go-micro团队开源了一个仅220行的AI Agent CLI——micro chat。拆开看,智能体核心只有四段:工具发现 → 模型创建 → 对话记忆 → 主循环。读完这篇文章,你能用任何语言复现这个架构,给任何后端服务接上LLM大脑。
前言
你见过多少个"AI Agent框架"?LangChain、CrewAI、AutoGen、Semantic Kernel……名字多到数不清。每个都号称"简化Agent开发",但等你真正上手,却发现自己花了80%的时间在学框架本身,而不是在解决业务问题。
go-micro团队的Asim Aslam干了一件让人意外的事:他写了一个AI Agent CLI工具叫micro chat,能让用户用自然语言跟微服务对话。当被问到"这是怎么做到的"时,他的回答是:
"大概150行,没什么魔法。"
2026年5月30日,go-micro团队在官方博客上发布了一篇技术长文《Build Your Own AI Agent CLI in 150 Lines》,把micro chat的每一段逻辑都拆开讲解。我花了两天时间研读原文、跑通代码、做了中文语境下的适配——这篇文章就是成果。
读完你能带走三样东西:
- 一个4段式Agent架构模板:适用于任何编程语言、任何LLM提供商
- 服务自动发现 → 工具自动生成的范式:go-micro独有的能力,但思路可迁移
- 可以立刻复用的代码结构:Go版本(原文)+ Python版本(本文适配)
本文主要参考 go-micro 官方博客(go-micro.dev/blog/11,2026年5月30日发布),结合 Claude 和 DeepSeek 等主流模型的工具调用机制做了扩展说明。go-micro 项目已在 GitHub 开源。
问题定义:一个Agent到底需要什么?
假设你有一套微服务——用户服务、订单服务、邮件服务。你想做一件事:在命令行里输入一句话,让对应的服务自动被调用。
"帮我查一下用户Alice的订单,然后给她发一封确认邮件"
要完成这个任务,LLM需要三样东西:
- 工具列表:它能调用哪些服务?每个服务叫什么名字、需要什么参数?
- 执行通道:当它决定"调用邮件服务"时,谁去真正执行?返回结果怎么传回来?
