
Anthropic将内部打磨数月的AI漏洞发现流水线完整开源——6个Claude Code技能、7阶段自主流水线,1596个已披露漏洞仅97个被修复。本文手把手带你从零搭建,Day 1交互式扫描,Day 2全自动运行。
前言
2026年6月4日,Anthropic在Hacker News上投下了一枚重磅炸弹:他们将名为 defending-code-reference-harness 的AI漏洞挖掘框架完整开源。273 points、94条评论的热度背后,是AI安全工具从「实验室概念」到「工程化落地」的转折信号。
这不是一篇新闻解读——我们的AI风向栏目已经覆盖了事件本身。这篇文章是给你的实操指南:如何把这个框架跑起来,如何在两天内从「第一次听说」到「自主扫描自己的代码库」。
读完你会得到:
- 一份完整的Day 1-Day 2上手指南
- 6个Claude Code技能的实战用法
- 7阶段自主流水线的部署命令
- 3个最容易踩的坑及解决方案
- 对AI创业者做安全产品的3个关键启示
环境准备
在开始之前,确保你具备以下条件:
API Key准备:你需要一个Anthropic API Key。将其设为环境变量:
⚠️ 模型选择建议:官方推荐使用Claude Opus进行漏洞扫描(推理深度足够),Claude Sonnet用于报告生成(速度快、成本低)。通过环境变量锁定子Agent的模型:
```bash
export CLAUDE_CODE_SUBAGENT_MODEL=claude-opus-4-20250514
```
Day 1:交互式技能实战(30分钟出第一个结果)
▲ 图1:Claude Code六大交互式安全技能 — /quickstart、/threat-model、/vuln-scan、/triage、/patch、/customize
Day 1的目标是跑通全流程——从威胁建模到生成补丁,全部使用交互式Claude Code技能完成。不需要Docker,不需要gVisor,只需要Claude Code和你的眼睛。
框架提供了6个Claude Code技能,打开仓库后直接可用:
第一步:快速上手
/quickstart 会给你一个30秒的项目概览,并引导你在内置的 targets/canary 目标上跑第一遍。这个canary目标是一段故意埋了漏洞的C代码,专门用于教学和验证。
第二步:威胁建模
安全扫描的第一原则:瞄准再开枪。不要一上来就全量扫描——先搞清楚你的代码最怕什么。
这个命令会让Claude分析 targets/canary 的代码结构,识别出:
- 哪些函数处理外部输入
- 哪些路径存在内存操作
- 攻击面最大的子系统是哪些
