AI Agent写出代码的速度是人的10倍,但它重复犯错的速度也是10倍——Merrilin团队用tree-sitter在pre-commit阶段拦截了8类高频错误,331个PR零事故。
前言
如果你正在用Claude Code、Cursor、Hermes Agent或任何AI编程工具做产品开发,你一定经历过这种撕裂感:Agent能在30秒内生成一个完整的功能模块,但同时,它也在30秒内复制了你在过去三个月里踩过的每一个坑。
raise HTTPException(...)、except Exception: pass、catch (error) { console.error(error) }——这些代码单独看都"能跑",但组合在一起就是一颗定时炸弹。
今天这篇文章,我们拆解Merrilin.ai团队的做法:他们用pre-commit + tree-sitter搭建了一套自动化防线,在AI Agent生成的代码被commit之前就拦截掉已知的坏模式。这不是"又一个lint工具"的科普——这是一套经过331个PR、81个数据库迁移文件验证的生产级方案。
读完这篇文章,你将获得:
- 一套可复用的tree-sitter规则模板(8条核心规则)
- 如何在你的项目中5分钟内接入这套防线
- 为什么prompt约束对AI Agent的代码质量基本无效,以及什么才有效
为什么prompt指令挡不住AI Agent的坏代码
在进入实操之前,先理解一个关键认知:prompt约束对AI Agent的代码质量基本无效。
这不是说prompt engineering没有价值。问题在于AI Agent在生成长代码时的行为模式:当它面对一个需要50行以上的功能实现时,模型会进入"交付模式"——优先保证功能能跑通,而不是保证代码符合架构规范。
Merrilin团队在文章里说的很直白:
"There is a certain wonder in watching a machine produce so much working code so quickly. There is also a certain exhaustion in watching it rediscover the exact same bad ideas at scale."
—— 看着机器快速产出能跑的代码有一种奇妙的快感。看着它在大规模下不断"重新发现"一模一样的坏主意,又有一种深沉的疲惫。
这就是为什么他们从"prompt约束"转向了"代码级硬边界"。
核心方案:tree-sitter + pre-commit
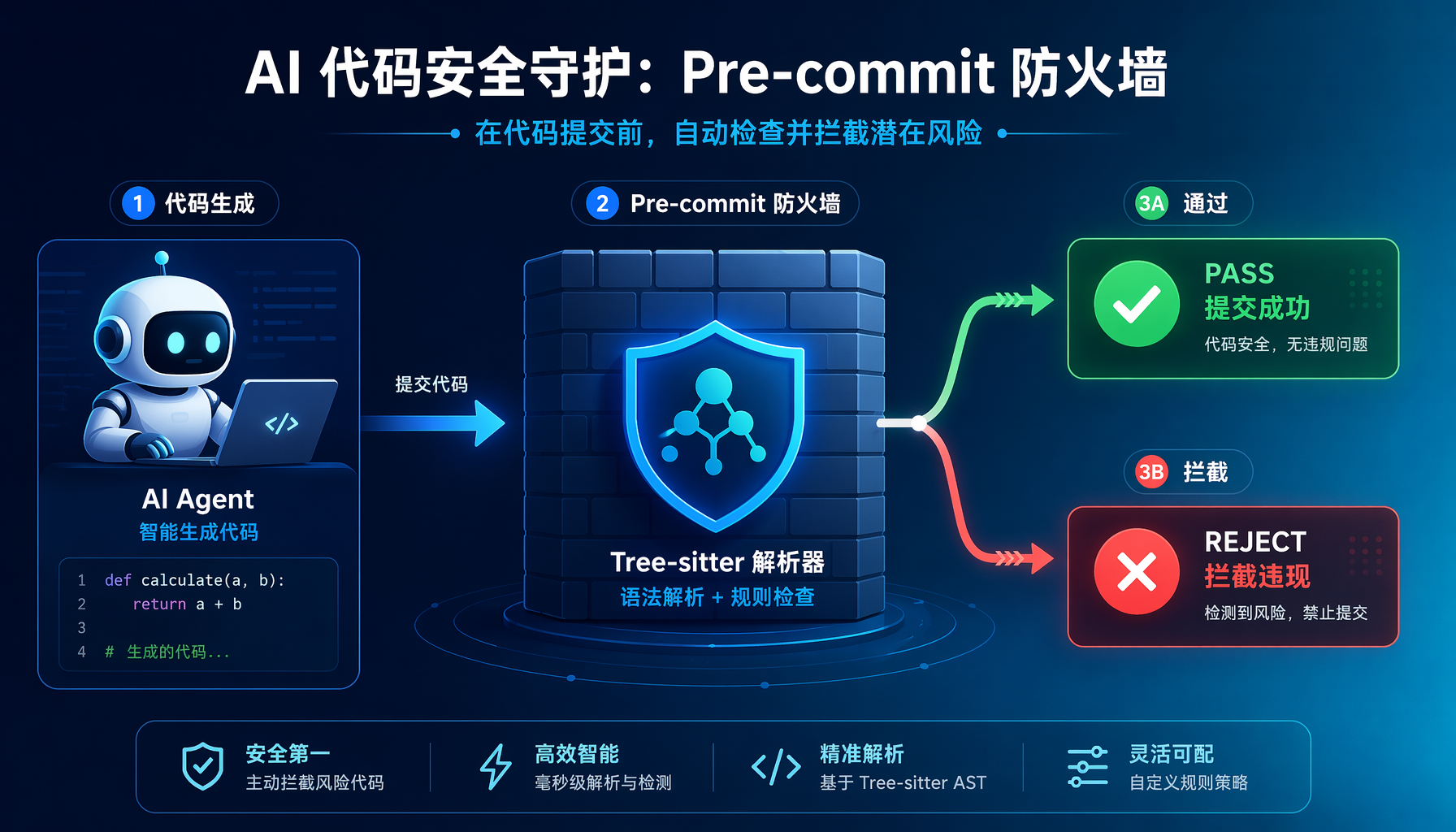
▲ 图1:pre-commit + tree-sitter防线架构流程
为什么是tree-sitter而不是grep或传统AST?
这是很多人会问的第一个问题。答案有三个层面:
1. grep是盲目的
grep只能做文本匹配。grep "except Exception" 会匹配到注释里的代码示例、字符串里的内容、以及确实需要捕获Exception的合法场景。你无法区分"这个except是否跟着rollback"、"这个catch是否在关键路径上"。
2. 传统AST太重
Python的ast模块、TypeScript的ts-morph可以解析语法树,但它们:
- 需要完整的项目上下文(依赖安装、类型解析)
- 速度慢(一个中型项目可能需要几十秒)
- pre-commit阶段等不起
3. tree-sitter刚刚好
tree-sitter是一个增量解析器,它在以下维度做到了最佳平衡:
- 速度:毫秒级解析单个文件
- 容错:不完整的代码也能解析出部分AST
- 跨语言:Python、TypeScript、TSX一套工具搞定
- 精确性:能区分
except HTTPException as e:和except Exception: logger.exception(...)
架构总览
AI Agent生成代码
↓
git add
↓
pre-commit hook触发
↓
tree-sitter解析 Python/TS/TSX → AST
↓
遍历AST节点,匹配违规模式
↓
┌─ 通过 → git commit 继续
└─ 拒绝 → 打印违规行 + 原因 → 阻止commit
关键设计决策:在pre-commit阶段拦截,而非PR阶段。 理由很简单——PR review时坏模式已经"沉淀"在代码库中,修改的成本远高于在本地commit前拦截。
8条保命规则详解

▲ 图2:AI Agent坏代码 vs 正确错误处理模式对比
Merrilin团队的核心产品是AI阅读伴侣,所以他们有一条"宪法级"铁律:绝对不能打断用户的阅读体验。 围绕这条铁律,他们定义了8条tree-sitter规则。我们逐条拆解,给出可复用的实现思路。
规则1:数据库操作后不能"抓了异常继续跑"
# ❌ AI Agent最爱的坏模式
try:
db.execute(update_query)
except Exception:
logger.exception("something went wrong")
# 继续执行——事务可能已经处于损坏状态
# ✅ 正确模式
try:
db.execute(update_query)
except DatabaseError:
db.rollback()
raise ServiceUnavailableError("database operation failed")
tree-sitter实现思路:
- 检测
try块中是否包含数据库操作(如db.execute、session.query、cursor.execute) - 检查
except块中是否缺少rollback()或raise语句 - 如果捕获了异常但既没有回滚也没有重新抛出 → 拒绝
规则2:SQLAlchemy异常捕获没有恢复边界
# ❌ AI Agent容易写出的模糊异常处理
try:
user = db.query(User).filter_by(id=user_id).one()
except NoResultFound:
return None # 调用方不知道是"用户不存在"还是"数据库挂了"
# ✅ 明确区分异常类型
try:
user = db.query(User).filter_by(id=user_id).one()
except NoResultFound:
raise UserNotFoundError(user_id)
except OperationalError:
raise ServiceUnavailableError("database unavailable, retry later")
tree-sitter实现思路:
- 检测
except子句捕获了SQLAlchemy异常但没有映射到业务异常 - 强制要求至少有两种不同的
except分支(区分"资源不存在"和"基础设施故障")
规则3:IntegrityError被静默吞掉
# ❌ 最危险的模式
try:
db.add(new_record)
db.commit()
except IntegrityError:
pass # 数据丢了,但没人知道
# ✅ 转换为业务语义
try:
db.add(new_record)
db.commit()
except IntegrityError as e:
db.rollback()
if "duplicate key" in str(e):
raise ConflictError("record already exists")
raise ServiceUnavailableError("database constraint violation")
规则4:后台数据库错误没有回滚
# ❌ 后台任务里的裸异常
@celery.task
def process_order(order_id):
try:
order = db.query(Order).get(order_id)
# ... 处理逻辑
except Exception:
# 没有rollback!数据库连接可能已损坏
logger.error(f"failed to process {order_id}")
# ✅ 后台任务必须有显式的事务边界
@celery.task
def process_order(order_id):
try:
with db.begin() as transaction:
order = db.query(Order).get(order_id)
# ... 处理逻辑
except Exception:
logger.error(f"failed to process {order_id}, transaction rolled back")
raise # 让Celery处理重试
规则5:读者关键路径上的数据库操作没有恢复机制
这需要你对项目的"关键路径"有明确定义。Merrilin的做法是:标记所有涉及阅读进度的代码路径为"reader-critical",然后检查这些路径上的数据库操作是否都有恢复逻辑。
# reader-critical 路径上的脆弱代码
def save_reading_progress(user_id, book_id, position):
db.execute(update_progress_sql) # 失败了怎么办?用户进度丢失。
# 加固后
def save_reading_progress(user_id, book_id, position):
try:
db.execute(update_progress_sql)
except DatabaseError:
# 先写入本地缓存,后台重试
cache.set(f"progress:{user_id}:{book_id}", position, ttl=86400)
queue.enqueue(sync_reading_progress, user_id, book_id, position)
# 不阻断用户——阅读继续
规则6:读者状态写入没有隔离
# ❌ 直接在当前事务中修改全局读状态
def mark_chapter_read(user_id, chapter_id):
state = db.query(ReadingState).filter_by(user_id=user_id).first()
state.last_chapter = chapter_id
