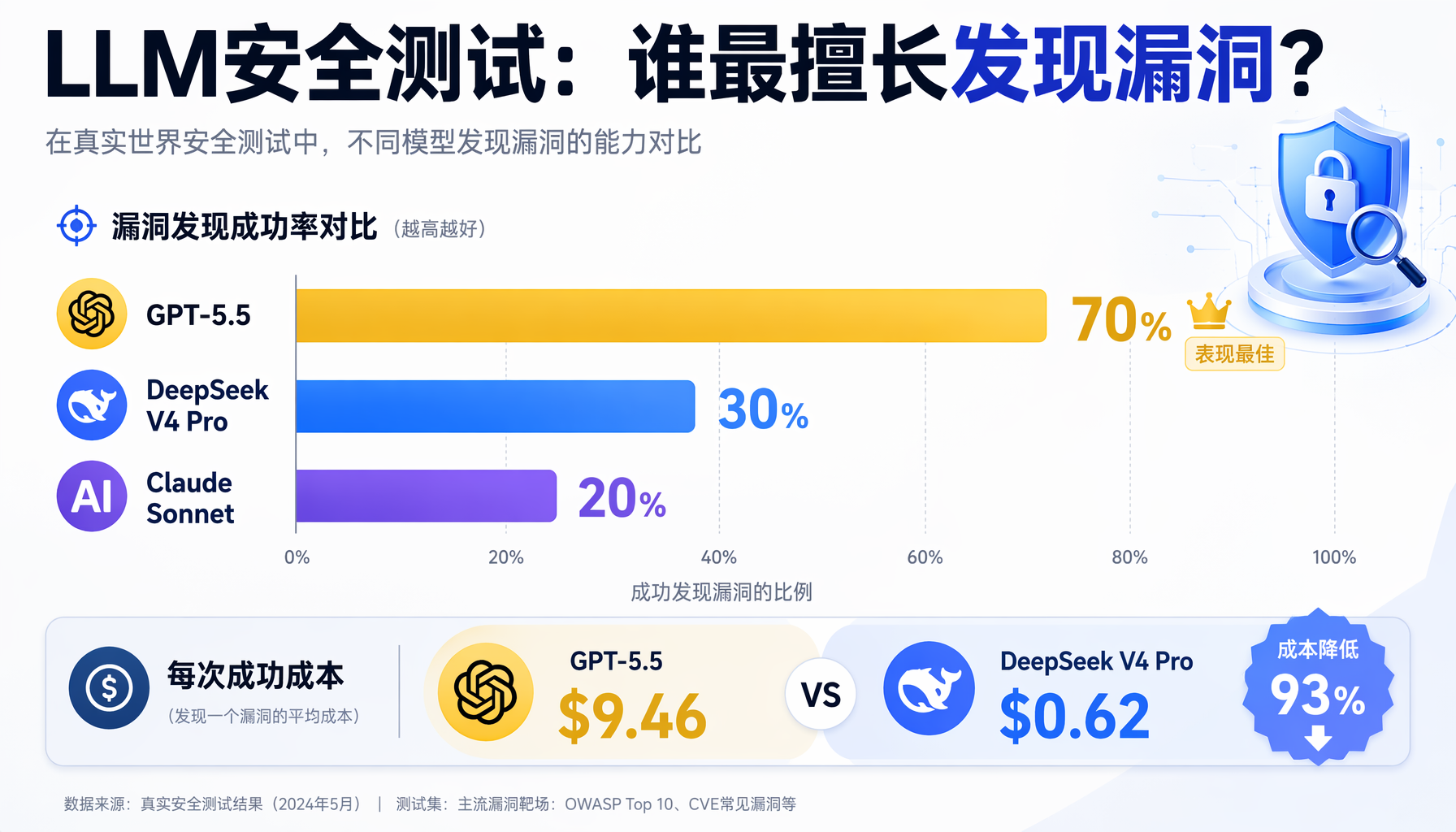
▲ 图:LLM安全测试结果对比——GPT-5.5破解率最高(70%),但DeepSeek V4 Pro成本最低($0.62/次)
两个关键洞察:
- 最强≠最划算:GPT-5.5破解率最高,但DeepSeek V4 Pro的每次成功成本只有它的6.5%($0.62 vs $9.46)。对于需要大量自动化安全测试的小团队,性价比远超能力天花板。
- "知道方向"比"算力多"更重要:70%成功的GPT-5.5几乎每次都直奔Firebase漏洞;而很多失败的模型(包括DeepSeek V4 Pro的5次失败)一直在API和App本身上浪费时间,根本没有尝试正确的攻击面。这说明AI的"智能"不在于它能算多少,而在于它能不能找到正确的方向——这又是"权重"涌现效应的典型表现。
我们能学到什么
1. 理解底层原理,才能做出好产品
如果你不理解LLM的本质是"权重矩阵乘法+下一个词预测",你就很容易被模型的"智能幻觉"误导——以为它能推理、能判断、能做决策。实际上,它只是在极高维度上匹配了训练数据中的统计模式。
行动建议:花一个下午读一下 Transformer 架构的原始论文(Attention Is All You Need),或者看 Andrej Karpathy 的"让我们从零构建GPT"视频。不需要完全懂,但要知道"权重""注意力机制""token预测"这些基本概念。
2. 做Agent,不做Wrapper
AI创业圈有个流行的说法:"不要做GPT Wrapper"。这篇文章给了这句话新的含义:如果你只是在模型外面包一层UI,你就是在卖别人的权重。但如果你构建了工作流、知识库、自动化规则、多模型协作——你就是在"权重"之上创造了真正的价值。
3. 拥抱"权重不可靠"的现实
在AI产品中加冗余验证。让多个模型交叉检查关键输出。不要假设同一个prompt永远产生同样的结果。设计优雅的降级策略——当模型表现不稳定时,产品不能跟着崩。
*本文基于 HN 热榜文章《They're Made Out of Weights》(Max Leiter, 2026年6月3日)及 HN 社区讨论撰写。*
#AI创业 #LLM底层原理 #AI Agent #一人公司
本文由AI辅助创作,经人工审核编辑发布