- 对话记忆:如果用户接着问"刚才那封邮件发了吗?",Agent需要记得上一轮的上下文
go-micro的答案是:工具列表从服务注册表自动生成,执行通道由框架的RPC层统一调度,对话记忆用一个简单的消息列表实现。我们逐段拆解。
Part 1:工具发现——从服务到工具的自动映射
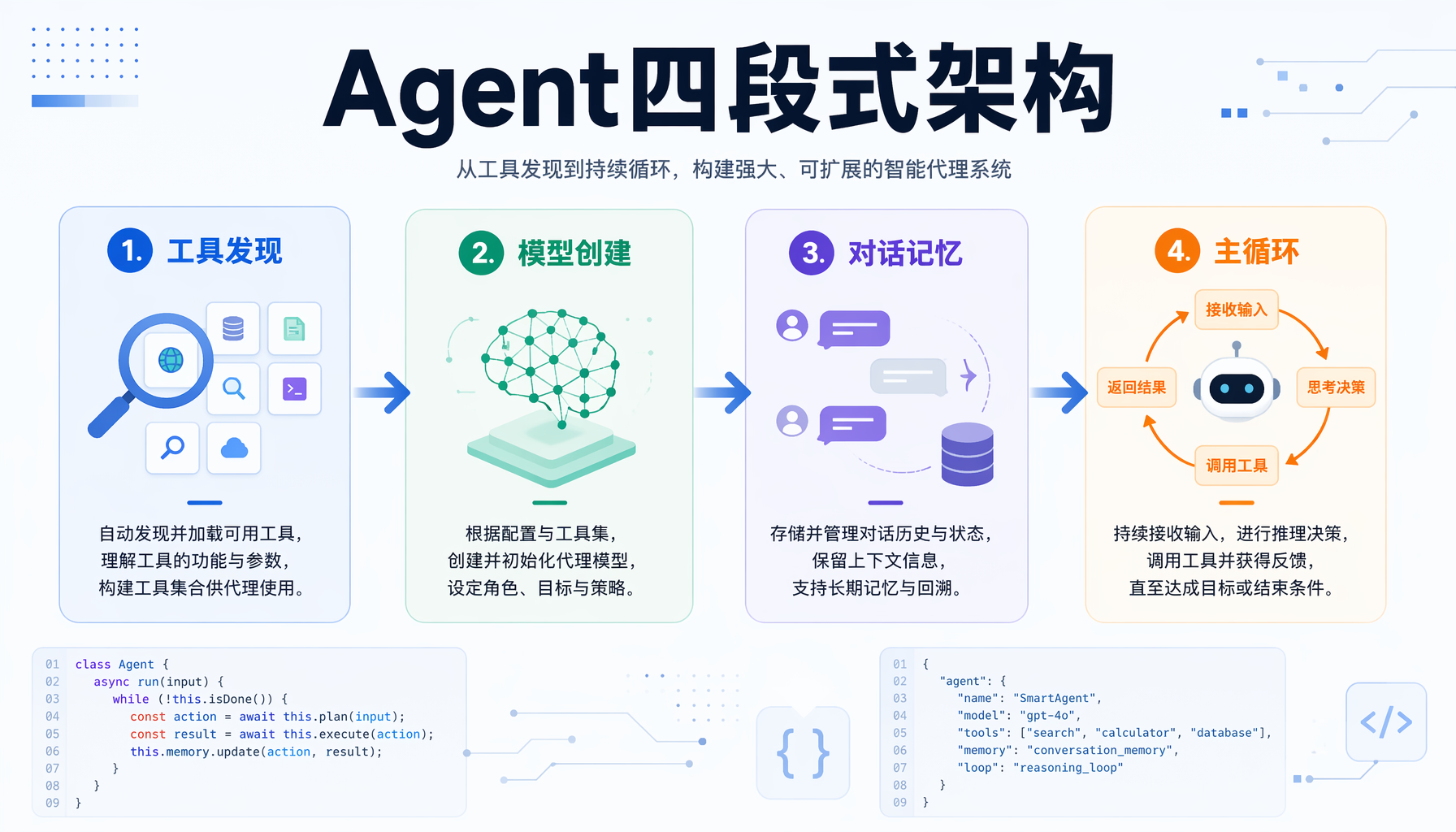
▲ Agent四段式架构:工具发现→模型创建→对话记忆→主循环
这是go-micro方案里最巧妙的一步。传统做法是:你写一个list_tools()函数,手动把每个服务端点(endpoint)转成JSON Schema,维护一个工具描述文件。
go-micro不需要你写一行工具描述代码。因为每个微服务在启动时就向注册中心(Registry)注册了自己的元数据:
// 服务定义示例(go-micro v5)
// CreateUser creates a new user account.
// @example {"name": "Alice", "email": "alice@example.com"}
func (h *Users) CreateUser(
ctx context.Context,
req *pb.CreateRequest,
rsp *pb.CreateResponse,
) error {
// 业务逻辑...
}
关键信息都在代码里:
- 函数名 → 工具名(
users_Users_Create) - 注释文档 → 工具描述("creates a new user account")
@example 标签 → 给了LLM一个"正确用法"的示范- Request结构体的字段 → 工具的参数schema
一行代码就能把整个注册表里的所有服务都发现出来:
tools := ai.NewTools(reg, ai.ToolClient(client))
discovered, err := tools.Discover()
// discovered 现在是 []ai.Tool —— 每个服务端点一个工具
迁移思路:不用go-micro怎么办?
