
OpenClaw 2026.6.1-beta.1 发布:引入"策略先行+模型审核+人工兜底"的三级安全架构,同时加强9大即时通讯渠道稳定性。AI Agent 正在从"需要人盯着"走向"值得信任"。
事件回顾
6月1日,OpenClaw 发布了 2026.6.1-beta.1 版本,这是继5月底密集迭代后的又一次重要更新。与此同时,OpenClaw 官方博客发表了题为《Safer Than YOLO: Auto Mode for Exec Approvals》的深度文章,正式披露了一个全新的 Agent 命令执行安全模式——Auto 模式。
这篇文章由 OpenClaw 首席架构师 Vincent Koc、核心维护者 Jesse Merhi(Atlassian)和 Josh Avant 联合撰写,标志着 OpenClaw 在"让 AI Agent 安全地自主执行系统命令"这件事上迈出了关键一步。
在此之前,OpenClaw 的命令执行只有两种极端模式:Ask Human(每一条命令都要人工点"同意")和 YOLO(完全跳过审批,适用于沙箱环境)。Auto 模式则在这两者之间建立了一个聪明的中间地带。
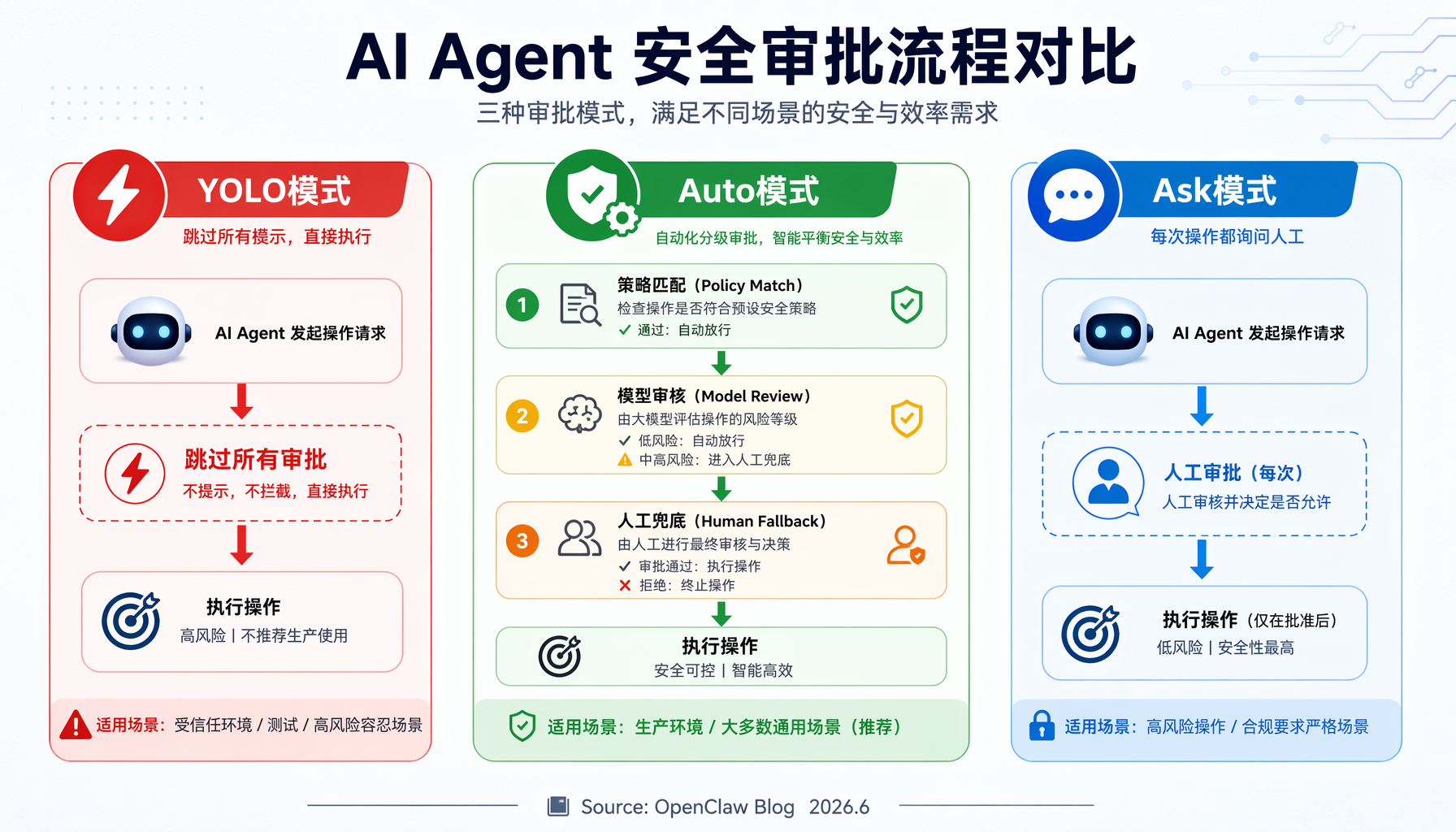
▲ OpenClaw Auto 模式三级安全架构:YOLO / Auto / Ask Human 三种审批模式对比(来源:OpenClaw Blog 2026.6)
为什么重要
对于一人公司和AI创业者来说,这是一个重大利好。
想象一下这个场景:你用 OpenClaw 搭建了一个客户服务 Agent,它能自动查询数据库、生成报告、发送消息。但每当它要执行一条 git pull 或者 docker restart 命令时,你的手机就会弹出审批请求。你正在吃饭、睡觉、或者跟客户开会——Agent 就停在那里等你点"同意"。
这就是 Ask Human 模式的现实困境。而 YOLO 模式虽然省心,但它意味着你的 Agent 可以在你的服务器上为所欲为——不是谁都敢用。
Auto 模式的三级安全架构解决了这个矛盾:
- 第一级:策略匹配。 如果命令在 allowlist(白名单)中或符合安全规则,直接放行——你甚至不会感知到。
- 第二级:模型审核。 命令不在白名单?OpenClaw 构建一个包含命令文本、参数、工作目录、环境变量名等信息的"审核包",发给你指定的审核模型(比如 GPT-5.5)。审核模型判断这是低风险操作,则允许执行一次。
- 第三级:人工兜底。 审核模型不确定、超时、或判断为高风险——回到人工审批。
这个设计的关键亮点:审核模型可以和主 Agent 模型分离。 你可以让 Agent 用本地模型跑日常对话,只在需要审核命令时才调用 GPT-5.5 这样的前沿模型。成本和安全的平衡被精确地控制住了。
除了Auto模式,这个版本还带来了什么
1. Skill Workshop 大升级
OpenClaw 的 Skill Workshop——管理 Agent "技能"的控制台——获得了完整的 UI 重做:提案列表、今日行动、修订交接、文件预览、审核状态等一应俱全。技能现在可以走"提案→审核→实施"的治理流程,而不是随意安装。
这对团队协作尤其重要:产品经理可以提交技能提案,工程师审核通过后 Agent 才能使用。
2. 九大渠道稳定性加强
Telegram、WhatsApp、iMessage、Slack、Discord、Microsoft Teams、Google Chat、Google Meet、iOS 实时语音——九个即时通讯渠道全部加强了消息投递稳定性。对于依赖多渠道触达客户的一人公司来说,消息丢了就等于商机丢了。
