
给 Agent 40+ 工具和开放式任务,它会把同一个文件读五遍、在 Review 阶段调用 Edit、测试没跑完就部署。Statewright 的解法不是换更大的模型,而是用 Rust 状态引擎把问题空间切小——每个阶段只给 5 个工具,拒绝就告诉你该怎么做。研究数据:两个本地小模型从 2/10 正确率干到 10/10。
前言
你和我都有过这种经历:让 Claude Code 修一个 bug,它反复读同一个文件四遍,每次都在"理解代码"和"动手修改"之间来回横跳。你看着 token 燃烧器疯狂运转,心里默默计算这轮对话的花费。
这不是 prompt 写得不好,是架构问题。
一个拥有 40+ 工具、无约束状态的 Agent,本质上是一个在巨大搜索空间里随机游走的对话模型。它不是在"思考",而是在"试"。试错了就回退,回退了再试——直到 token 用完或你手动喊停。
Statewright 的解法简单到令人意外:不要给 Agent 所有工具,只给当前阶段需要的工具。 用确定性的 Rust 状态引擎在 MCP 层面拦截工具调用,这个引擎不依赖任何 LLM——它只做一件事:检查当前状态允许哪些工具,不允许的直接拒绝并告诉你该怎么过渡到下一阶段。
这篇文章带你从零上手 Statewright:安装、配置工作流、理解核心 guardrail 机制、自建自定义工作流,最后上自托管。
背景:为什么 Agent 需要状态机
问题不是模型能力,是搜索空间
当前主流的 AI 编程 Agent——Claude Code、Codex、Cursor——都有一个共同的架构假设:给模型全部工具,让它自己决定什么时候用什么。 这在简单任务上(改一行代码、加一个函数)效果很好,但一旦任务变复杂(修 bug 需要先定位 → 再改 → 再测试 → 可能回退再改),Agent 就会陷入"工具选择瘫痪"。
具体表现:
- Read-loop death spiral:反复读同一组文件,每次都说"我理解了",然后继续读
- 跨阶段工具乱用:在 Review 阶段用 Edit 改代码,在 Testing 阶段用 Write 覆盖测试
- 跳过关键步骤:测试没跑完就标记完成,部署前不检查 lint
更深层的问题是:Agent 没有"阶段"概念。 它只看到一长串对话历史和 40 个工具,无法区分"现在在读代码"和"现在在改代码"应该用不同的工具集和行为约束。
解决方案:确定性的状态约束
Statewright 的核心洞察是:用确定性的代码(而非 LLM prompt)来定义 Agent 的行为边界。
传统做法——在 system prompt 里写"不要在 review 阶段编辑文件"——是软约束,模型可以忽略。Statewright 的做法是硬约束:在 MCP hook 层面拦截工具调用,如果当前状态不允许 Edit,直接返回错误并告诉 Agent 如何过渡。
