
你用的每一个AI编程助手(Claude Code、Cursor、Hermes Agent)底层都是同一套工具逻辑。拆解完这7个工具,你就理解了Agent为什么能帮你写代码、搜文件、改配置——不是因为AI聪明,是因为你给了它正确的手和眼睛。
前言
如果你用过Claude Code、Cursor或者Hermes Agent,你肯定体验过这样的时刻:你说"帮我看看这个项目里所有TODO",然后Agent像个人类程序员一样搜索文件、读取内容、汇总结果。你甚至可能觉得它"理解"了你的项目。
但真相是:Agent不是魔法。它只是被喂了一套精心设计的工具(Tools),然后按照固定的流程"调工具→看结果→决定下一步"。理解这套工具机制,是每个AI创业者从"用Agent"到"造Agent"的必经之路。
这篇文章会带你从零实现一个具备完整文件操作能力的AI Agent——不是调别人的API,而是亲手写出那7个让Agent"有手有眼"的核心工具。读完你会明白Hermes Agent和Claude Code的底层工具箱长什么样,以及为什么有些Agent好用、有些不好用的根本原因就在工具设计上。
本文思路参考了 Roger Oriol 的 "Build A Basic AI Agent From Scratch: Tools" 系列教程(2026年5月发布),结合实战经验做了中文语境下的扩展和优化。
什么是Agent工具?
在AI Agent的语境下,工具(Tool)就是一个可以被LLM自主调用的函数或程序。它可以是:
- 最简单的Python函数(如读取一个文件)
- 一个shell命令的执行器
- 一个MCP(Model Context Protocol)服务器,背后连接着数据库或第三方API
工具就是Agent的"手"和"眼睛"。没有工具,LLM只能基于训练数据和你给的上下文来回话;有了工具,它可以主动获取新信息、操作文件系统、调用外部服务。
Agent如何调用工具?
早期的Agent实现依赖"文本约定":让LLM输出特定格式的文本(比如 Action: web_fetch),然后Agent框架解析这段文本并执行对应函数。这种方式非常脆弱——LLM稍微不按格式输出,整个流程就断了。
现代LLM已经内置了原生工具调用(Native Tool Calling)。像GPT-4、Claude、DeepSeek等模型都经过专门的微调,能输出结构化的JSON来表示工具调用请求。这带来了几个关键好处:
- 内置校验:模型输出的是结构化的函数名和参数JSON,框架可以做类型校验
- 减少幻觉:模型被训练为只在应该调用工具时才输出工具调用,不会随机"脑补"函数名
- 多工具并行:模型可以一次返回多个工具调用,Agent框架并行执行它们
下面我们就来实现一个完整的工具系统。
核心工具一:run_bash — Agent的万能手
这是所有工具里最强大也最危险的一个。给它bash权限意味着Agent可以做电脑上任何事——这既是力量,也是风险。为什么大部分Agent框架都选择保留这个工具?因为让LLM直接调用已有的命令行程序,比给每个命令行工具都单独包装一个Python函数要高效得多。LLM已经知道git、npm、pip、curl这些命令怎么用,直接给它bash权限就是对已有知识的最大利用。
⚠️ 安全提示:生产环境中必须加上沙箱隔离、命令白名单或至少用户确认机制。这部分在Roger Oriol系列教程的后续章节中有专门讨论。
核心工具二:read_file — Agent的眼睛
注意两个设计细节:
- 分页读取(offset + limit):防止Agent一次性读入超大文件撑爆上下文窗口。这是Hermes Agent的
read_file工具的设计来源——你每次看到"Read 200 lines from ..."就是这个逻辑。 - 行号输出(
offset + i: line):返回的每一行都带行号,这样Agent后续可以用行号精准定位需要修改的位置。这个细节看似简单,但如果没有它,Agent定位代码的能力会大打折扣。
核心工具三:glob_files — 文件系统的搜索引擎
这个工具解决了"Agent不知道项目里有什么文件"的问题。当你对Claude Code说"找一下所有定义了这个接口的地方",Agent的典型操作流程是:glob_files("*.py") → 找到所有Python文件 → grep("interface_name", path="src/") → 精准定位。
glob_files和grep的配合,就是Agent在代码库里"找东西"的标准模式。
核心工具四:grep — 代码内容的高速扫描仪
grep是整个工具链中被调用频率最高的工具之一。Claude Code在每次代码修改前后的验证环节都会密集调用grep。关键设计点:
- 正则表达式搜索而非简单字符串匹配——这让Agent能搜索"所有以
def handle_开头的函数" - include参数过滤文件类型——避免搜索二进制文件或限制到特定语言
- 返回文件路径+行号+内容——Agent拿到结果后可以直接用edit_file精准修改
核心工具五:write_file — Agent的输出之手
这个工具看似简单,但有一个非常重要的设计:自动创建父目录。Agent不需要关心目录结构是否已存在——它只管写,框架自动处理路径。这极大减少了Agent因"目录不存在"而失败的场景。
核心工具六:edit_file — 外科手术式的精准修改
edit_file和write_file的区别很关键:
| write_file | edit_file | |
|---|---|---|
| 操作方式 | 整体替换 | 精准替换一个片段 |
| 安全性 | 低(可能覆盖未读内容) | 高(只改指定部分) |
| 适用场景 | 创建新文件 | 修改已有文件 |
这就是为什么Hermes Agent的patch工具(等价于edit_file)是代码修改的首选——它比"读全部→改→写全部"安全得多,不会因为Agent没读完文件就覆盖掉后面的内容。
核心工具七:webfetch — 联网获取实时信息
这个工具让Agent突破了"知识截止日期"的限制。设计要点:
- 限制协议(只允许http/https)——防止Agent通过
file://读取本地敏感文件 - HTML → 纯文本——用BeautifulSoup剥离所有标签,节省token
- 2MB上限——防止超大页面撑爆上下文
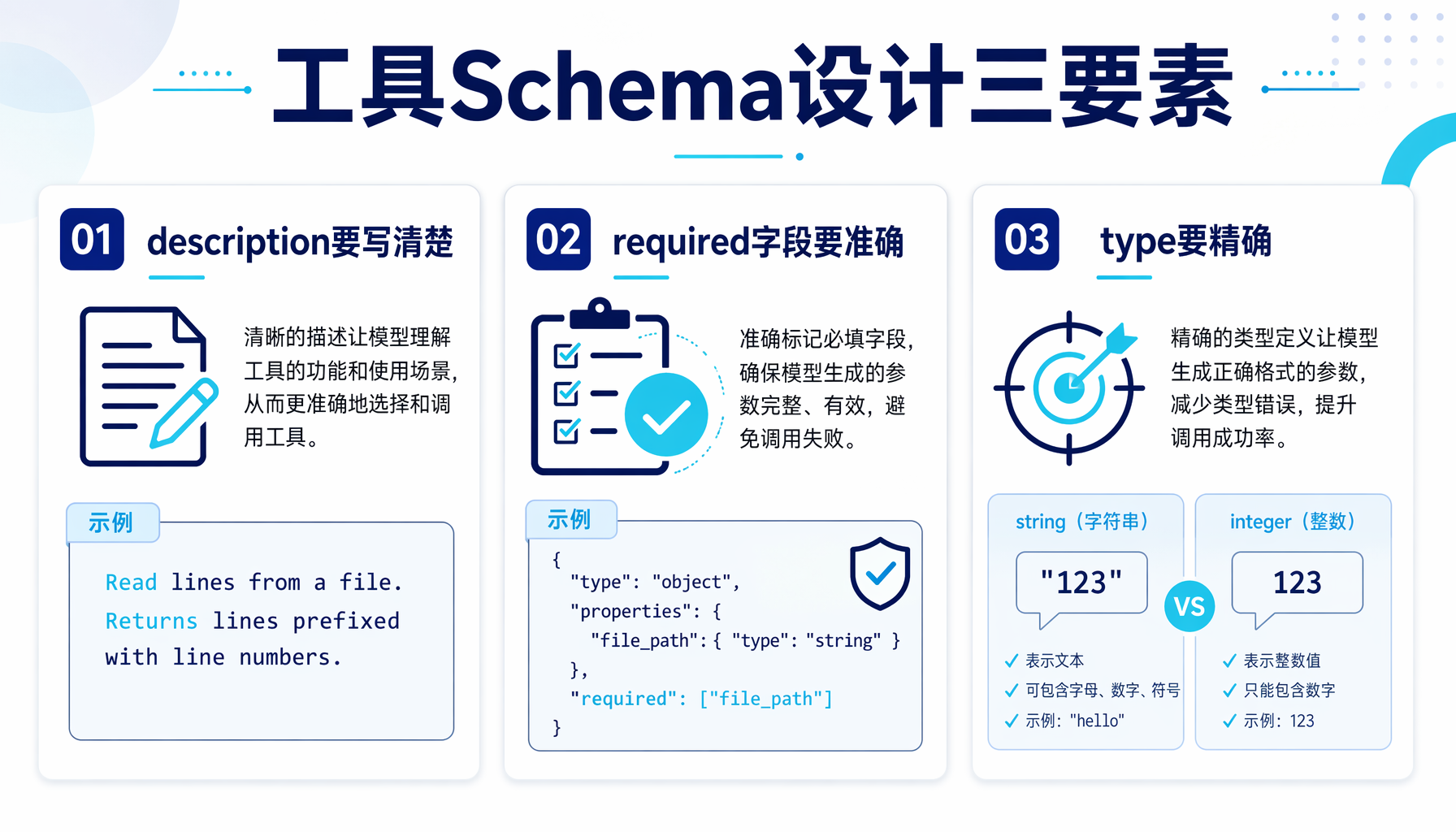
工具Schema:让LLM知道你能干什么
工具实现好了,但LLM不知道它们的存在。你需要用JSON Schema描述每个工具:
这个Schema是OpenAI Function Calling格式,但几乎所有主流模型(Claude、DeepSeek、Gemini)都兼容这个格式。关键注意点:
- description要写清楚:LLM靠description判断什么时候该用什么工具。写"Read a file"太模糊,要写"Read lines from a file. Returns lines prefixed with line numbers."