3. iMessage 状态持久化
iMessage 的监控状态、消息队列、插件安装记录从文件系统迁移到了 SQLite。这意味着重启或本地监控恢复时,不再需要扫描大量文件,状态恢复更快更可靠。
4. MiniMax M3 模型支持
OpenClaw 现已支持 MiniMax M3 模型。MiniMax 的 M 系列在前沿开源模型榜单上表现强劲,此次集成让 OpenClaw 用户有了更多本地/低成本模型选择。
5. 更稳健的 Agent 恢复
Agent 和 CLI 运行时在被中断的工具调用、过期的会话绑定、压缩交接和媒体投递重试中恢复得更干净。这对长时间运行的自动化工作流至关重要——你不会希望一个网络波动就让整个任务链断掉。
Auto模式的实操指南
如果你已经在用 OpenClaw,启用 Auto 模式只需两行配置:
如果你想指定一个更强的审核模型:
审批请求不再局限在终端里。OpenClaw 可以将审批提示路由到你已经在用的平台:Slack、Telegram、iMessage。你在手机上看到一条消息,点"允许一次"或"拒绝",Agent 继续工作。
安全防护机制
Auto 模式在设计上有多层防护:
- 审核模型只能允许一次低风险执行。不能批量放行,不能记住"永久允许"。
- 命令被绑定到规范的命令计划(canonical command plan),包括 cwd、argv 和会话上下文。如果调用方在审批请求创建后修改了命令,执行会被拒绝。
- 审核模型收到的所有数据都被视为不可信数据。如果命令文本、环境变量名、heredoc、文件名等试图"指示"审核模型做出决策,OpenClaw 会直接交给人类。
- 主机级安全策略不受影响。如果主机配置了"始终询问"或"始终拒绝",Auto 模式不会覆盖。
对一人公司的启示
Auto 模式的真正价值不只是技术安全,而是信任自动化。
一人公司最稀缺的资源不是钱——是注意力。你不可能 24 小时盯着 Agent 的每一个操作。Ask Human 模式意味着你的注意力被 Agent 碎片化;YOLO 模式意味着你把信任完全交给了一个黑盒。
Auto 模式给出了第三条路:策略保证底线安全,模型处理常规判断,人类只介入真正的灰色地带。 这是 AI Agent 从"工具"走向"同事"的关键一步。
与此同时,OpenClaw 官方博客底部预告了两篇即将发布的文章:一篇关于与 NVIDIA 在 Agent 技能安全方面的合作,另一篇关于"OpenClaw 变得更快、更小、更值得信任"。这意味着未来几周还会有更多来自 OpenClaw 的重要更新。

▲ 一人公司自动化运营:9 大渠道 · 三级安全架构 · 1 人掌控全局
行动建议
- 如果你已经在用 OpenClaw:升级到 2026.6.1-beta.1,在非生产环境先试试 Auto 模式。从
tools.exec.mode auto开始,观察审核模型的表现。 - 如果你在用其他 Agent 框架(Hermes Agent、CrewAI 等):关注 OpenClaw 的 Auto 模式设计。这种"策略+模型+人工"的三级安全架构正在成为行业共识(OpenAI Codex 的 Guardian 采用了相同模式),你的框架很可能也会跟进。
- 如果你还没用 Agent 执行系统命令:Auto 模式降低了入门门槛。你可以从配置一个严格的白名单开始,逐渐扩展 Agent 的自主范围。
本文由AI辅助创作,经人工审核编辑发布