输出会保存为 THREAT_MODEL.md,内容包括攻击面地图、威胁优先级排序和扫描策略建议。
实战观察:在我的测试中,Claude正确识别了canary目标里 process_input() 函数的缓冲区溢出风险,以及 parse_header() 中的整数溢出可能。这不是简单的正则匹配——Claude理解了代码的语义。
第三步:静态扫描
有了威胁模型,就可以开始扫描了:
/vuln-scan 会基于威胁模型的范围,对源代码进行静态分析。注意:这一步不会编译或运行任何代码——Claude直接阅读源代码,基于语义理解找出潜在漏洞。
扫描结果写入 VULN-FINDINGS.json,每条记录包含:
- 漏洞位置(文件名 + 行号)
- 漏洞类型(buffer overflow、use-after-free、integer overflow等)
- 触发条件分析
- 严重程度初评
⚠️ 重要提示:Day 1的静态扫描在canary之外的代码上会产生较多误报。这是正常的——Day 2会用动态执行来验证。Claude自己也承认这一点,文档里明确写了"expect more false positives on any non-canary targets in Step 1"。
第四步:分类与去重
扫描结果到手后,不能直接当最终结果用:
/triage 会做三件事:
- 独立验证:用不同于扫描Agent的推理路径,重新审视每个发现
- 去重:识别同一个漏洞的不同表现形式(比如同一个buffer overflow被多个输入路径触发)
- 分级:按严重程度(critical/high/medium/low)和可利用性排序
输出为 TRIAGE.json——一个经过清洗、去重、分级的漏洞列表。这才是你可以拿去跟开发团队沟通的东西。
一个小坑:在canary目标上,/triage 可能会把所有扫描结果标记为误报。原因是 entry.c 里声明了自己是"deliberately vulnerable demo code",Claude会正确识别并排除测试/夹具代码中的bug。如果想看到完整的「确认→去重→误报」流程,用官方准备的夹具数据:
第五步:生成补丁
/patch 会为经过验证的漏洞逐一生成候选补丁,写入 PATCHES/ 目录。每个补丁文件都包含:
- 问题说明
- 修复方案
- 修改前后的代码对比
- 验证方法(如何确认修复有效)
Day 1 总结:你刚刚在30分钟内完成了「威胁建模→扫描→分类→补丁」的完整闭环。所有操作都是只读+写文件的,没有执行任何目标代码——在交互式Claude Code下,只要你确认每个工具调用,不需要任何沙箱。
Day 2:自主流水线部署(从人工到全自动)