- required字段要准确:标记哪些参数是必须的,LLM会根据这个决定是否省略可选参数
- type要精确:
stringvsinteger影响LLM传参的正确性
▲ 工具Schema设计三要素:description、required、type的核心要点
Agent Loop:让工具跑起来
最后一步是修改Agent的主循环,集成工具调用:
这个Agent Loop的工作流程:
- 用户输入 → 追加到消息历史
- 调用LLM(带上tools参数)
- LLM如果返回tool_calls → 执行工具 → 将结果追加到消息 → 再次调用LLM
- LLM如果返回普通文本 → 输出给用户 → 等待下一次输入
关键设计:内层的while True循环让Agent可以连续调用多个工具,直到它认为信息足够回答用户为止。这就是为什么Claude Code会"读文件→搜代码→再读文件→修改→验证"——每一轮都可能触发工具调用。
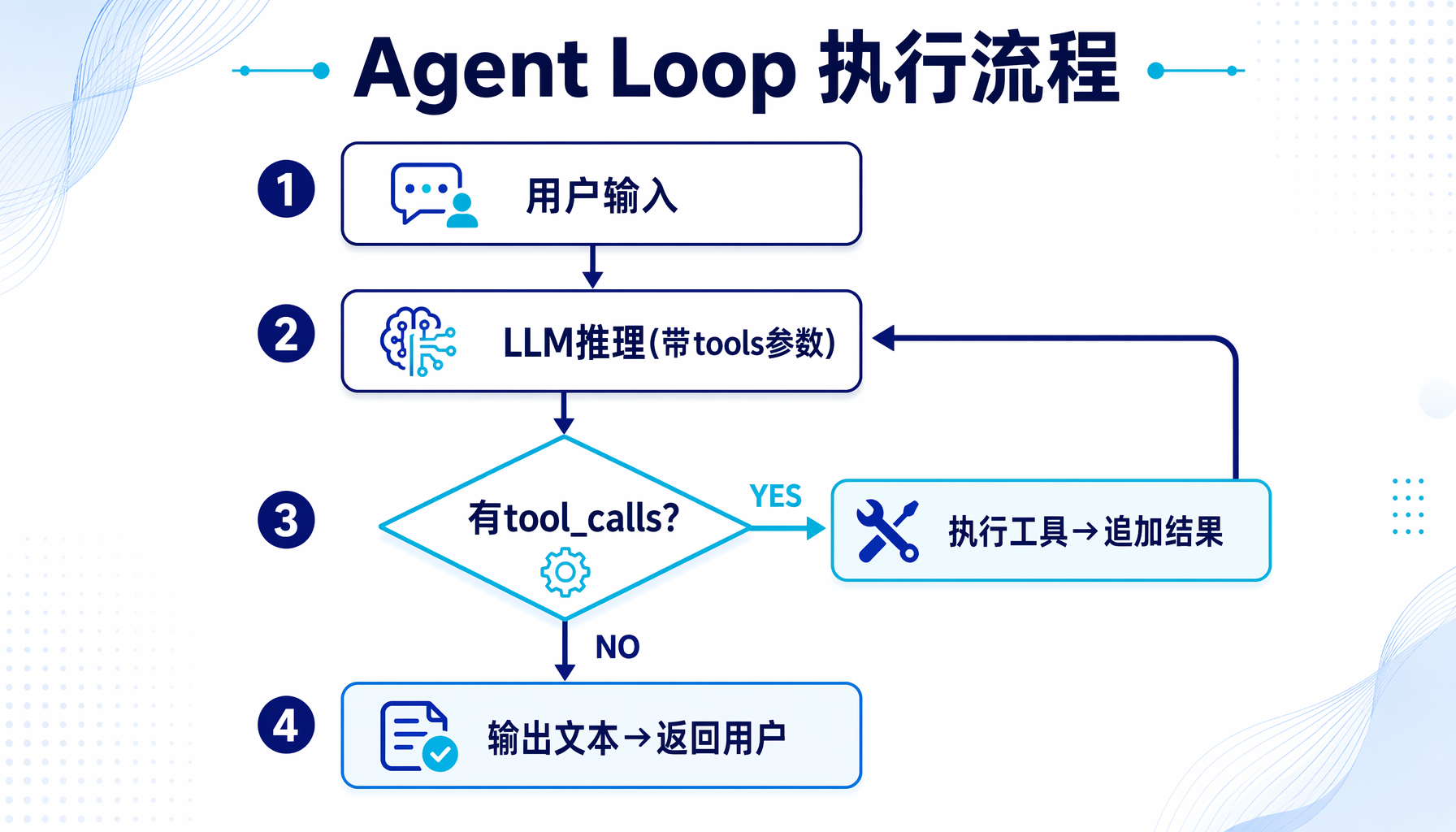
▲ Agent Loop执行流程:从用户输入到工具调用再到最终输出的完整循环
实战:让Agent帮你干活
完整的Agent代码已经在开源社区中发布。让我们看一个实际运行案例:
Agent自动完成了"获取网页→解析内容→生成Markdown→写入文件"的完整流程。它自己决定了要调用webfetch和write_file两个工具,并且正确地格式化了输出内容。
你已经实现了一个迷你版的Claude Code
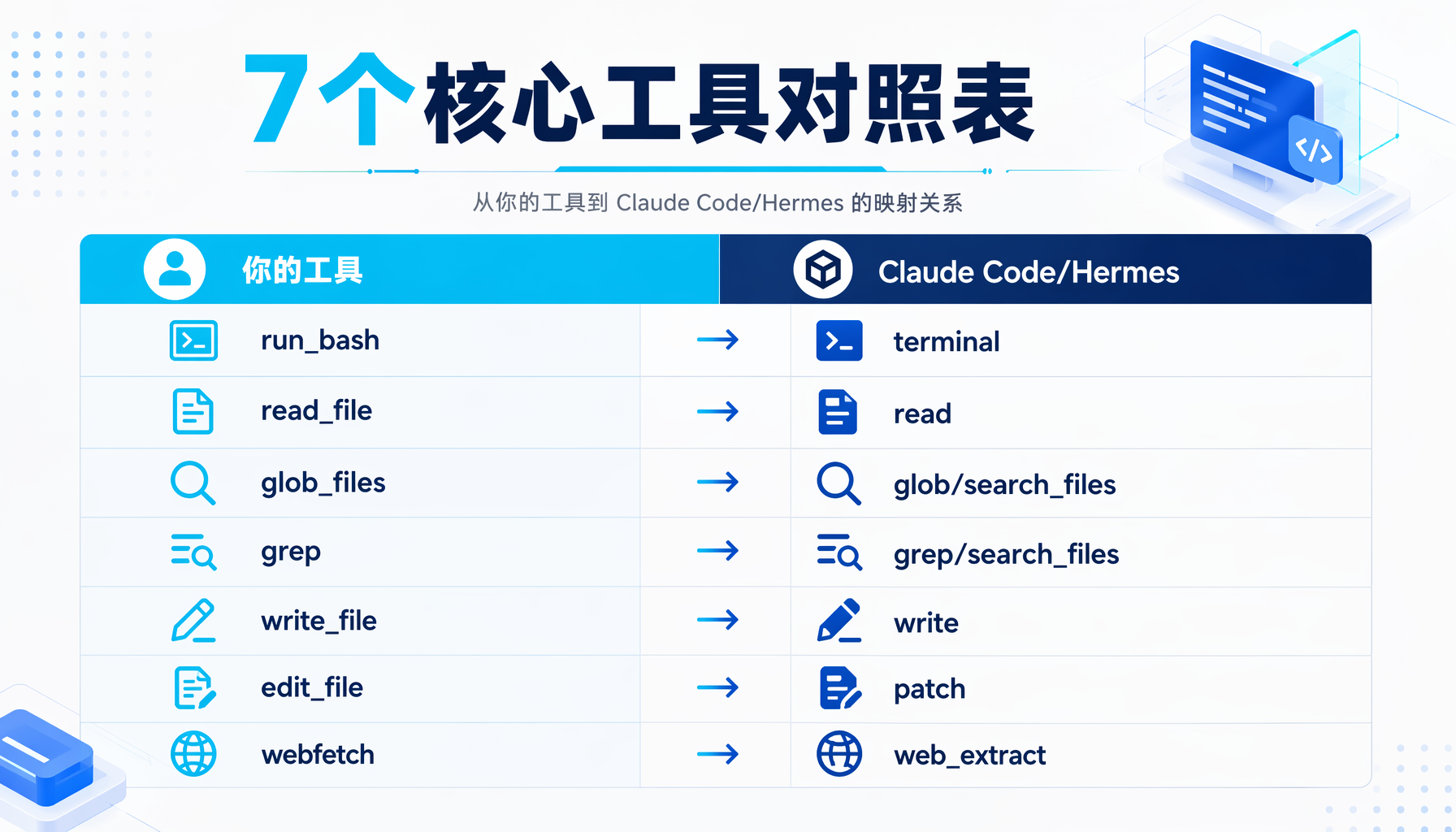
现在回头看,你写的这个Agent工具系统,跟Claude Code、Hermes Agent、Cursor的底层工具箱逻辑是完全一致的:
| 你的工具 | Claude Code | Hermes Agent |