如果你用的是FastAPI、Spring Boot、或者其他非go-micro框架,你需要做的是:
# Python 版本:手动枚举工具
import json
def list_tools():
tools = [
{
"name": "create_user",
"description": "Create a new user account",
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "User's full name"},
"email": {"type": "string", "description": "Email address"},
},
"required": ["name", "email"]
},
"example": '{"name": "Alice", "email": "alice@example.com"}'
},
# ...更多工具
]
return tools
工作量不大——几十行代码的事。go-micro的价值在于把这个过程自动化了,但你完全可以手动维护一份工具清单。关键不是"自动化了多少",而是"工具描述的清晰度"——LLM做推理的质量,完全取决于你的描述有多准确。
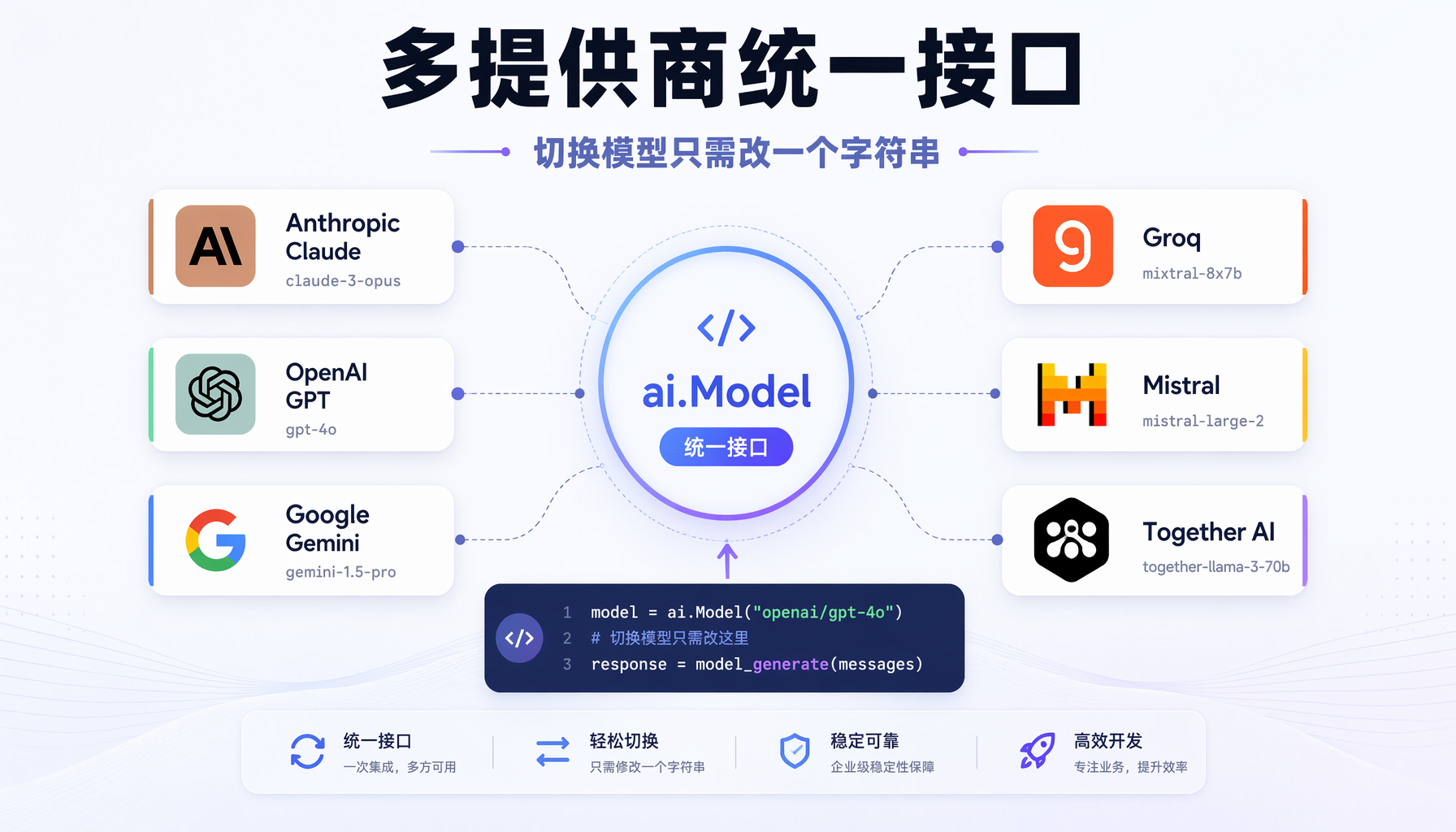
Part 2:创建模型——多提供商统一接口

▲ 多提供商统一接口:Anthropic、OpenAI、Google等六大模型通过同一个ai.Model接口调用
go-micro的AI模块(go-micro.dev/v5/ai)封装了一个统一的ai.Model接口,支持Anthropic、OpenAI、Google Gemini、Groq、Mistral、Together AI、Atlas Cloud等所有主流提供商。
m := ai.New(
"anthropic", // 提供商名称,改这里就换模型
ai.WithAPIKey(apiKey), // API Key
ai.WithTools(tools), // 工具列表 + 执行器
)
切换提供商只需要改一个字符串:把"anthropic"改成"openai"或"gemini"。
执行器是"隐形"的
注意ai.WithTools(tools)这行——它不只是把工具列表传给模型。Tools对象做了双重工作:
Discover() → 构建工具列表(描述信息),给LLM看的- 内部Handler → 当LLM返回"调用
users_Users_Create"时,自动路由到正确的RPC调用,执行后把结果返回给模型
在Python里等效的代码大约是这样:
import anthropic
import json
class AgentModel:
def __init__(self, provider: str, api_key: str, tools: list):
self.provider = provider
if provider == "anthropic":
self.client = anthropic.Anthropic(api_key=api_key)
# elif provider == "openai": ...
self.tools = tools
def generate(self, prompt: str, history: list) -> dict:
response = self.client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
system="You are a helpful assistant with access to tools.",
messages=history + [{"role": "user", "content": prompt}],
tools=self.tools
)
# 解析响应:文本回复 + 工具调用
result = {"reply": "", "tool_calls": []}
for block in response.content:
if block.type == "text":