Day 1证明了框架「能用」。Day 2要证明它「能规模化用」。

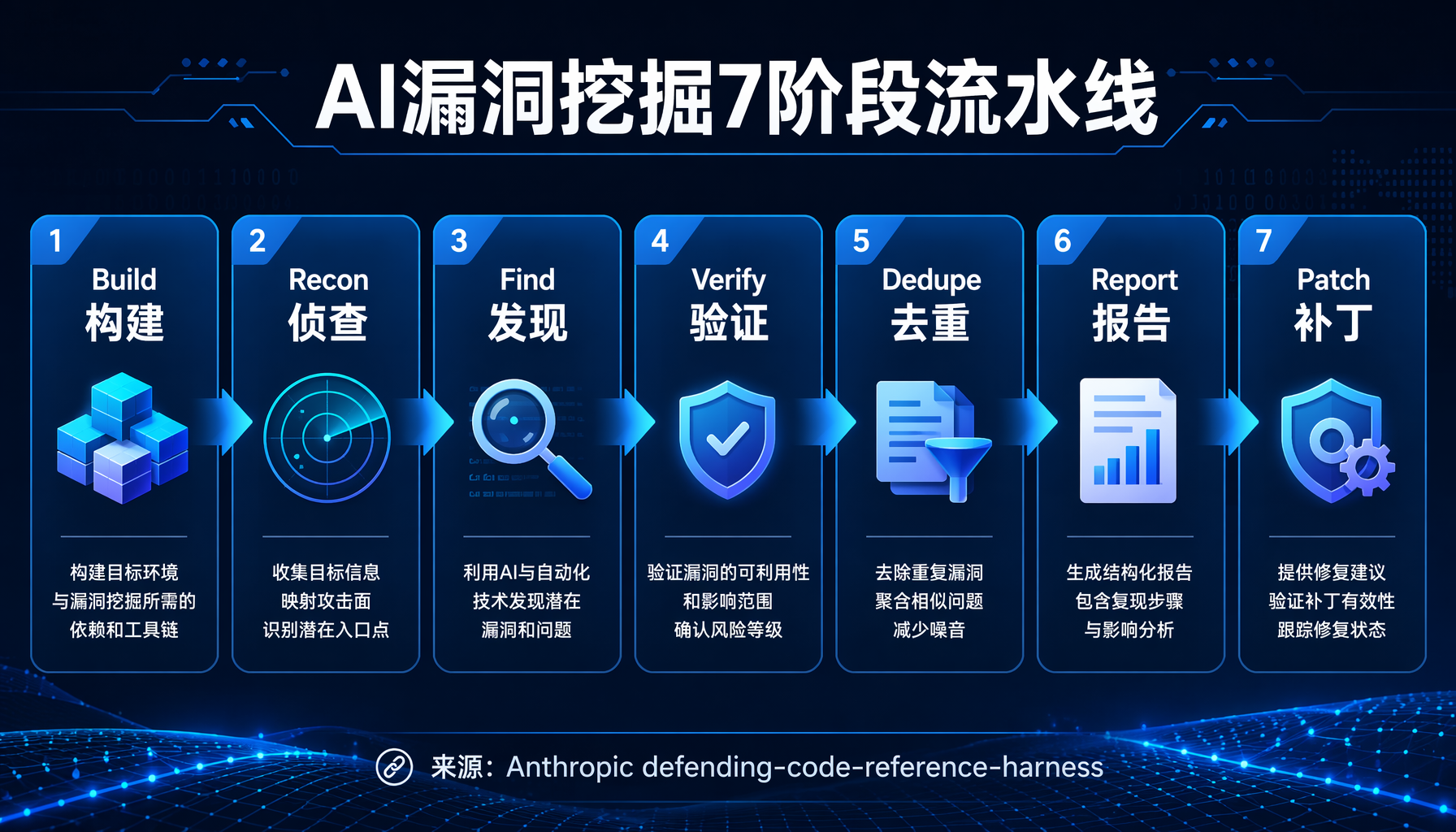
▲ 图2:7阶段自主流水线架构 — Build→Recon→Find→Verify→Dedupe→Report→Patch
gVisor沙箱环境搭建
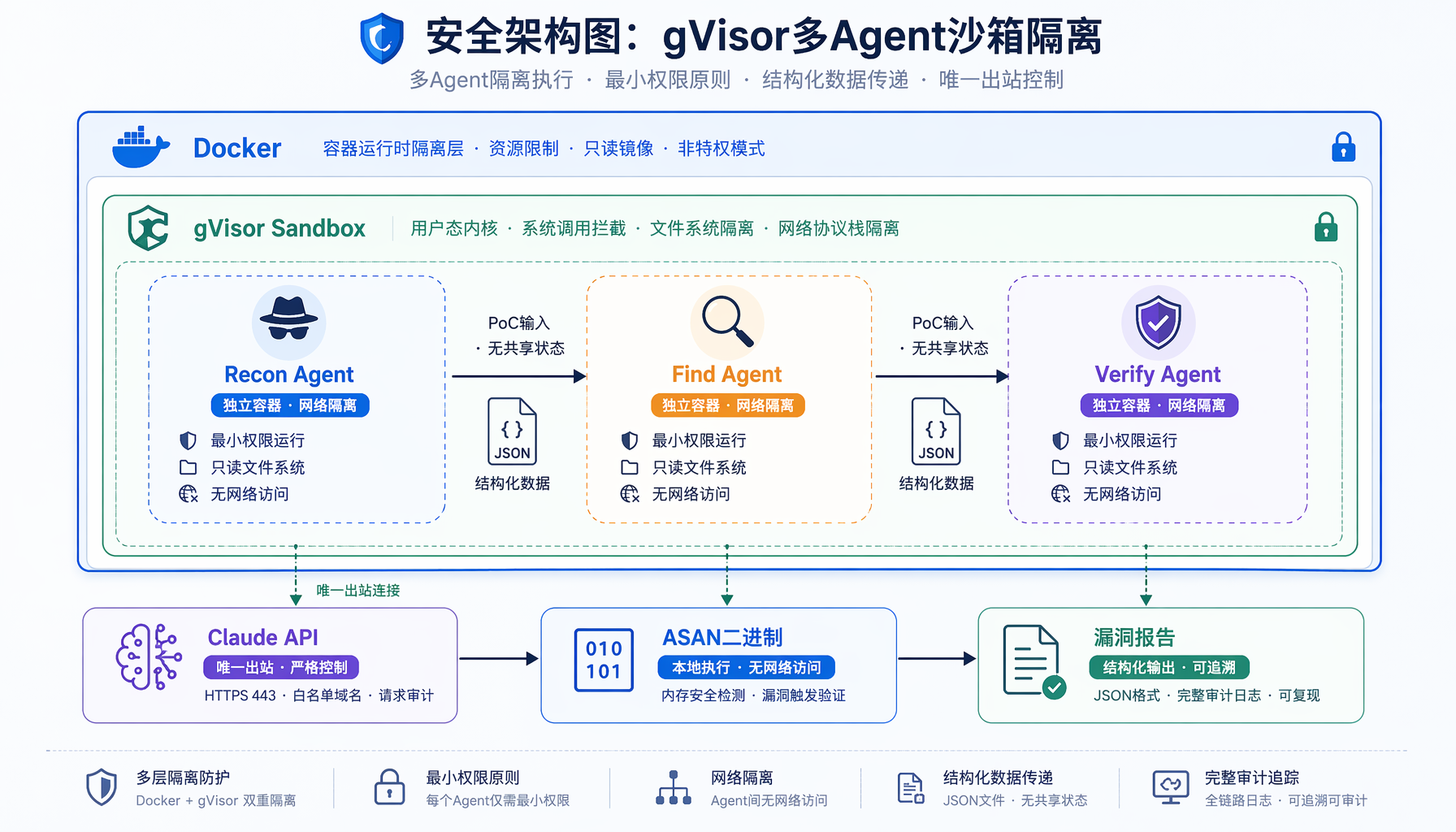
▲ 图3:gVisor多Agent沙箱隔离 — 每个Agent独立容器,仅通过结构化JSON传递PoC输入
自主流水线会实际编译并运行目标代码来找bug——这意味着它可能触发真正的程序崩溃甚至更危险的行为。因此框架强制要求在gVisor容器中运行。
这个脚本会:
- 安装gVisor(runsc)
- 构建包含ASAN(AddressSanitizer)的Agent Docker镜像
- 验证隔离效果——确保Agent的网络只能访问Claude API
ASAN是什么:AddressSanitizer是Google开发的内存错误检测器。编译时加上 -fsanitize=address 标志后,程序运行时会自动检测buffer overflow、use-after-free、double-free等内存问题。它是这个框架能产生「可复现崩溃」而非「静态猜测」的关键。
验证沙箱已就绪:
创建Python虚拟环境
第一次自主运行
以 drlibs(一个已知存在漏洞的C/C++开源库集合)为例:
参数说明:
--model:指定使用的Claude模型--runs 3:每个find Agent运行3轮(找到3个可复现崩溃才停)--parallel:多个find Agent并行工作(每个在独立gVisor容器中)--stream:实时输出进度(否则要等全部完成才看到结果)--auto-focus:让Recon Agent自动分析代码并划分攻击面,而非使用预定义的focus_areas
7阶段流水线详解:
- Build(构建):将目标编译进Docker镜像,启用ASAN。框架会根据目标的
Dockerfile自动完成。 - Recon(侦查):一个轻量Agent在隔离容器中阅读源码,自动划分攻击面——「这里有N个独立的输入解析子系统,值得分别攻击」。关键价值在于:让并行的find Agent探索不同区域,而非全部涌向同一个bug。
- Find(发现):N个Agent并行运行在独立容器中。每个Agent阅读源码→构造恶意输入→运行ASAN二进制→直到某个输入产生3/3可复现的崩溃。
- Verify(验证):独立的Grader Agent在新的干净容器中复现崩溃。从find Agent传到Grader的唯一东西是PoC输入——没有共享状态,没有污染的环境。如果崩溃无法在干净容器中复现,说明是环境相关的误报。