这相当于给 Agent 装了一个"行为护栏",而不是"行为建议"。护栏是代码,建议是文字——前者一定生效,后者不一定。
Statewright 核心机制拆解
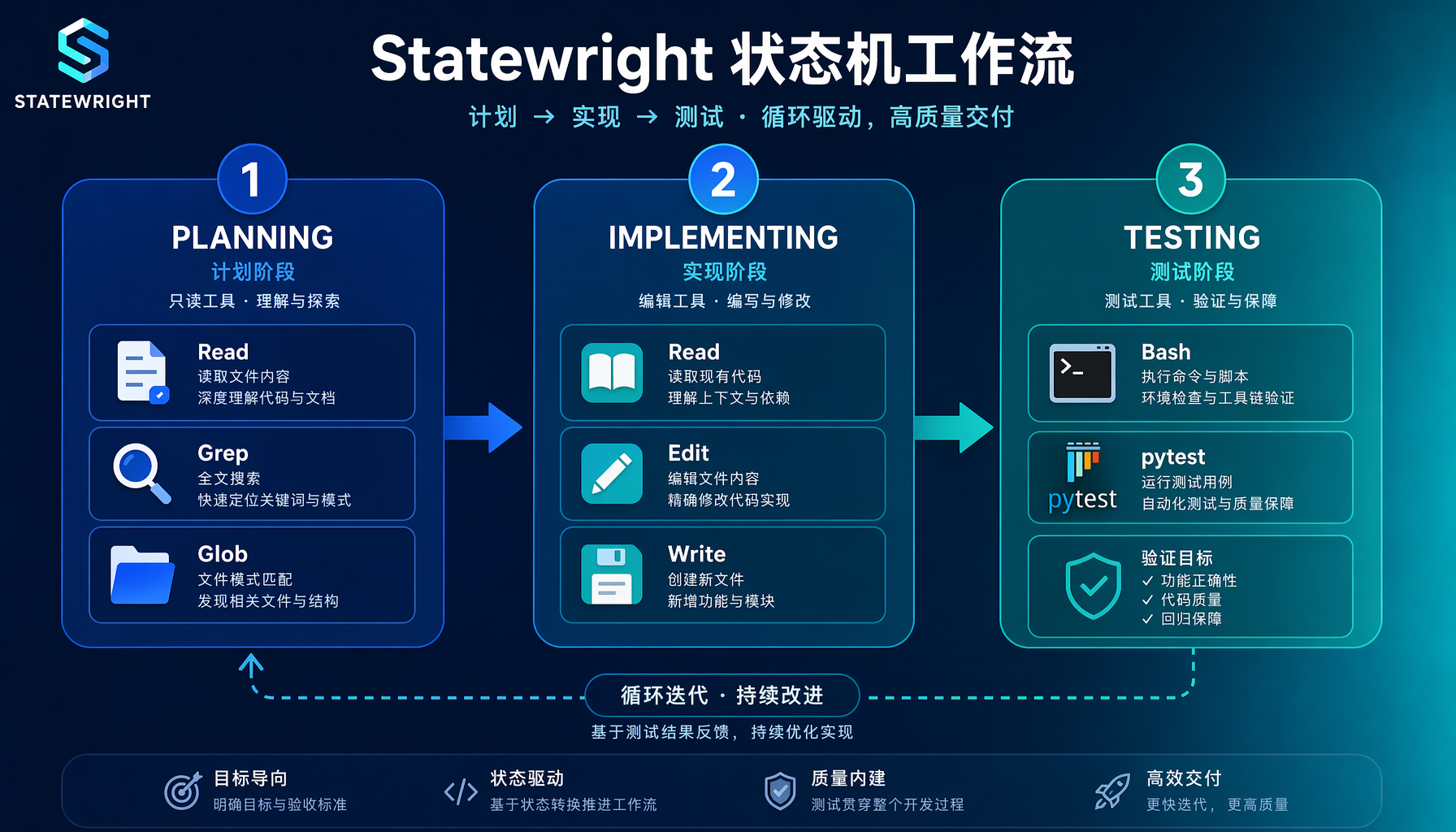
▲ 图1:Statewright 状态机工作流 — planning(只读)→ implementing(编辑)→ testing(测试),每阶段只有3-5个工具,测试失败自动回退到 implementing
1. 状态机定义(Rust 引擎,无 LLM 参与)
Statewright 的核心是一个纯 Rust 实现的状态引擎。它读入一个 JSON 格式的工作流定义,在 Agent 每次工具调用时检查:
关键是最后一步:拒绝不只是说"No",而是告诉 Agent "如果你想用 Edit,需要先过渡到 implementing 状态,触发条件是 READY"。 这比简单的工具拦截要多一层引导。
引擎完全确定性——同一个状态定义、同一个输入,永远得到同一个输出。不依赖任何 LLM 推理。
2. 十层 Guardrail(从工具拦截到环境隔离)
Statewright 提供了 10 层 guardrail,不是让你全部开启,而是按需组合:
| Guardrail | 作用 | 典型场景 |
|---|---|---|
| Per-state tool enforcement | 每个状态只暴露允许的工具 | planning 阶段只有 Read/Grep/Glob |
| Bash discernment | 即使 Bash 被允许,也拦截 echo > file、rm -rf、sed -i、脚本解释器 | 防止"允许跑测试"变成"允许删代码" |
| Edit guards | 限制单次 diff 行数、单状态编辑文件数 | 防止 Agent 一次改太多导致回滚困难 |
| Command allow-lists | Bash 只能跑指定前缀的命令 | testing 阶段只允许 pytest、cargo test |
| Conditional transitions | 基于上下文数据判断是否过渡 | test_result eq pass 才允许从 testing 到 completed |
| Approval gates | 某些过渡需要人工确认 | 部署前暂停,等人点"批准" |
| Interrupts | 编辑匹配 glob 模式的文件时自动跳转到验证状态 | 改了 .env 立即触发安全检查 |
| Fork/join | 并行或串行分支,全部完成或任一完成时汇合 | 同时跑单元测试和集成测试 |
| Environment scoping | 隐藏敏感环境变量,替换为安全值 | 隐藏 PROD_DB_URL,Agent 只能看到 staging URL |