result["reply"] += block.text
elif block.type == "tool_use":
result["tool_calls"].append({
"name": block.name,
"input": block.input
})
return result
Part 3:对话记忆——最简单的状态管理
hist := ai.NewHistory(50) // 保留最近50轮对话
不夸张地说,这就是整个对话记忆模块的全部实现。History就是一个消息列表封装:
Add(role, content):添加一条消息Messages():返回完整消息列表Reset():清空记忆
50轮的上限是出于Token成本的考量——Claude的上下文窗口很大(200K tokens),但每轮都带着50轮历史,Token账单会迅速膨胀。实际使用中可以根据场景调整:客服场景可能需要更短(10轮),代码助手可以更长(100轮)。
Part 4:主循环——十行代码的Agent核心
▲ 150行代码 = 完整Agent CLI:Go代码和终端交互效果
前三个Part做完后,你能用下面的代码把一切串起来:
func ask(ctx context.Context, m ai.Model, hist *ai.History,
tools []ai.Tool, prompt string) error {
// 1. 记录用户输入
hist.Add("user", prompt)
// 2. 调用模型(带上工具列表和对话历史)
resp, err := m.Generate(ctx, &ai.Request{
Prompt: prompt,
SystemPrompt: systemPrompt,
Tools: tools,
Messages: hist.Messages(),
})
if err != nil { return err }
// 3. 打印模型回复
if resp.Reply != "" {
hist.Add("assistant", resp.Reply)
fmt.Println(resp.Reply)
}
// 4. 报告工具调用情况
for _, tc := range resp.ToolCalls {
args, _ := json.Marshal(tc.Input)
fmt.Printf(" → called %s(%s)\n", tc.Name, args)
}
// 5. 打印最终答案
if resp.Answer != "" {
hist.Add("assistant", resp.Answer)
fmt.Println(resp.Answer)
}
return nil
}
读这段代码时的关键认知:你不需要写任何"if用户想发邮件then调用邮件服务"的条件逻辑。 LLM自己根据工具描述(Part 1)推理出该调用哪个工具,框架的执行器(Part 2)自动执行,结果返回给LLM,LLM根据结果生成最终回答。
这就是Agent的"智能"本质——不是预设规则,是LLM基于工具描述的动态推理。
REPL包装
把ask包装成命令行交互循环,Agent就变成了一个聊天工具:
scanner := bufio.NewScanner(os.Stdin)
for {
fmt.Print("> ")
if !scanner.Scan() { return nil }
line := strings.TrimSpace(scanner.Text())
switch line {
case "": continue // 空行跳过
case "exit", "quit": return nil // 退出
case "reset": hist.Reset(); continue // 清空记忆
default:
if err := ask(ctx, m, hist, discovered, line); err != nil {
fmt.Printf("error: %v\n", err)
}
}
}
总共约40行(不算函数签名和注释),完成了一个完整的Agent主循环。
为什么可以这么短?
