
每个Agent教程都教你写一个10行的while循环。Claude Code的query.ts告诉你为什么生产环境需要1400行。
前言
如果你正在构建AI Agent产品,你一定写过这样的代码:
10行代码,一个完整的Agent循环。Demo跑得完美,然后你把它部署到生产环境。
第一天,API超时了,Agent直接崩溃。第二天,上下文窗口满了,Agent开始丢记忆。第三天,一个bash脚本卡死了,整个进程冻结。第四天,用户合上笔记本盖子,会话永远丢失。
你开始往循环里加代码。重试逻辑、超时处理、上下文压缩、会话恢复、治理钩子……不知不觉,你的循环也快1400行了。
2026年3月,Claude Code的npm源码映射意外暴露,社区工程师发现其核心Agent逻辑文件query.ts中,一个while(true)循环超过了1400行TypeScript代码[1]。这不是过度工程——每一行都对应一个真实的生产故障。
本文将深入拆解这个循环,教你如何把一个10行的Demo循环升级为生产级Agent引擎。
一、从Demo到地狱:为什么10行循环不够
1.1 天真的开始
所有Agent教程的起点都一样:调LLM → 检查是否需要工具 → 执行工具 → 把结果喂回去 → 继续。在受控环境下——API稳定、任务简单、上下文充足——这完全够用。
1.2 生产的九种打击
但当Agent真正跑在生产环境时,现实会给你九种不同类型的打击:
| # | 故障类型 | 天真的循环会怎样 | Claude Code怎么做 |
|---|---|---|---|
| 1 | API超时/网络抖动 | 直接崩溃 | 指数退避重试,最多10次,用户无感知 |
| 2 | 上下文窗口满了 | 新消息被截断 | 4级压缩流水线,先便宜后贵 |
| 3 | 输出token达到上限 | 模型话说一半就停了 | 检测stop_reason=max_tokens,自动继续 |
| 4 | bash脚本无限卡死 | 进程冻结,Ctrl+C是唯一出路 | 单线程协作式的代价——事件循环等待脚本退出 |
| 5 | 用户合上笔记本 | 会话丢失 | JSONL实时持久化,resume精确恢复 |
| 6 | Token预算耗尽 | 突然报错,任务中断 | 主动注入预算警告,提醒模型收尾 |
| 7 | 工具执行被治理钩子拒绝 | 无感知,Agent逻辑错乱 | 拒绝作为工具结果注入,模型重新推理 |
| 8 | 子Agent任务完成 | 父Agent不知道 | Task工具完成后父循环自动继续 |
| 9 | 模型主动说"我做完了" | 循环结束 | stop hook可以覆盖模型决定,强制继续 |

▲ 图1:Demo级Agent循环 vs 生产环境的九种打击——每一行代码对应一个真实故障
每一个条件都对应query.ts中的一段生产代码。这篇文章逐一拆解。
二、架构基石:三个被写进函数签名的决策
2.1 Async Generator:流式事件,而非缓冲输出
这个函数签名包含了两个关键设计决策[1]:
决策一:类型化事件流,不缓存。 循环yield出的事件类型包括:文本token、工具调用、工具结果、压缩标记、墓碑消息。每个事件立即渲染到终端——用户在API返回的第一个字符就能看到输出,没有任何缓冲。
