
2013年Google Reader关停时全行业为RSS写了悼词。错了十年。那个"已死"的协议不仅支撑着250亿美元的播客产业,现在成了AI Agent获取信息最可靠的通道——因为它做的恰恰是算法做不到的:确定性的、结构化的、不受广告关系绑架的内容交付。
事件回顾
5月30日,前Google工程师、现独立开发者Julien Reszka发表了一篇引发技术圈广泛讨论的博客:《RSS Is Back. AI Agents Are Reading It.》。文章上线不到48小时登上Hacker News首页,72分、56条评论,持续发酵。
文章的核心论点简单但锋利:AI Agent不需要"惊喜"——它需要确定性。 而RSS恰好提供了算法平台给不了的四样东西:
- 确定性的内容列表:按时间排列,新内容出现即出现在feed中
- 结构化格式:Agent不需要猜测页面结构,XML/RSS解析是标准化的
- 没有广告关系绑定的速率限制:不需要申请API Key,不会被限额
- 没有认证墙:公开内容的获取不需要OAuth
Reszka写道:"算法的本职工作就是不让你确定下一次刷新会看到什么。Agent刚好相反——它要的就是确定。"
一个250亿美元的证据
文章中最有力的事实支撑不是理论推演,而是播客产业的真实数据:整个播客行业——包括Spotify、Apple Podcasts、Overcast、Pocket Casts——都是靠RSS拉取节目文件和元数据的。 这个从2002年的协议支撑着250亿美元的市场,从来没有人"替代"过它,因为根本没有什么可替代:开放、免费、没有中间商、没有需要谈判的访问权。
"节目就在feed里的那个URL上,从来都是。"Reszka写道。
同样的逻辑正在向任何Agent需要可靠消费的书面内容延伸——语言模型检索上下文、监控Agent检查新文件、摘要工具消化简报邮件——所有这些场景都受益于可预测的、结构化的、按时间排序的新内容列表。
这就是RSS的全部。
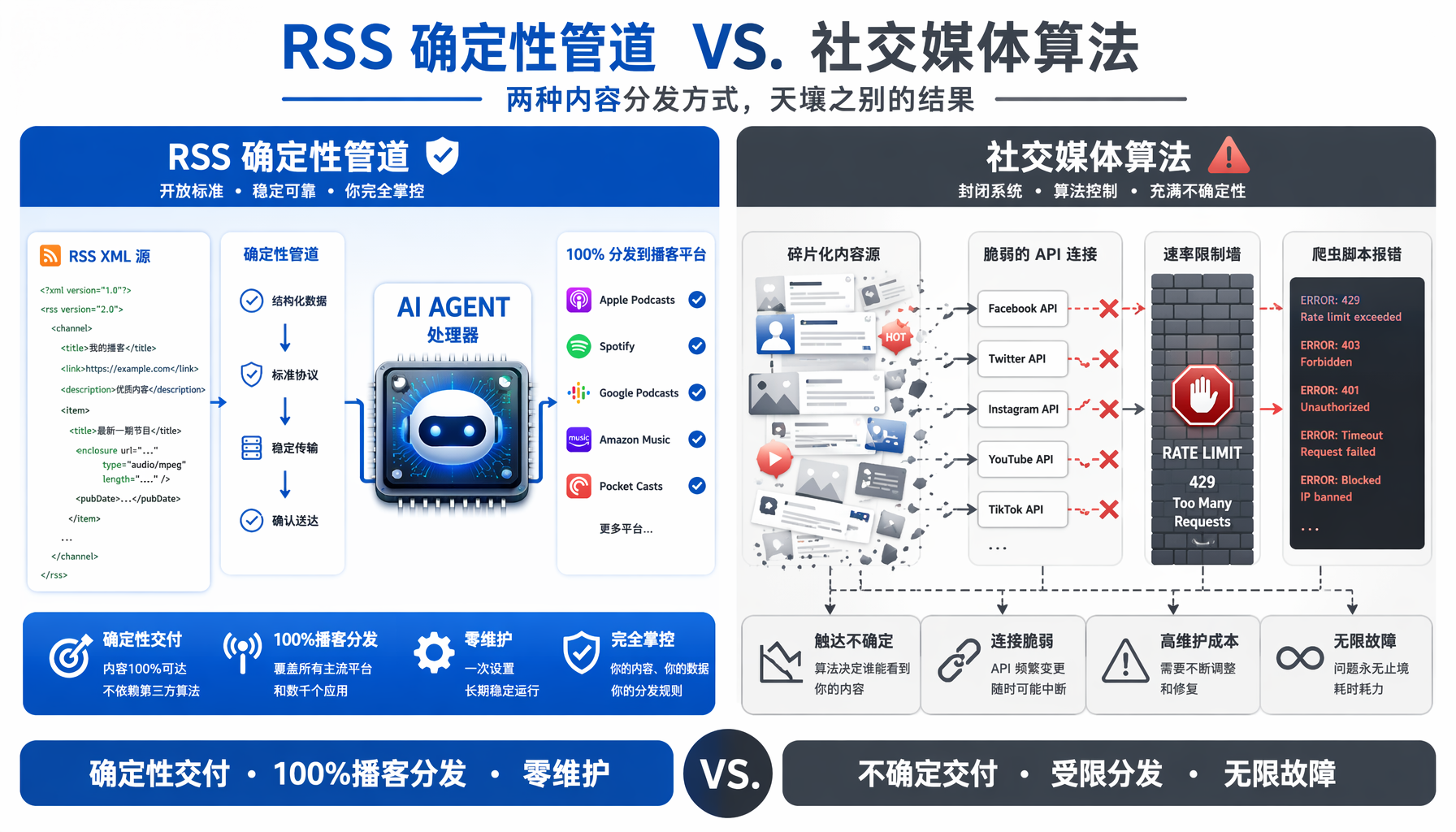
▲ RSS确定性管道 vs 社交媒体算法:两种内容分发范式,天壤之别的运维成本
实践者的声音:零维护 vs 无限故障模式