go-micro团队没有发明任何新概念。他们只是把三个已有的能力组合在一起:
- 服务自描述:go-micro的每个服务都在注册时带上了元数据——函数名、注释、
@example标签、Request结构体字段。这一切正好是LLM原生工具调用所需的全部信息。不需要手写Schema。 - 提供商统一抽象:
ai.Model接口让你可以专注于Agent逻辑,而不需要在Anthropic和OpenAI的不同API之间写适配器。 - 执行通道自动绑定:
ai.WithTools(tools)一步完成了"注册工具列表"和"绑定RPC执行器"两件事。
如果不是go-micro,会多多少代码?
go-micro团队在原文里给了一个估算:如果你用原生HTTP服务替换go-micro的RPC层,大约需要额外50行——一个函数枚举你的所有端点,一个函数按名称调用某个端点。其他部分完全不变。
换句话说,四个Part中只有Part 1(工具发现)和框架相关,Part 2-4是通用的。把这个架构移植到Python、Node.js、Rust,逻辑一模一样。
实操指南:用Python复现这个架构
如果你的后端不是Go语言,但你想立刻拥有一个能给服务接LLM的Agent CLI,这里是Python完整实现:
#!/usr/bin/env python3
"""ai-cli.py —— 150 行 Python AI Agent CLI"""
import json, os, sys
import anthropic # pip install anthropic
# ====== Part 1: 工具定义 ======
TOOLS = [
{
"name": "get_user",
"description": "Get user information by user ID",
"input_schema": {
"type": "object",
"properties": {
"user_id": {"type": "string", "description": "The user's ID"}
},
"required": ["user_id"]
}
},
{
"name": "list_orders",
"description": "List all orders for a user",
"input_schema": {
"type": "object",
"properties": {
"user_id": {"type": "string", "description": "The user's ID"}
},
"required": ["user_id"]
}
},
# ... 把你的所有服务端点列在这里
]
# ====== Part 2: 工具执行器 ======
def execute_tool(name: str, args: dict) -> str:
"""根据工具名和参数执行对应的业务逻辑"""
if name == "get_user":
# 实际项目中这里调你的API或数据库
return json.dumps({"id": args["user_id"],
"name": "Alice", "email": "alice@example.com"})
elif name == "list_orders":
return json.dumps([
{"id": "ORD-001", "total": 299.00, "status": "shipped"},
{"id": "ORD-002", "total": 149.50, "status": "pending"}
])
else:
return json.dumps({"error": f"Unknown tool: {name}"})
# ====== Part 3: 对话记忆 ======
class History:
def __init__(self, max_turns=50):
self.messages = []
self.max_turns = max_turns
def add(self, role: str, content: str):
self.messages.append({"role": role, "content": content})
# 超过上限,修剪最早的一对(user + assistant)
if len(self.messages) > self.max_turns * 2:
self.messages = self.messages[2:]
def reset(self):
self.messages = []
# ====== Part 4: 主循环 ======
SYSTEM_PROMPT = "You are a helpful assistant with access to tools. Use tools when needed."