决策二:类型化的退出原因。 循环返回的不是void,而是Terminal枚举。它明确告诉调用方为什么停止:任务完成?上下文耗尽?用户中断?预算用光?会话恢复、远程控制重连、resume行为全部依赖这个返回值。
2.2 单线程:没有竞态条件的设计赌注
Claude Code的Agent循环是严格的单线程:一个实例、一个线程、一个循环[1]。没有并发操作间的共享可变状态,没有锁,没有竞态条件。
这是一个刻意的设计取舍:并行增加吞吐量,但也引入共享状态——工具A写到file.txt的同时,工具B也在写同一个文件。共享状态带来了一整类并行设计无法消除的bug。Anthropic选择了确定性、单线程的正确性,而非激进的并行吞吐。
这个取舍的代价是明确的:一个bash工具跑了死循环、一个同步操作阻塞了几分钟、一个没有退出条件的脚本——这些都不能被循环内部中断。事件循环会冻结直到操作完成或用户按Ctrl+C。
2.3 启动成本:8K-12K tokens在你打第一个字之前
在用户看到提示符之前,Claude Code已经执行了复杂的十步初始化[1]:
- 按优先级层级加载设置(管理策略是不可变覆盖层)
- 递归遍历目录树寻找项目级规则、memory文件、MCP配置
- 聚合所有状态后组装system prompt
在你敲第一个字之前,已经消耗了8,000到12,000个token。
在200K上下文窗口上,这是4-6%。在32K窗口上,这是25-37%——直接限制了第一个token发出前就能完成什么任务。
关键细节:CLAUDE.md作为用户消息注入,不是system prompt的一部分[1]。模型把system prompt内容当作配置,把用户消息内容当作上下文。这个区别影响模型遵循CLAUDE.md指令的严格程度。
系统prompt不是单一字符串。Claude Code根据你的环境、设置和活跃上下文,从条件片段组装它。基础system角色定义约2,900 tokens,18+工具的定义再加约3,000 tokens,CLAUDE.md内容再加500-2,000。组装后的prompt是一份密集的技术文档:行为规则、工具使用哲学、编码风格指南。"三行相似代码优于过早抽象"——这句话直接写在system prompt里[1]。
三、九个条件深度拆解
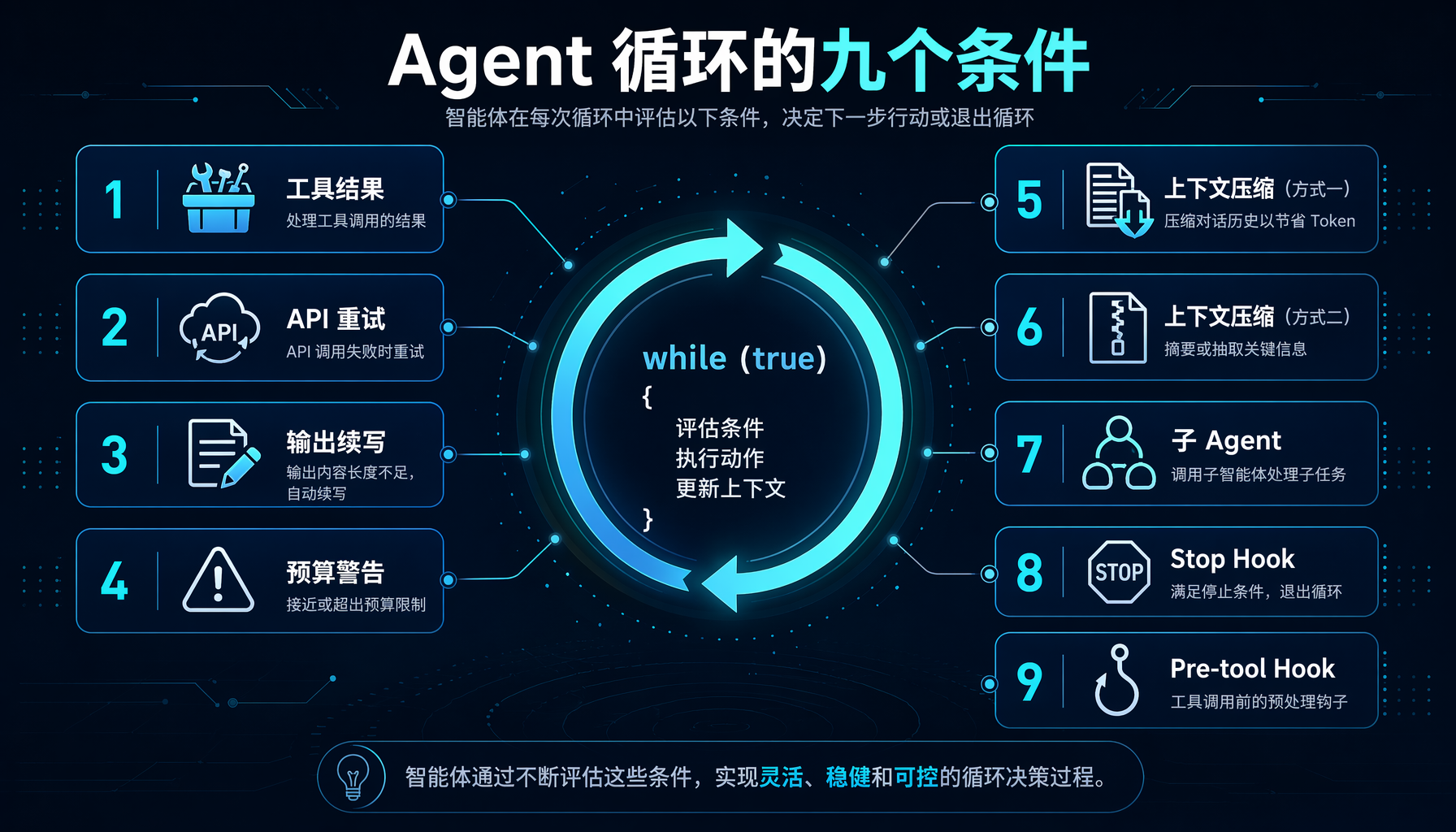
▲ 图2:while(true)循环的九个自动继续条件——每个都始于一个bug报告
条件①:工具结果返回——Agent循环的核心
这是最基础的:模型调用了工具,工具执行完毕,结果注入回上下文。循环继续,让模型基于结果决定下一步。这是Agent模式的核心[1]。
条件②:API错误或网络失败——静默重试
当API请求失败时,循环以指数退避自动重试,最多10次。用户完全无感知。这消除了Agent最常见的崩溃原因:临时网络抖动。
你的Agent应该有的东西:一个带退避的重试装饰器,对用户完全透明。
条件③:输出token到达上限——自动续写
