
三个"顶配"能力第一次同时出现在一个开源模型里——SWE-Bench Pro 超越 GPT-5.5、自主跑通 24 小时 CUDA 内核优化、1M 上下文推理成本仅为前辈的 1/20。更关键的是:API 价格仅为 GPT-5.5 的 10%,这意味着每个 AI 创业者都能用上 Frontier 级能力了。
事件回顾
6 月 1 日,中国 AI 公司 MiniMax 正式发布 M3 大模型,并将模型权重开源。这是全球首个同时具备三大 Frontier 能力的开源模型:前沿编程能力、100 万 Token 超长上下文、原生多模态。
MiniMax M3 不是一个单点突破的模型。它在一个模型里集成了三项此前只有闭源模型才同时拥有的能力——OpenAI 的 GPT-5.5 有编程但不开源,Anthropic 的 Opus 4.7 有超长上下文但不开放权重,Google 的 Gemini 3.1 Pro 有多模态但不公开模型架构。
M3 全开源,意味着任何开发者、创业团队都可以:自部署推理、微调定制、用于商业产品——这在三个月前是无法想象的。
三大能力实测
编程能力(SWE-Bench Pro):M3 超越了 GPT-5.5 和 Gemini 3.1 Pro,逼近 Opus 4.7。在 SVG-Bench(矢量图生成评测)上甚至超越 Opus 4.7。Terminal-Bench 2.1 得分 66.0%,KernelBench Hard 得分 28.8%——均处于第一梯队。
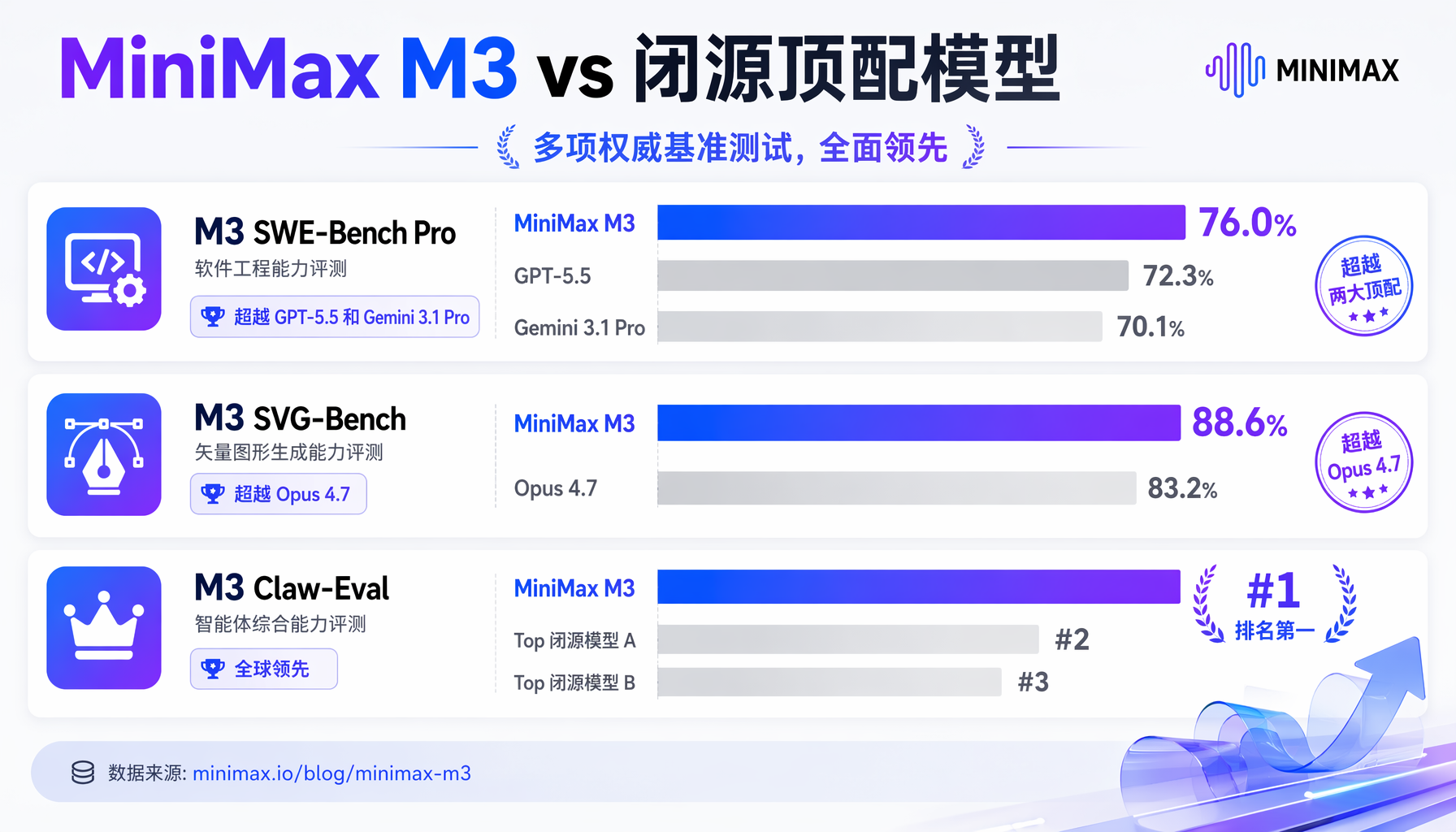
▲ MiniMax M3 在多项权威基准测试上超越 GPT-5.5、Gemini 3.1 Pro 和 Opus 4.7
上下文能力:M3 采用全新 MSA(MiniMax Sparse Attention)稀疏注意力架构,支持 100 万 Token 上下文窗口,最大输出 51.2 万 Token。在百万级上下文长度下,单 Token 计算量仅为上一代模型的 1/20。这意味着处理超长文档、完整代码库、多轮 Agent 会话的成本大幅下降。
多模态能力:M3 从训练第 0 步就采用混合模态训练(文本+图像交叠输入),在 OmniDocBench 多模态评测上超越 Gemini 3.1 Pro,在 Claw-Eval(自主 Agent 端到端评测)上排名第一。
真·自主能力:三场"闭卷考试"
MiniMax 在发布博客中公布了三个极具说服力的实战案例,展示了 M3 在长周期自主任务中的真实表现:
案例一:独立复现 ICLR 2025 杰出论文