博客评论区里出现了一条极具操作性的评论。阿姆斯特丹的开发者Lara M.分享了她的实战经验:
"这周给客户建了一个竞品监控Agent。有RSS feed的网站30秒就接进去。没有RSS feed的网站需要写脆弱的爬虫脚本,每次网站改版就炸。"
两天后她又回来补充了一个关键数据点:
"维护成本的差异是数量级的。通过爬虫接10个源意味着10种故障模式要人工盯着。接10个RSS feed——设置完后几乎零维护。这就是每个在规模上构建监控Agent的开发者算的经济账。"
斯德哥尔摩的Erik L.也提供了另一个佐证:
"三周前读到Agent聚合利基技术内容后,给我们的简报加了RSS feed。一周内两个聚合器自动收录,我们什么都没做。Feed本身就是分发。"
这不是怀旧,这是Agent时代的架构选择
多伦多的Dan F.提出了一个有价值的反驳观点:
"Agent可以爬取网页不比解析RSS差。如果一个页面能加载HTML,有能力的Agent就能获取内容。"结构化的feed假设"暗示Agent太脆弱无法处理真实网页,这变得越来越不准确。"
但Lara的回应点中了要害:
"爬虫能工作——直到网站加了CAPTCHA、改了标记、或开始屏蔽已知的Agent用户代理字符串。RSS从设计上是确定性的:发布者控制里面有什么,而且不会因为首页改版而炸。更大的问题是维护:爬虫的脆弱性随源的数量线性增长。"
这个辩论揭示了关键洞察:Agent确实越来越善于解析非结构化网页,但"能"和"应该"是两回事。 对于需要稳定运行的自动化Agent管道,确定性格式的边际价值远超"技术上可行"的爬虫方案。
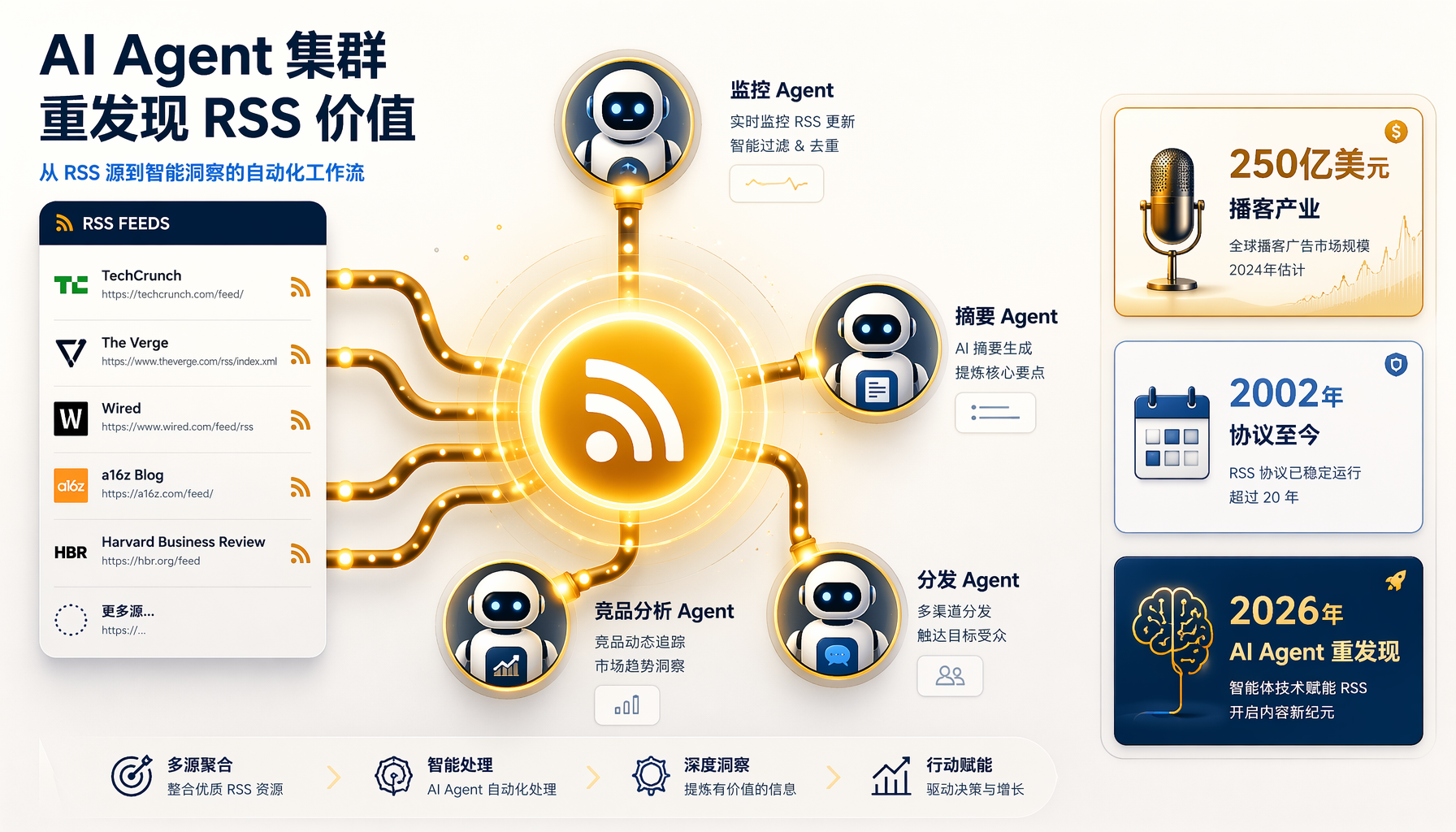
▲ 多个AI Agent节点从RSS feed中拉取内容:监控Agent、摘要Agent、竞品分析Agent,250亿美元播客产业的基础设施正在被AI Agent重发现
对我们意味着什么
1. 如果你在构建AI Agent
RSS应该是你的首选内容摄取协议,不是"如果有更好,没有也行"。理由:
- 可靠性:RSS feed是发布者自己维护的,比你写的任何XPath或CSS选择器都更不易碎
- 规模:10个源→100个源→1000个源,每个新加的非RSS源都是新的故障模式