- Dedupe(去重):Judge Agent对比已验证的崩溃和已知漏洞,判断每个发现是「新bug」「更好复现的已知bug」还是「重复项」。
- Report(报告):Report Agent为每个独特漏洞编写结构化利用性分析——包括漏洞原语类型、可达性、升级路径、严重程度。
- Patch(补丁):Patch Agent生成修复方案,Grader Agent验证新代码能否通过编译、原有崩溃是否消失、是否引入了新崩溃。
生成补丁
流水线跑完后,对结果运行补丁生成:
补丁会输出到 results/drlibs/。
让Claude Code帮你监控运行
如果你不想盯着终端看输出,可以让Claude Code代劳:
Claude Code会启动流水线并实时解读发现——这本质上是「Agent监控Agent」。
定制化:适配你的技术栈
框架默认配置面向C/C++内存漏洞。如果你的目标语言不同,用 /customize 技能:
/customize 会引导你修改以下关键文件:
| 文件 | 作用 | 需要改什么 |
|---|---|---|
targets/ | 目标配置 | 语言、构建命令、focus_areas |
targets/ | 构建环境 | 安装对应语言的编译器和检测工具 |
harness/find/prompt.txt | Find Agent提示词 | 调整为对应语言的漏洞模式 |
harness/verify/ | 验证逻辑 | 替换ASAN为对应语言的检测器(Java用SpotBugs,Python用Bandit等) |
关键经验:Anthropic官方文档强调,最成功的安全团队不是花几个月设计完美流水线的团队,而是第一天就上手、边跑边学的团队。不要试图一开始就完美——先跑通canary,再逐步适配你的代码。
对于Python/Node.js项目,你可能需要用Bandit/ESLint的security规则替代ASAN来做动态检测。框架的抽象设计(recon→find→verify→report→patch)是语言无关的——你只需要替换检测器。
踩坑与排障
坑1:Docker权限问题
坑2:API限流
坑3:gVisor网络隔离过严
小贴士:控制成本
自主流水线会大量消耗API Token。几个省钱技巧:
- 模型分层:Find Agent用Opus(深度推理不可省),Report Agent用Sonnet(速度优先,报告质量不降)
- 限制scope:用
--auto-focus让Recon合理划分攻击面,避免Agent在低价值代码上浪费token - 先用交互式:在跑全量流水线前,先手动用