def ask(client, history: History, tools: list, prompt: str):
history.add("user", prompt)
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
system=SYSTEM_PROMPT,
messages=history.messages,
tools=tools
)
# 处理响应:可能是纯文本,也可能是工具调用
text_parts = []
tool_uses = []
for block in response.content:
if block.type == "text":
text_parts.append(block.text)
elif block.type == "tool_use":
tool_uses.append(block)
# 如果有工具调用,执行它们并继续对话
if tool_uses:
# 把assistant的工具调用请求加入历史
history.add("assistant", response.content)
# 执行每个工具调用,结果放入历史
tool_results = []
for tool_use in tool_uses:
result = execute_tool(tool_use.name, tool_use.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": result
})
print(f" → called {tool_use.name}({json.dumps(tool_use.input)})")
history.add("user", tool_results)
# 把工具结果发回模型,获取最终答案
final = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
system=SYSTEM_PROMPT,
messages=history.messages,
tools=tools
)
answer = final.content[0].text
history.add("assistant", answer)
print(answer)
else:
# 纯文本回复
reply = "".join(text_parts)
history.add("assistant", reply)
print(reply)
def main():
api_key = os.getenv("ANTHROPIC_API_KEY")
if not api_key:
print("Error: ANTHROPIC_API_KEY not set")
sys.exit(1)
client = anthropic.Anthropic(api_key=api_key)
history = History(max_turns=50)
print("AI Agent CLI ready. Type 'exit' to quit, 'reset' to clear history.")
while True:
try:
line = input("> ").strip()
except (EOFError, KeyboardInterrupt):
print("\nGoodbye!")
break
if not line:
continue
if line.lower() in ("exit", "quit"):
print("Goodbye!")
break
if line.lower() == "reset":
history.reset()
print("History cleared.")
continue
ask(client, history, TOOLS, line)
if __name__ == "__main__":
main()
这个Python版本完整实现了go-micro的四个Part。你可以直接复制粘贴、修改TOOLS列表和execute_tool函数,接上你自己的服务。
扩展方向:从CLI到生产级Agent
原文给出了几个扩展思路,我结合实际经验做了补充:
1. 确认步骤(阻止误操作)
在工具执行前加一个确认环节:
if tool_use.name.startswith("delete") or tool_use.name.startswith("drop"):
confirm = input(f"⚠️ About to execute {tool_use.name}. Continue? (y/n): ")
if confirm.lower() != "y":
tool_results.append({"tool_use_id": tool_use.id,
"content": "User cancelled the operation"})
continue
2. 审计日志
把每次工具调用记录到日志系统:
import logging
logging.info(f"TOOL_CALL: {tool_use.name} | args={json.dumps(tool_use.input)} | result={result[:200]}")
这是生产环境中最重要的非功能需求——出了问题你需要知道Agent做了什么事、为什么做。
3. 工具白名单
不是所有服务端点都适合暴露给LLM。加一个过滤器:
ALLOWED_TOOLS = {"get_user", "list_orders", "search_products"} # 只读操作
# ALLOWED_TOOLS = {"*"} # 放开所有工具
tools = [t for t in TOOLS if t["name"] in ALLOWED_TOOLS]
4. 从REPL到多渠道
ask函数不依赖输入源——你可以把prompt参数换成Slack消息、HTTP请求Body、或者消息队列里的内容。
# Slack Bot 版本
@app.event("app_mention")
def handle_mention(event):
prompt = event["text"]
ask(client, history, TOOLS, prompt)
# 回复用 say() 而非 print()
5. 加载领域知识
给系统提示词注入你的业务知识:
SYSTEM_PROMPT = """
You are a support agent for Acme Corp.
Products: Widget A ($99), Widget B ($199), Widget C ($299).
Return policy: 30 days, free return shipping.
When helping customers, always mention relevant products and policies.