模型输出被截断了(stop_reason: max_tokens),但任务还没完成。API用这个信号告知循环,循环自动继续让模型完成剩余内容[1]。
条件④:Token预算警告——提前通知
当会话接近上下文限制时,循环注入一条警告,告诉模型"该收尾了",然后继续运行让模型读到这条警告并执行[1]。这比突然崩溃优雅得多。
条件⑤-⑥:上下文压缩——两级安全系统
这是整个循环中最复杂的部分。当上下文窗口满了,循环不会崩溃——它压缩。
四级主动压缩(从最便宜到最贵依次尝试)[1]:
| 级别 | 策略 | 需要模型调用? | 说明 |
|---|---|---|---|
| 1 | Tool Result Budget | ❌ | 截断过大的工具输出 |
| 2 | Snip Compaction | ❌ | 删除旧的工具结果 |
| 3 | Microcompaction | ✅ | 每次压缩一个对话轮次 |
| 4 | Autocompact | ✅ | Session Memory Compaction提取关键事实,失败则全对话压缩 |
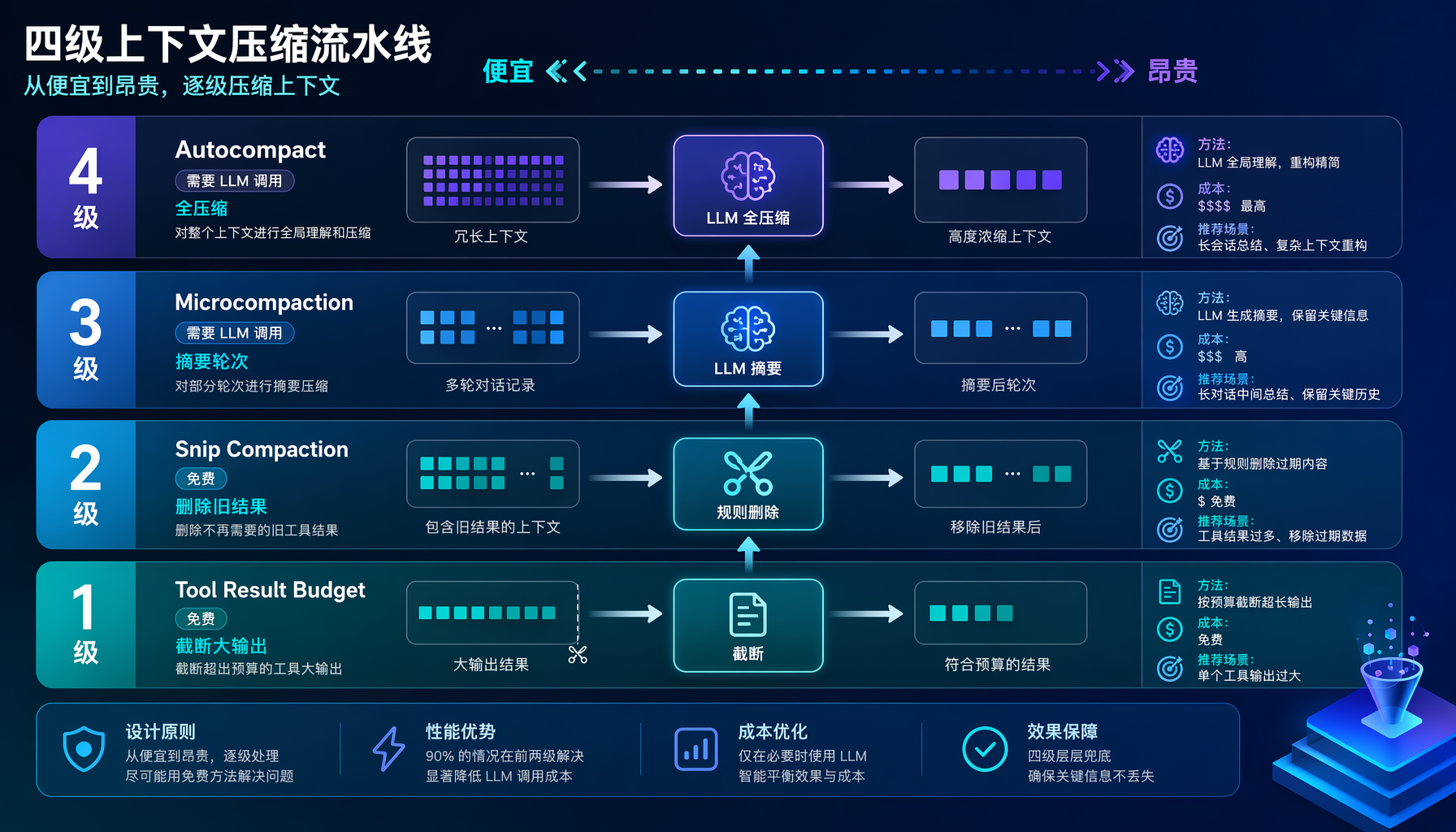
▲ 图3:四级上下文压缩流水线——从便宜到昂贵,90%的情况在前两级解决
这个顺序不是随意的——用尽便宜的选择,才为昂贵的付钱。
被动压缩只在API返回413(上下文太大)时触发,此时主动策略已全部尝试过且不够。循环执行一次全上下文压缩后继续。hasAttemptedReactiveCompact这个断路器确保被动压缩只执行一次——第二次413就是终止条件[1]。
把它理解为一个两级安全系统
条件⑦:子Agent完成——上下文高效的分身术
子Agent内部运行自己的完整循环,可能在复杂任务上消耗100K+ token,但只返回一个摘要(约1,000-2,000 token)给父Agent[1]。父Agent为摘要付费,而不是为子Agent的全部工作付费。
这就是Task工具为何是单线程系统中并行化的正确原语:每个子Agent有自己的隔离上下文窗口。但代价是:父Agent看不到子Agent工作过程中的中间步骤和决策[1]。
条件⑧:Stop Hook覆盖——治理层,模型无法绕过
当模型发出"我做完了"的信号时,用户定义的stop hook可以覆盖这个决定,让循环继续运行。这是模型无法绕过的治理层。
条件⑨:Pre-tool Hook拦截——工具执行前的最后一道防线
一个钩子拦截了工具调用,在执行前拒绝了它。拒绝作为工具结果注入上下文。循环继续,让模型为"被拒绝"这个结果重新推理[1]。
四、双模型流水线与Prompt缓存
4.1 两个模型,一个流水线
每个推理轮次都走Opus级模型(claude-opus-4-6,基于v2.1.88源码分析)[1]。Opus看到完整system prompt、全部工具目录和对话历史。它决定下一步做什么。
一个小型、更快的模型处理恰好两件事:
- 预热请求:会话开始时发送一个故意截断的API调用(
stop_reason: max_tokens)。响应内容无关紧要——这是一个健康检查,验证API可达且配额有效。 - 文件路径提取:bash命令产生输出后,识别哪些文件路径出现在结果中。prompt简洁且单一目的(v2.1.88中179个词)。