- 法律合规:RSS是发布者的显式选择——他们把自己的内容放进feed里就是为了让别人消费。爬虫则处在灰色地带
- 速率友好:发布者不会给RSS feed加速率限制(他们想让你读),但会无情地限制API
2. 如果你在发布内容
加一个RSS feed。 这不是退步,这是对Agent时代的准备:
- 你发布的内容如果只存在于社交媒体平台内部(公众号、知乎、推特),Agent根本够不到——除非用爬虫,而爬虫随时会被封
- 有一个良好维护的RSS feed = 你的内容自动进入Agent生态的"超市货架"
- 博客评论区里Erik的案例已经证明:Agent聚合器会自动发现RSS feed,零推广成本
3. Agent内容消费的下一个前沿
这场讨论暗示着更广泛的趋势:
从"算法推荐"到"Agent主动拉取"的范式转换。 过去10年,内容分发由推荐算法主导——你看到什么取决于算法认为你应该看什么。Agent改变了这个等式:它主动检索、筛选、总结,不再等待推送。
这种模式下,RSS不是更好的选择——它是唯一的设计上符合"Agent主动拉取"的内容分发协议。任何需要登录、需要API Key、需要绕过反爬机制的系统都不符合这个架构。
Reszka在文末写了一个尖锐的对比:
"问题是你的内容是否能以那种方式被触达——还是它活在为人类注意力设计的系统里,那个系统正在主动降级程序化访问。"
行动建议
- 检查你的Agent内容源:你现在用Agent监控的所有信息源,有几个提供了RSS feed?把没有的列出来——每个都是潜在的维护成本炸弹
- 给你的项目加RSS:如果你运营博客、简报、或任何定期发布内容的渠道,花30分钟加一个RSS feed。WordPress有内置的、静态站点生成器(Hugo/Jekyll/Astro)有插件、甚至可以用简单的XML文件手动维护
- 在Agent工作流中优先RSS:构建监控/聚合Agent时,第一优先级应该是"这个源有没有RSS feed"——有就用,没有才考虑爬虫,而且要给爬虫路径加更多的错误处理和监控
- 跟踪Agent+内容分发的后续发展:这篇文章72分56条评论在HN上只是一个开始。随着更多Agent产品进入生产环境,RSS的重要性只会增加。
本文由AI辅助创作,经人工审核编辑发布