db.commit() # 如果commit失败,状态不一致
# ✅ 状态变更必须隔离
def mark_chapter_read(user_id, chapter_id):
with db.begin_nested() as savepoint:
state = db.query(ReadingState).filter_by(
user_id=user_id
).with_for_update().first()
state.last_chapter = chapter_id
state.updated_at = func.now()
规则7:前端代码直接读取传输层错误细节
// ❌ AI Agent在前端常写的耦合代码
try {
await api.startReading(bookId);
} catch (error) {
// 直接读取axios响应的内部结构
const message = error.response.data.detail;
showError(message); // 后端改了错误格式,前端就炸
}
// ✅ 通过共享错误标准化层
try {
await api.startReading(bookId);
} catch (error) {
const normalizedError = normalizeApiError(error);
// normalizeApiError负责将任何后端响应转为统一格式
showError(normalizedError.message);
if (normalizedError.code === 'SUBSCRIPTION_REQUIRED') {
redirectToUpgrade();
}
}
tree-sitter实现思路:
- 在TypeScript/TSX文件中检测
error.response.data 的直接访问 - 任何对
error.response 内部结构的直接读取都必须通过normalizeApiError 包装
规则8:被吞掉的Promise拒绝和空catch块
// ❌ AI Agent会写出的各种静默失败
fetch(url).catch(console.error); // 失败了,日志有了,但UI不知道
try {
await criticalOperation();
} catch (e) {
// 空catch块——什么都没做
}
// ✅ 显式错误处理
try {
await criticalOperation();
} catch (e) {
captureException(e, { context: 'criticalOperation' });
setOperationStatus('failed', normalizeError(e));
// 确保UI表达了失败状态
}
tree-sitter实现思路:
- 检测
catch块中只有console.error/console.log而没有状态更新或错误上报 - 检测完全空的
catch块(连注释都没有) - 检测
.catch(console.error) 模式
接入指南:5分钟在你的项目中搭建

▲ 图3:5步接入指南流程
第一步:安装依赖
# Python后端
pip install tree-sitter tree-sitter-language-pack
# 或者通过pre-commit管理
# .pre-commit-config.yaml
repos:
- repo: local
hooks:
- id: error-handling-patterns
name: Guard centralized error handling patterns
entry: python scripts/check_error_handling_patterns.py
language: system
files: ^(backend/.*\.py|frontend/.*\.(ts|tsx))$
stages: [pre-commit]
第二步:编写检查脚本框架
# scripts/check_error_handling_patterns.py
import sys
from pathlib import Path
from tree_sitter import Language, Parser
from tree_sitter_language_pack import get_language, get_parser
PY_LANG = get_language('python')
TS_LANG = get_language('typescript')
TSX_LANG = get_language('tsx')
def check_python_file(filepath: str) -> list[str]:
"""检查Python文件中的错误处理反模式"""
issues = []
parser = get_parser('python')
tree = parser.parse(Path(filepath).read_bytes())
# 规则1: except后没有rollback或raise
issues.extend(check_db_exception_without_rollback(tree, filepath))