大模型做推理,小模型做杂务。
4.2 Prompt缓存:让模型"记住"的秘密
Claude Code使用激进的prompt缓存。内容块携带cache_control断点。第一次写入服务端缓存,成本1.25倍;后续匹配前缀的请求只需约10%的正常成本[1]。
在观察到的会话trace中,每个轮次90%或更多的token来自缓存。没有缓存,长会话的经济性将是毁灭性的。Prompt缓存是让模型"感觉像是在记住会话"的东西——尽管每次API调用时它都是无状态的。
五、会话持久化:不丢任何一次对话
5.1 实时JSONL写入
每条消息、每个工具调用、每个结果都实时写入~/.claude/projects/下的JSONL文件——发生在事件发生时,而非会话结束时[1]。
三重依赖:
claude --resume:在中断点精确重建对话状态--fork-session:在任意选定点把历史复制进新会话,原会话不变- 远程控制:笔记本休眠后醒来,自动重连——因为会话状态在磁盘上,不在内存里
5.2 墓碑消息
前面提到的generator签名中的TombstoneMessage类型连接的就是这个日志。当压缩删除消息时,它们的墓碑留在JSONL中,保证压缩后的回放日志依然一致[1]。
六、对比:其他Agent循环如何解决同样的问题
6.1 Hermes Agent:并行优先
Hermes Agent(Nous Research,MIT许可证)在并行性上采取了不同立场。当模型请求多个工具时,Hermes通过线程池并行执行,而非顺序执行[1]。
吞吐量提升是真实的。但风险也是:两个工具并行执行时,可能同时写同一个文件。工具输出中的竞态条件是一整类Claude Code单线程模型不可能产生的bug。
6.2 LangGraph:显式人机协作
LangGraph不是Agent循环——它是构建Agent循环的框架。人机协作暂停是显式的:interrupt()停止执行,Command(resume=value)继续[1]。
Claude Code的权限系统是隐式的,内部处理,不需要定义图。显式方法更可调试;隐式方法需要更少的设置。
6.3 核心差异总结
| 维度 | Claude Code | Hermes Agent | LangGraph |
|---|---|---|---|
| 并行策略 | 单线程 | 线程池 | 图定义 |
| 竞态条件风险 | 零 | 存在(同文件写入) | 取决于图设计 |
| 模型绑定 | Anthropic独占 | 跨厂商 | 框架无关 |
| 人机协作 | 隐式权限 | 隐式 | 显式interrupt |
| 许可证 | 闭源 | MIT | Apache 2.0 |
七、实战:给你的Agent循环加上生产防护
基于Claude Code的设计,这里是一个最小可用的生产级Agent循环升级指南。
7.1 第一层:基础防护(10分钟)
7.2 第二层:上下文压缩(20分钟)
7.3 第三层:会话持久化(15分钟)
7.4 第四层:治理钩子(30分钟)
八、踩坑与排障
坑1:重试时忘记重置计数器