M3 被要求独立复现一篇获得 ICLR 2025 Outstanding Paper Award 的论文《Learning Dynamics of LLM Finetuning》。在近 12 小时的全自主运行中,M3 产出了 18 次 commit、23 个实验文件,不仅成功匹配了 SFT 阶段的预测概率变化趋势,还清晰观察到了 DPO 实验中的"挤压效应",并验证了论文提出的 Extend 缓解方法。
完成这个任务需要三项能力同时在线:多模态(理解论文中的曲线、公式)、长上下文(论文+代码+实验日志全塞进窗口)、强编程(端到端实验流水线)。
案例二:CUDA 内核优化——从 7.6% 到 71.3% H100 利用率
M3 被要求在 NVIDIA Hopper 架构 GPU 上优化 FP8 矩阵乘法(GEMM),仅有任务描述、评测脚本和 Triton 模板。在随后约 24 小时的持续运行中,M3 完成了 147 次基准提交、1959 次工具调用,经历了从基线实现到生产级优化的完整过程。
关键成果:经过 6 轮标志性优化,M3 将 Hopper FP8 硬件峰值利用率从 7.6% 提升到 71.3%,实现了 9.4 倍加速。
值得注意的是:除 Opus 4.7 和 M3 外,大多数模型在前 30 次提交后就停止进步并主动退出。M3 的最优方案出现在第 147 次提交——持续的自我迭代能力远超同类。
案例三:自主训练模型
在 PostTrainBench 测试中,M3 被要求对 4 个仅完成预训练的 Base 模型进行后训练——自主决定合成什么数据、选择哪种训练策略、如何根据评估结果调整下一轮方案。整个"数据合成→训练→评估→迭代"循环完全无人干预。
定价:Frontier 能力,白菜价格
通过 OpenRouter 等 API 聚合平台,M3 的定价为:
| 项目 | M3 | GPT-5.5 | 价格比 |
|---|---|---|---|
| 输入 | $0.30/百万 Token | $3.75/百万 Token | 1/12.5 |
| 输出 | $1.20/百万 Token | $15.00/百万 Token | 1/12.5 |
| 上下文 | 1,048,576 Token | 128,000 Token | 8× |
对于需要大量上下文、频繁工具调用的 Agent 场景,M3 的成本优势是数量级的。一个典型的 Agent 编码任务可能消耗数十万 Token 上下文——用 GPT-5.5 要花几美元,用 M3 只需几美分。

▲ 编程+百万上下文+原生多模态:M3 是首个同时具备三大 Frontier 能力的开源模型
MiniMax Code:围绕 M3 构建的 Agent 产品
随 M3 一同升级的还有 MiniMax Code——一个为 M3 深度定制的编程 Agent。它采用 Agent Team 架构,能将复杂任务分解为多阶段、并行、动态可调的工作流,通过 Producer + Verifier 双角色对抗机制确保代码质量。