# 规则2: 模糊的except Exception
issues.extend(check_bare_except(tree, filepath))
# 规则3: IntegrityError被静默吞掉
issues.extend(check_silenced_integrity_error(tree, filepath))
return issues
def check_db_exception_without_rollback(tree, filepath):
"""使用tree-sitter查询检测数据库异常处理缺陷"""
issues = []
# 核心逻辑:遍历try-except节点
# 检测except块中是否有db操作但没有rollback
query = PY_LANG.query("""
(try_statement
body: (block) @try_body
(except_clause
(block) @except_block))
""")
captures = query.captures(tree.root_node)
# ... 具体检测逻辑
return issues
if __name__ == '__main__':
files = sys.argv[1:] or []
all_issues = []
for f in files:
if f.endswith('.py'):
all_issues.extend(check_python_file(f))
elif f.endswith(('.ts', '.tsx')):
all_issues.extend(check_typescript_file(f))
if all_issues:
for issue in all_issues:
print(f"❌ {issue}", file=sys.stderr)
sys.exit(1)
else:
print("✅ All error handling patterns are valid")
第三步:定义你的"关键路径"标记
Merrilin的做法是:在关键函数上使用装饰器标记,然后在tree-sitter检查时识别这些标记:
# 定义关键路径装饰器
def reader_critical(func):
"""标记此函数在读者关键路径上,需要额外的错误处理检查"""
func._reader_critical = True
return func
@reader_critical
def save_reading_progress(user_id, book_id, position):
# tree-sitter检查会识别这个标记,并施加更严格的规则
...
第四步:配置pre-commit
# .pre-commit-config.yaml 完整示例
repos:
- repo: pre-commit/pre-commit-hooks
rev: v4.6.0
hooks:
- id: check-yaml
- id: check-json
- id: check-merge-conflict
- id: detect-private-key
- id: trailing-whitespace
- id: end-of-file-fixer
- repo: local
hooks:
- id: error-handling-patterns
name: 🔒 Guard error handling patterns
entry: python scripts/check_error_handling_patterns.py
language: system
files: ^(backend/app/.*\.py|apps/(web|mobile)/src/.*\.(ts|tsx))$
stages: [pre-commit]
pass_filenames: true
- id: migration-naming
name: 🔒 Enforce Alembic migration naming
entry: python scripts/check_migration_naming.py
language: system
files: ^backend/alembic/versions/.*\.py$
stages: [pre-commit]
第五步:团队推广
最重要的不是技术实现,而是让团队理解"为什么prompt不够":
- 做一次演示:让AI Agent生成一个包含100行代码的功能,然后跑检查脚本——通常至少能拦截2-3个问题
- 建立"规则贡献"文化:任何人发现Agent反复犯同一类错误 → 封装成一条tree-sitter规则 → PR进来
- 渐进式部署:前两周只告警不阻断(
stages: [pre-commit] 加 verbose: true),等团队适应后再开启阻断
为什么这套方案比AI Code Review更好
你可能会问:已经有CodeRabbit、GitHub Copilot Code Review这些AI审查工具了,为什么还要手动写tree-sitter规则?