症状:成功请求后,下次网络抖动立即达到max_retries上限。
修复:每次成功请求后立即把retries重置为0。见7.1代码中的retries = 0。
坑2:上下文压缩删除了关键信息
症状:用户说"Agent好像失忆了,重复做已经完成的事情"。
修复:压缩前用Session Memory Compaction提取关键事实(任务目标、已完成步骤、待办事项),把摘要保留而删除原文。Claude Code的Autocompact就是这样做的。
坑3:并行工具执行导致文件冲突
症状:两个工具同时写文件,最终内容交错损坏。
修复:要么像Claude Code一样串行执行工具(牺牲吞吐量换正确性),要么为每个文件加锁:
坑4:预热请求浪费配额
症状:每次会话开始都有一个失败的API调用,消耗token。
修复:用最小prompt做预热(1-2个token),或用普通GET请求替代(如果API支持health check端点)。权衡:预热确认了API可用性,避免用户在第一个真正请求时才撞墙。
九、常见问题(FAQ)
Q1:我真的需要1400行吗?
A:取决于你的Agent在什么环境运行。如果只在本地、自己用、任务简单——100行完全够。如果你的Agent需要处理真实用户的任意任务、支持断点恢复、有上下文预算管理——你会发现自己在不断往循环里加代码,最终也会接近这个数字。
Q2:单线程会不会太慢?
A:对大多数Agent场景不会。Agent的瓶颈通常是LLM响应速度(秒级),而非工具执行速度(毫秒级)。当你确实需要并行时,考虑子Agent隔离模型(像Claude Code的Task tool那样),而非共享状态的线程池。
Q3:Async Generator比普通循环好在哪里?
A:流式输出——用户看到第一个字符就开始阅读,不需要等整个响应完成。对用户体验是质的飞跃。
Q4:为什么不直接用LangGraph?
A:可以。LangGraph提供显式的图定义和可控的状态流转,适合有确定的Agent工作流。但如果你追求最简部署和最小概念负担,自己写循环完全可以。
Q5:Hermes Agent的并行方案和Claude Code的单线程方案,该选哪个?
A:如果你的工具之间严格独立(一个读API,一个写日志),并行更好。如果工具有共享资源(文件系统、数据库),单线程更安全。没有银弹。
总结
Claude Code的query.ts告诉我们一个深刻的道理:循环本身不是智能部分——模型才是。 循环的存在是为了在模型无法自己处理的生产条件下保持正确:丢失连接、上下文限制、治理钩子、失败的工具调用、慢速网络。
天真循环之外的每一行代码,都对应一次生产故障。
下一次你的Agent在生产中崩溃时,别急着说"AI不行"。看看那个10行的while循环——也许该给它加点代码了。
*本文基于INTERNALS.md的社区分析、Claude Code v2.1.88源码分析和官方文档撰写。所有实现细节来自社区逆向工程,可能与Anthropic内部实现存在差异。* [1]
#Agent工坊 #ClaudeCode #Agent架构 #生产级Agent #一人公司
本文由AI辅助创作,经人工审核编辑发布