"""
踩坑与排障
坑1:工具描述太模糊
症状:Agent不调用工具,或者调用错误的工具。
原因:工具描述和参数说明写得太含糊。LLM是根据你的描述来做推理的——描述就是它的"说明书"。
修复:给每个工具写清晰的英文描述,描述里说明"什么时候该用这个工具"。@example标签(go-micro)或examples字段(OpenAI)非常有帮助。
坑2:对话历史无限增长
症状:运行一段时间后变慢、费用增长、甚至超过模型的上下文窗口。
原因:没有设置max_turns上限。
修复:设置合理的历史长度上限(10-100轮视场景而定),或者实现滑动窗口修剪。
坑3:工具执行超时
症状:Agent卡住,没有任何输出。
原因:某个工具调用(如查询慢数据库)超时了,Agent在等结果。
修复:给execute_tool加超时机制,超时后返回错误信息而不是空结果——让LLM知道"这个操作失败了"比让它以为"没结果"好。
坑4:工具结果太大
症状:工具返回了几千行数据,Agent开始"乱说"。
原因:工具结果塞满了上下文窗口,挤掉了重要的对话历史。
修复:截断工具结果(result[:2000]),或让LLM在工具描述里指定要哪些字段。
常见问题(FAQ)
Q1:这个架构支持多轮工具调用吗(Agent调用工具→看结果→再调另一个工具)?
A:支持。resp.ToolCalls返回的是一个列表,LLM可以一次请求多个工具调用。如果你的Agent需要"链式工具调用"(调A→看结果→调B),只需在Part 4的循环里加一步:如果ToolCalls不为空,执行后把结果放回对话历史,再调一次模型。
Q2:Python版本和Go版本性能差距大吗?
A:Agent的性能瓶颈不在语言,在LLM API调用的延迟(通常1-5秒)。Python和Go在Agent场景下的差异可以忽略不计。
Q3:能不能用Ollama本地模型替代API?
A:可以,但前提是你的本地模型支持原生工具调用(Tool Calling)。目前支持最好的是Llama 3.1 70B+、Qwen 2.5 72B+。小模型(7B级别)的工具调用准确率显著下降,不建议用于生产。
Q4:多Agent怎么写?
A:每个Agent就是一个独立的ask循环实例,状态隔离(独立的History)。Agent之间的通信通过消息队列或共享数据库中转。go-micro的姊妹项目micro flow就是用事件驱动的方式编排多个Agent。
总结
这篇文章的核心收获不是学会了一个Go框架的用法,而是理解了Agent = 工具列表 + 模型 + 对话记忆 + 主循环这个通用架构。
| 组成部分 | go-micro实现 | 通用等价物 |
|---|
| 工具发现 | Registry → ai.NewTools().Discover() | 手动枚举端点 → 构建工具列表 |
| 模型创建 | ai.New("anthropic", ...) | anthropic.Anthropic() / openai.OpenAI() |
| 对话记忆 | ai.NewHistory(50) | 一个消息列表 + 长度上限 |
| 主循环 | ask() + REPL | 一个函数,输入prompt,输出结果 |
把这个架构刻在脑子里,你就理解了市面上所有主流Agent框架(LangChain Agent、CrewAI、AutoGen、Semantic Kernel)的底层共性。它们加了很多抽象层和编排能力,但骨架永远是这四个Part。
最后,这句话值得单独拎出来:
你不需要写任何"if用户想发邮件then调用邮件服务"的条件逻辑。LLM自己推理。
这是Agent区别于传统if-else自动化脚本的本质。理解了这一点,你就理解了为什么2026年的AI创业者该把技能点加在"设计好工具描述"上,而不是"写好规则引擎"上。
*本文参考 go-micro 官方博客(go-micro.dev/blog/11, 2026-05-30),Python代码为作者基于架构思路的独立实现。go-micro是开源框架,GitHub: github.com/go-micro/go-micro。*
#AI创业 #Agent工坊 #Go语言 #LLM #一人公司
本文由AI辅助创作,经人工审核编辑发布