成本:AI Code Review按PR收费或消耗token配额。如果你的Agent每天提交10-20个commit,AI审查的成本会快速累积。而pre-commit + tree-sitter是本地运行、零成本、毫秒级。
反馈速度:AI审查需要等待PR创建→分配审查→返回结果。pre-commit在git commit时就立即给出反馈。从"写完代码"到"发现问题"的延迟从分钟级降到毫秒级。
确定性:AI审查有随机性——同一个模式昨天能被检测到,今天不一定。tree-sitter规则是确定性的——匹配就是匹配,不匹配就是不匹配。
边界清晰:你知道哪些规则是"硬性禁止"的。AI审查的边界模糊,有时会标记出"可能有问题"但实际没问题的代码,产生噪音。
常见踩坑与排障
坑1:tree-sitter解析失败但没报错
症状:某些文件静默跳过,检查结果总是PASS,但实际上文件中存在违规模式。
原因:tree-sitter对语法错误的文件会生成不完整的AST,某些节点缺失导致查询匹配不到。
解决:在检查脚本开头加一句文件语法校验:
if tree.root_node.has_error:
print(f"⚠️ {filepath}: syntax error, skipping tree-sitter checks")
return [] # 不要阻断,让lint工具处理语法问题
坑2:规则过于严格导致正常代码被拦截
症状:开发者的合法代码(如确实需要捕获所有异常的场景)被pre-commit拦截。
解决:添加抑制注释机制,Merrilin的做法是:
try:
risky_operation()
except Exception as e:
logger.exception("unknown error") # noqa: ERR-001
# ↑ ERR-001 是"禁止裸except"规则的编号
# 这告诉checker:"我知道我在做什么,这条规则放行"
坑3:数据库迁移文件被Agent写乱
症状:AI Agent看到大量的迁移文件后,开始"发明"自己的编号规则,如手动创建065_add_new_table.py。
解决:添加额外的迁移文件命名检查:
# scripts/check_migration_naming.py
import re
from pathlib import Path
MIGRATION_DIR = Path("backend/alembic/versions")
def check_migrations():
issues = []
for f in MIGRATION_DIR.glob("*.py"):
# 禁止手动编号的迁移文件
if re.match(r'^\d{3}_', f.name):
issues.append(
f"{f.name}: 禁止手动编号的迁移文件。"
f"请使用 alembic revision --autogenerate -m '描述' 生成"
)
# 禁止不是通过alembic创建的文件
content = f.read_text()
if "Create Date:" not in content:
issues.append(
f"{f.name}: 缺少Alembic生成标记。"
f"请用alembic revision命令创建迁移文件"
)
return issues
坑4:性能问题
症状:pre-commit检查越来越慢,每次commit都要等几秒。
解决:
- 使用
--changed-lines只检查变更的代码行(而非整个文件) - 对于大型仓库,考虑按模块拆分检查规则
- 如果检查时间超过2秒,使用
concurrent.futures.ProcessPoolExecutor并行执行
加分项:与其他Agent工具的协同
这套防线不是孤立存在的。它可以和你已有的AI开发工具形成协同:
- Claude Code + pre-commit:Claude Code在生成代码后执行
git add会触发pre-commit。如果检查失败,Claude Code会看到错误输出并尝试修复——形成"生成→检查→修复"的自动循环。 - Hermes Agent + pre-commit:在Hermes的cron任务中配置代码生成+pre-commit检查的流水线,确保自动生成的代码不会污染仓库。
- GitHub Actions + pre-commit:CI中再次运行同样的检查作为双重保险(pre-commit可能会被
--no-verify跳过)。
总结
给AI Agent的代码上锁,不是不信任它——恰恰相反,正是因为充分信任它的产出速度,才需要用确定性更强的防线来匹配。
核心要点回顾:
- prompt约束不够硬——AI Agent总是会在生成长代码时走捷径
- tree-sitter + pre-commit——毫秒级、零成本、确定性的代码质量防线
- 8条核心规则——从数据库事务安全到前端错误处理,覆盖AI Agent最常见的坏模式
- 5分钟接入——pip install → 写脚本 → 配置pre-commit → 团队推广
- 渐进式部署——先告警、再阻断,让团队适应期有缓冲
如果你也在用AI Agent做生产级开发,不妨今天就在你的项目里加一条规则试试——就从禁止except Exception: pass开始。
#AI创业 #Agent工坊 #AI编程 #代码质量 #pre-commit
本文由AI辅助创作,经人工审核编辑发布