| Session isolation | 按 session ID 隔离状态 | 多窗口同时工作互不干扰 |
3. 工作流定义(JSON,Agent 可自动生成)
工作流用 JSON 定义,结构清晰:
这个工作流定义了经典的"修 bug"三阶段:
- planning:只能读代码(Read/Grep/Glob),最多迭代 8 次,触发 READY 后进入 implementing
- implementing:可以读+编辑(Read/Edit/Write),每次最多改 20 行,每个文件最多改 3 次,完成后进入 testing
- testing:只能读+跑测试(Read + 指定测试命令),测试通过则完成,失败则回到 implementing
Workflow 不需要手写——你可以让 Agent 通过 statewright_create_workflow MCP 工具自动生成。扔给它一个任务描述,它会输出完整的 JSON 定义。
上手指南:15 分钟从零到跑通
第一步:安装插件
在 Claude Code 中:
浏览器会自动打开 statewright.ai,注册账号 → 生成 API Key → 粘贴回终端 → 完成。
支持的 Agent 及集成方式:
| Agent | 集成方式 | 约束类型 |
|---|---|---|
| Claude Code | Hooks + MCP | 硬约束(工具级拦截) |
| Codex | Hooks + MCP | 硬约束 |
| opencode | TypeScript 插件 | 硬约束(alpha) |
| Pi | TypeScript 扩展 | 硬约束(含本地模型优化) |
| Cursor | MCP + rules | 建议约束(MCP 无法拦截 Cursor 原生工具) |
注意:Cursor 的 MCP 集成只能注入规则到上下文,无法在工具层拦截——模型可以忽略。如果你用 Cursor 做核心开发,建议搭配 Claude Code 或 Codex 在关键流程中启用硬约束。
第二步:启动第一个工作流
注意三个关键行为:
- 每个阶段开始时,Agent 只能看到当前阶段允许的工具(planning 阶段没有 Edit 和 Bash)
- 阶段过渡是 Agent 主动触发的(通过
statewright_transition),不是计时器或外部条件 - 过渡时引擎检查 guard 条件,不满足则拒绝过渡
第三步:创建自定义工作流
让 Agent 帮你生成工作流:
Agent 会调用 statewright_create_workflow 生成完整 JSON,你可以在 statewright.ai/workflows 的可视化编辑器中微调工具列表、命令白名单和环境变量。
第四步:接入你的项目 CI
把 Statewright 工作流嵌入 CI pipeline:
这里的关键是:代码审查不再依赖"希望 Agent 按要求做",而是用状态机强制它按阶段执行——先 read-only 分析,再逐文件给出建议,最后输出 review 报告。Agent 不能在分析阶段就修改代码。
研究数据:小模型从 2/10 到 10/10 的秘密

▲ 图2:有无状态约束的对比 — 同样模型、同样硬件、同样任务,加状态约束后从20%正确率提升到100%
Statewright 团队在一个 5 任务 SWE-bench 子集上跑了实验,结果令人印象深刻:
| 模型 | 大小 | Bug Fix(26行修改) | SWE-bench(5任务) |
|---|---|---|---|
| gemma3 | 3.3GB | ❌ 失败 | ❌ 失败 |
| gemma4:e2b | 7.2GB | ✅ 通过* | ❌ 失败 |
| gpt-oss:20b | 13.8GB | ✅ 通过 | ✅ 通过(5/5) |
| gemma4:31b | 19.9GB | ✅ 通过 | ✅ 通过(5/5) |
| llama3.3 | 42.5GB | ✅ 通过 | ✅ 通过(2/2)† |
* 需要专门的 edit_line 工具适配。† 仅测试了 5 个任务中的 2 个。
关键发现:
- 13GB 是分水岭。低于这个阈值的模型能识别 bug 但无法生成精确的编辑(倾向于重写整个文件)。这是模型能力限制,不是 Statewright 的问题。
- 两个本地模型(gpt-oss:20b 和 gemma4:31b)开 Statewright 后从 2/10 passing 升到 10/10。同样任务、同样硬件,加了状态约束后正确率从 20% 飙到 100%。
- 大模型的收益在"结构"层面:即使你用 Claude 4 级别的模型,状态机也能打破 read-loop death spiral,把工具空间缩小到模型能专注推理而非到处试探的程度。
这个结果对 AI 创业者意味着什么?你不需要接入最贵的 API 来获得可靠的 Agent 行为。 用本地小模型 + 正确的状态约束,可以在成本极低的情况下跑通核心工作流。这对一人公司的经济模型意义重大。
自托管方案:不用云服务也能跑
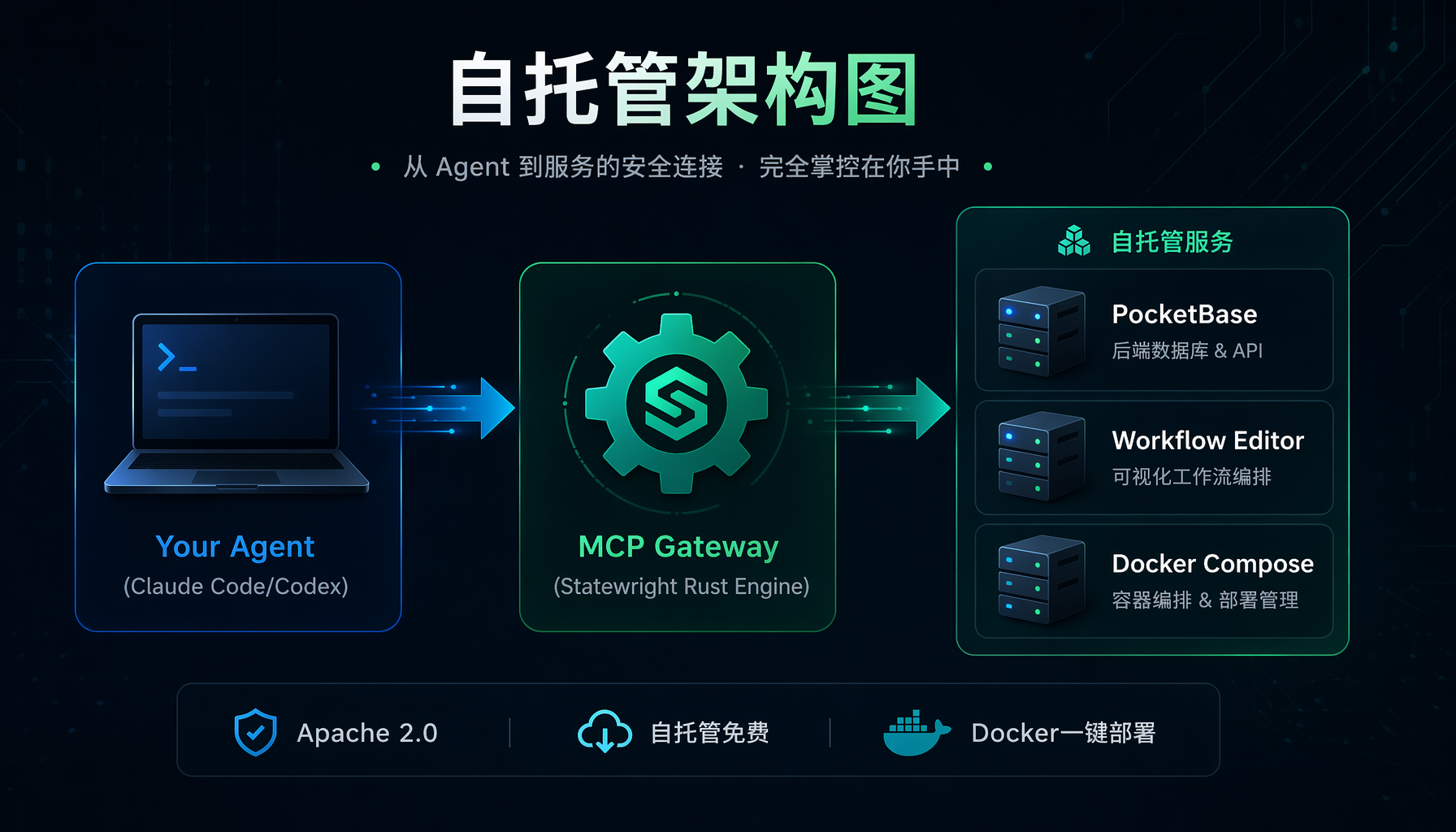
▲ 图3:Statewright 自托管架构 — Agent 通过 MCP Gateway(Rust 引擎)连接到 PocketBase + Workflow Editor + Docker Compose,全部 Apache 2.0 许可
Statewright 提供了完整的 Docker Compose 自托管方案:
这个命令会启动三个容器:
- PocketBase:工作流存储和运行历史
- MCP Gateway:工具拦截层,所有 Agent 的工具调用经过这里