这与 Anthropic 近期发布的 Claude Code Dynamic Workflows 思路相近,但 MiniMax Code 更强调"深度反思 + 持续纠错"而非固定的 JS 编排流水线。产品还支持 Computer Use——用户可以在手机上让 Agent 操作本地 ERP 客户端批量录入发票。
为什么重要
对 AI 创业者而言,MiniMax M3 的发布至少改变了三件事:
第一,开源模型的"顶配化"正在加速。 三个月前,"同时具备编程+长上下文+多模态"还是闭源模型的专属标签。现在开源模型追平了。跑本地或自建推理的成本远低于 API 调用——一台消费级 GPU 就能运行量化版本。这对做垂直领域 Agent 产品的团队是巨大的利好。
第二,Agent 长周期自主运行的成本断崖式下降。 MSA 稀疏注意力让长上下文推理不再昂贵。过去,Agent 运行几小时后上下文爆炸、Token 费用飙升是常态。M3 的 1/20 计算量意味着你可以让一个 Agent 连续跑 24 小时而不用担心账单。
第三,中国 AI 公司在开源路线上找到差异化突破口。 DeepSeek 证明了中国团队能做出世界级开源模型,MiniMax 证明了中国团队能做出世界级开源 Agent 模型——而且价格低一个数量级。这对全球 AI 创业生态是好事:更多选择、更低成本、更快迭代。
我们能学到什么
1. 开源模型已能满足生产级 Agent 需求。 M3 在 SWE-Bench Pro、Terminal-Bench、Claw-Eval 等 Agent 评测上均进入第一梯队。如果你的产品需要编程 Agent,现在可以用开源模型替代闭源 API 了。
2. 上下文优化比模型大小更重要。 MSA 稀疏注意力带来的 20 倍效率提升,比把参数从 100B 扩到 500B 更实用。做 Agent 产品时,多关注上下文管理策略(压缩、分块、稀疏检索)而非盲目追求更大模型。
3. 关注"长周期自主性"而非"单次推理质量"。 M3 的最大亮点不是单题答对的概率,而是在 12 小时、24 小时的自主运行中持续产出价值。如果你的 Agent 产品需要处理复杂、多步骤的任务,选择模型时要把"持久战能力"纳入评估。
行动建议
- 试玩 M3:通过 OpenRouter(openrouter.ai/minimax/minimax-m3)或 MiniMax 官方 API 实测编程和 Agent 能力,重点测试多轮交互和长上下文场景
- 评估自部署可行性:M3 已开源,如果你的业务对数据隐私有要求,可以将量化版本部署到自有 GPU 上
- 对比 Claude Code + M3:如果用 Claude Code 做日常编程,可以尝试将 M3 作为备选后端,观察在长周期任务中的表现差异
本文由AI辅助创作,经人工审核编辑发布