|---|---|---|
| run_bash | terminal | terminal |
| read_file | read | read_file |
| glob_files | glob | search_files(target=files) |
| grep | grep | search_files(target=content) |
| write_file | write | write_file |
| edit_file | edit | patch |
| webfetch | web_fetch | web_extract |
▲ 7个核心工具对照表:你的工具与Claude Code/Hermes Agent的映射关系
踩坑与排障
坑1:工具结果太长撑爆上下文
症状:Agent调用grep后,返回了几万行结果,后续对话开始"失忆"。
方案:给工具结果加上截断逻辑,超过一定长度自动截取并附带摘要。比如:
坑2:Agent陷入无限工具循环
症状:Agent反复调用同一工具,永远不给出最终回答。
方案:设置最大工具调用轮次(如10轮),超过后强制Agent给出回答:
坑3:工具描述太模糊导致LLM不会用
症状:Agent明明有grep工具,但遇到搜索需求时却用read_file暴力读取每个文件。
方案:工具的description要给出使用场景提示。比如grep的描述不要只写"Search file contents",而应该写"Search file contents for a regex pattern. Use this to find where a function/variable is defined or used across the project. Much faster than reading each file."
常见问题(FAQ)
Q: 我应该用原生工具调用还是MCP? A: 如果是自己写Agent,从原生工具调用开始。MCP的优势在于跨Agent复用和标准化,但如果只是做一个内部工具,7个Python函数+JSON Schema就够了。MCP的学习曲线不值得在MVP阶段投入。
Q: 安全如何保障? A: 至少做三层防护:① bash工具加命令白名单 ② 文件操作限制在项目目录内 ③ 危险操作(rm -rf、sudo)加人工确认。Roger Oriol系列后续章节有详细的沙箱方案。
Q: 为什么我写的工具Agent不用? A: 99%的情况是Schema写得不清楚。检查三个东西:description是否描述了"什么时候用"、参数说明是否给出了示例值、required字段是否准确。LLM对模糊的Schema容忍度极低。
Q: 这7个工具够用吗? A: 对于80%的场景(代码编写、文件管理、网页抓取)完全够用。当你需要数据库操作、API调用、文件上传下载等更复杂的能力时,再加对应的专用工具即可。核心原则是"够用就好",工具越多,LLM选择工具的错误概率越高。
总结
这7个核心工具组成的工具箱,就是每个AI编程Agent的"标准配置"。理解了它们的设计逻辑,你就理解了为什么Agent有时候"聪明"有时候"笨"——聪明是因为工具描述清晰、Schema准确;笨是因为工具设计有缺陷,给了Agent错误的信息或限制。
下一步:你现在写的这个Agent还不能像Claude Code那样处理长任务——它会"迷路",做几步就忘了最初的目标。下一篇我们会加入规划(Planning)和任务管理工具,让你的Agent不仅能干活,还能自己拆任务、定计划、跟踪进度。
完整代码参考 Roger Oriol 博客系列配套仓库,本文基于其第2部分"Tools"系列改造为中文实操教程。
#AI创业 #Agent工坊 #AI编程 #工具设计 #一人公司
本文由AI辅助创作,经人工审核编辑发布