- Workflow Editor:可视化编辑器(和云版一样)
核心引擎(crates/engine)和 Agent 层(crates/agent)是 Apache 2.0 许可,可嵌入无运行时依赖。MCP Gateway 是 FSL-1.1-ALv2(2029 年转为 Apache 2.0)。个人开发者和单团队自托管在 FSL 许可下完全免费。
云版定价(statewright.ai):
| 方案 | 工作流数 | 月过渡次数 | 运行历史 | 价格 |
|---|---|---|---|---|
| Free | 3 | 200 | 72小时 | $0 |
| Pro | 10 | 2,500 | 7天 | $29/月 |
| Team | 30 | 10,000 | 90天 | $99/月 |
对于个人 AI 创业者,Free 方案足够日常使用。如果你的 Agent 调用频繁(每天超过 6-7 次过渡),建议上 Pro 或自托管。
边界与注意事项
- 需要 Agent 支持 MCP 或 Hooks。如果用的是不支持 MCP 的轻量 Agent,Statewright 无法在工具层拦截。好消息是 Claude Code、Codex、opencode 都原生支持。
- 工作流太紧会导致 Agent 卡住。如果你的
max_iterations设太小或allowed_tools太窄,Agent 可能在一个状态下反复尝试但无法完成任务。statewright_deactivate是逃生舱——随时可以关闭工作流回到自由模式。 - Cursor 只有建议约束。因为 Cursor 的架构限制,MCP 无法拦截它的原生工具调用。如果你用 Cursor,Statewright 可以把规则注入上下文但模型可能忽略。
- 研究结果来自 5 任务子集,不是完整的 2294 实例 SWE-bench。但这个子集覆盖了典型的修 bug 场景(定位 → 修改 → 验证 → 可能回退),对日常开发有代表意义。
- Bash discernment 不等于沙箱。它拦截了已知危险模式(
rm -rf、echo > file、sed -i),但不能替代完整的容器隔离。生产环境建议在 Docker 容器内运行 Agent + Statewright。
实战建议:按场景配置工作流
场景一:日常 Bug 修复(个人开发)
场景二:代码审查(团队使用)
注意:Review 状态只有 Read 工具——Agent 可以阅读代码但不能修改。这确保了审查和分析是分离的。场景三:生产部署(带审批门禁)
`requires_approval: true` 意味着从 test 过渡到 deploy 之前会暂停,等人点确认。这在生产环境中是最基本的保险。场景四:AI 内容创作(一人公司)
常见问题(FAQ)
Q1:Statewright 和 prompt engineering 有什么区别?