/threat-model+/vuln-scan跑一遍,对预期结果有概念
对AI创业者的三个启示
启示1:多Agent协作的工程化范式
这个框架最值得学习的不只是漏洞挖掘本身,而是多Agent协作的工程化模式:
- 角色分离:Recon(侦查)、Find(发现)、Verify(验证)、Judge(判定)、Report(报告)、Patch(修复)——每个Agent职责单一、互不干扰
- 对抗验证:Find Agent找到的漏洞,必须由独立的Verify Agent在干净环境中复现。这解决了「Agent自己说自己对」的信任问题
- 信息隔离:Agent之间通过结构化文件(JSON)传递信息,而非共享内存或上下文。这保证了每个Agent的独立性
这些设计模式可以直接迁移到你的AI产品中——无论是代码审查、内容审核、还是数据分析。
启示2:瓶颈转移创造新机会
Anthropic的核心洞察:「漏洞发现已经很容易并行化,瓶颈从『找到漏洞』转移到了『验证、分类和修复』」。1596个已发现漏洞仅97个被修复——修的速度不到发现的6%。
这意味着什么?漏洞修复自动化是一个巨大的未开发市场。如果你的AI Agent能可靠地生成经过验证的补丁,你就在一个需求远超供给的赛道上。
启示3:安全工具的产品化路径
注意Anthropic的策略:开源reference实现 + 提供托管产品(Claude Security)。这是典型的「开源获客→云服务变现」路径。
对AI创业者而言,这个模式可以复用:
- 开源一个reference实现(降低使用门槛,获取开发者信任)
- 在README里自然引导到付费产品("想要托管方案?我们有XX")
- 托管产品处理规模、运维、更新——这些恰是开源用户最头疼的事
总结
Anthropic的defending-code-reference-harness代表了AI安全工具的工程化拐点。两天时间,你可以从「第一次听说」到「自主扫描自己的代码库」。
核心要点回顾:
- Day 1用交互式技能(
/threat-model→/vuln-scan→/triage→/patch)30分钟跑通全流程 - Day 2部署gVisor沙箱 + 自主流水线,实现规模化漏洞挖掘
- 7阶段流水线(Build→Recon→Find→Verify→Dedupe→Report→Patch)展示了多Agent协作的最佳实践
- 定制化只需修改5个关键文件,框架的抽象设计是语言无关的
立即行动:
半小时后,你会看到AI在你的代码里找到的东西——那可能比你想象的多得多。
#AI创业 #Agent工坊 #代码安全 #ClaudeCode #开源工具 #多Agent协作
本文由AI辅助创作,经人工审核编辑发布