Prompt engineering 是软约束——你在 system prompt 里写"不要做 X",模型可以忽略。Statewright 是硬约束——在 MCP hook 层拦截工具调用,模型根本看不到被禁止的工具。软约束靠运气,硬约束靠确定性代码。
Q2:我的 Agent 没有 MCP 支持,还能用吗?
当前支持的 Agent 列表:Claude Code(Hooks + MCP)、Codex(Hooks + MCP)、opencode(TypeScript 插件)、Pi(TypeScript 扩展)。如果你的 Agent 不在此列但支持任意 Hook 系统,可以提 Feature Request 或参考现有插件自行适配。核心引擎是 Apache 2.0,适配难度不高。
Q3:工作流定义太复杂,我不会写 JSON 怎么办?
你不需要手写 JSON。让 Agent(Claude Code 或 Codex)调用 statewright_create_workflow,用自然语言描述你的工作流,Agent 会输出完整的 JSON。然后到 statewright.ai/workflows 的可视化编辑器中微调。
Q4:状态机会不会限制 Agent 的创造力?
取决于你的场景。修 bug 不需要创造力——需要的是正确性。代码审查需要的是系统性,不是发散思维。在这些场景下,约束不是限制,是保障。如果你需要 Agent 做创造性探索(如架构设计),可以不用状态机,或者在探索阶段用更宽松的工作流(只限制危险操作,不限制读/写工具)。
Q5:自托管和云版的功能差异?
功能上完全一样。云版多了运行历史、团队协作和自动备份(PocketBase 数据库)。自托管需要你自行管理 PocketBase 实例和数据备份。核心引擎和 Agent 层代码完全相同。
总结:Agent 可靠性不是靠更大模型解决的
Statewright 给 AI 创业者的启示很清楚:
- Agent 的不可靠不是模型能力问题,是架构问题。 给 40+ 工具无约束地跑,无论多大模型都会 flail。
- 确定性的代码约束 > 不确定的 prompt 建议。 状态引擎没有概率,只有 true/false。
- 小模型 + 好架构 > 大模型 + 烂架构。 研究数据已经证明了这一点——13GB 本地模型开状态机后跑通 SWE-bench,成本是 Claude API 的零头。
- 硬约束在 MCP/hook 层实现,不是 prompt 层。 这是 Statewright 和其他"Agent 护栏"方案的本质区别。
对于正在搭 Agent 工作流的一人公司创业者,Statewright 值得立刻加入你的工具栈。从 Free 方案开始,用一个 bugfix 工作流跑两周,你会发现 Agent 的行为从"需要盯着"变成"可以信任"——这种信任感,是 AI Agent 从实验品变成生产力工具的关键一步。
风险提示:Statewright 仍处于早期阶段(2026 年 5 月首次公开发布),API 和插件接口可能变动。生产环境使用前建议在 staging 环境充分测试。自托管需要 Docker 环境和基本的运维能力。研究数据来自受限测试集,实际项目效果以你的实际使用为准。
参考来源:
- Statewright GitHub 仓库(github.com/statewright/statewright)
- Statewright 官方文档(docs.statewright.ai)
- HN 讨论:Show HN: Statewright – Visual state machines that make AI agents reliable(126 points,2026-05-12)
- Statewright 研究简报(statewright.ai/research)
- HN 评论区多位开发者的实战反馈
本文由AI辅助创作,经人工审核编辑发布