
IEEE Spectrum 最新专访 NYU 游戏AI实验室主任 Julian Togelius:LLM 在编程上突飞猛进,却在电子游戏面前集体翻车。这背后揭示的,是当前 AI Agent 最致命的短板。
事件回顾
今天凌晨,一篇 IEEE Spectrum 的专访文章《Why Are Large Language Models So Terrible at Video Games?》以 487 points 冲上 Hacker News 热榜第一。文章采访了纽约大学 Game Innovation Lab 主任、AI 游戏测试公司 Modl.ai 联合创始人 Julian Togelius,揭示了一个反直觉的事实:
LLM 能在一句 prompt 内写出一个可玩的游戏,但让它自己去玩这个游戏,表现惨不忍睹。
这不是某个模型的问题。Togelius 的原话是:"They fail. They absolutely suck. All of them. They don't even do as well as a simple search algorithm."(它们全失败了。烂透了。无一例外。连一个简单的搜索算法都不如。)
唯一算得上"成功"的案例是 Gemini 2.5 Pro 在 2025 年 5 月通关了 Pokemon Blue——但它的通关速度远慢于人类玩家,过程中做出大量荒谬且重复的错误决策,还需要定制化工具辅助。
核心矛盾:会造游戏 ≠ 会玩游戏
Togelius 在采访中提出了一个精准的类比:
编程就像一个"行为良好的游戏"。 任务就是关卡,需求文档是规则,编译器和测试套件提供即时反馈。代码要么能编译、要么不能;测试要么通过、要么失败。整个流程有清晰的成功/失败信号。
而真正的电子游戏完全不同:
- 输入空间极大:每个时间步都有几十种可能的操作组合
- 反馈延迟且模糊:你按了一个键,可能要 30 秒后才知道这个决策是对是错
- 空间推理是刚需:你需要理解屏幕上的物体位置关系、预判运动轨迹
- 没有"编译错误":游戏不会告诉你"这个跳跃早了 0.3 秒"
更关键的是:游戏之间的差异远比现实世界大。 Togelius 指出,现实世界有统一的物理定律,自动驾驶在任何地方面对的都是相似的道路场景。但 Halo 和 Space Invaders 之间的差距,远大于北京早高峰和纽约高速之间的差距。

▲ 封闭世界 vs 开放世界:AI Agent 的能力边界对比
为什么 AlphaZero 能做到而 LLM 不能?
很多人会问:DeepMind 的 AlphaZero 不是早在 2017 年就能下围棋和象棋了吗?
Togelius 的回答直击要害:AlphaZero 不是通用游戏 AI。 它下围棋和象棋用的是完全不同的训练过程,需要针对每个游戏重新训练和重新工程化。而且围棋和象棋的输入/输出空间非常相似——都是棋盘、都是离散落子。
真正的通用游戏 AI 需要对一个完全没见过的新游戏——比如那种独立开发者在 Game Jam 里 48 小时做出来的怪游戏——也能上手就玩。这在今天还做不到。
Togelius 自己组织的 General Video Game AI 竞赛运行了 7 年,每一届都发明 10 个新游戏来测试。结果呢?"我们停止了这个竞赛,因为我们看不到什么进展。智能体在某些游戏上变好了,但在另一些游戏上却变差了。"
这对 AI 创业者有什么启示?
1. 今天的 AI Agent 本质上是"封闭世界智能"
LLM 在编程上能"碾压"人类,是因为编程是一个定义良好、反馈明确的封闭世界。代码要么编译要么不编译,测试要么通过要么不通过。
但大多数现实商业场景——客户沟通、市场分析、产品决策——更像是电子游戏:反馈延迟、信号模糊、需要多步推理。
启示:如果你在做一个 AI Agent 产品,优先选择那些"像编程一样行为良好"的场景——有明确输入输出、有可验证的正确性标准、反馈循环短的领域。比如代码审查、文档生成、数据清洗,而不是全自动客户服务或自主商业决策。
2. "空间推理"是下一代 Agent 的瓶颈
Togelius 明确指出,LLM 在游戏上失败的核心原因是缺乏空间推理能力——因为训练数据里根本没有三维空间的位置关系。
这一点已经被很多 AI Agent 实战验证:让 Claude Code 或 Cursor 写一个前端页面没问题,但让它判断"这个按钮在手机上会不会被遮挡"就完全抓瞎。
启示:如果你在做需要视觉/空间理解的产品(如 UI 自动化测试、AR 应用、机器人控制),仅靠纯文本 LLM 是不够的。需要考虑多模态模型 + 专门的空间推理模块。
3. 游戏是测试 Agent 智能的终极沙盒
Togelius 的观点反过来看也有积极的一面:正因为游戏如此多样化且难以驾驭,它们才是最好的 AI 测试场。 如果一个 Agent 能在没有专门训练的情况下上手一个随机的新游戏,那它在现实世界中的泛化能力也不会差。
这就是为什么 OpenAI、DeepMind 等顶级实验室一直在游戏环境中训练 AI——不是为了让 AI 打游戏,而是因为游戏提供了无限多样、可量化评估的训练环境。
4. LLM 的"超级程序员 + 零游戏玩家"组合正在催生新机会
一个有趣的数据点:Togelius 提到,LLM 写出的游戏质量直接受限于它能不能"玩"这个游戏。因为它没法测试自己写的代码、感受操作手感、调整难度曲线。
这意味着:在 AI 辅助游戏开发工具这个细分赛道,单纯的代码生成远远不够。 需要配套的自动化测试、模拟玩家行为、难度评估等工具。Modl.ai(Togelius 自己的公司)正是在做 AI 驱动的游戏测试——替开发者发现 LLM 生成的代码中的 bug 和体验问题。
启示:AI 工具链中的"质量保证"环节被严重低估。当所有人都在做 AI 代码生成时,AI 代码的测试、验证、体验评估才是真正的蓝海。
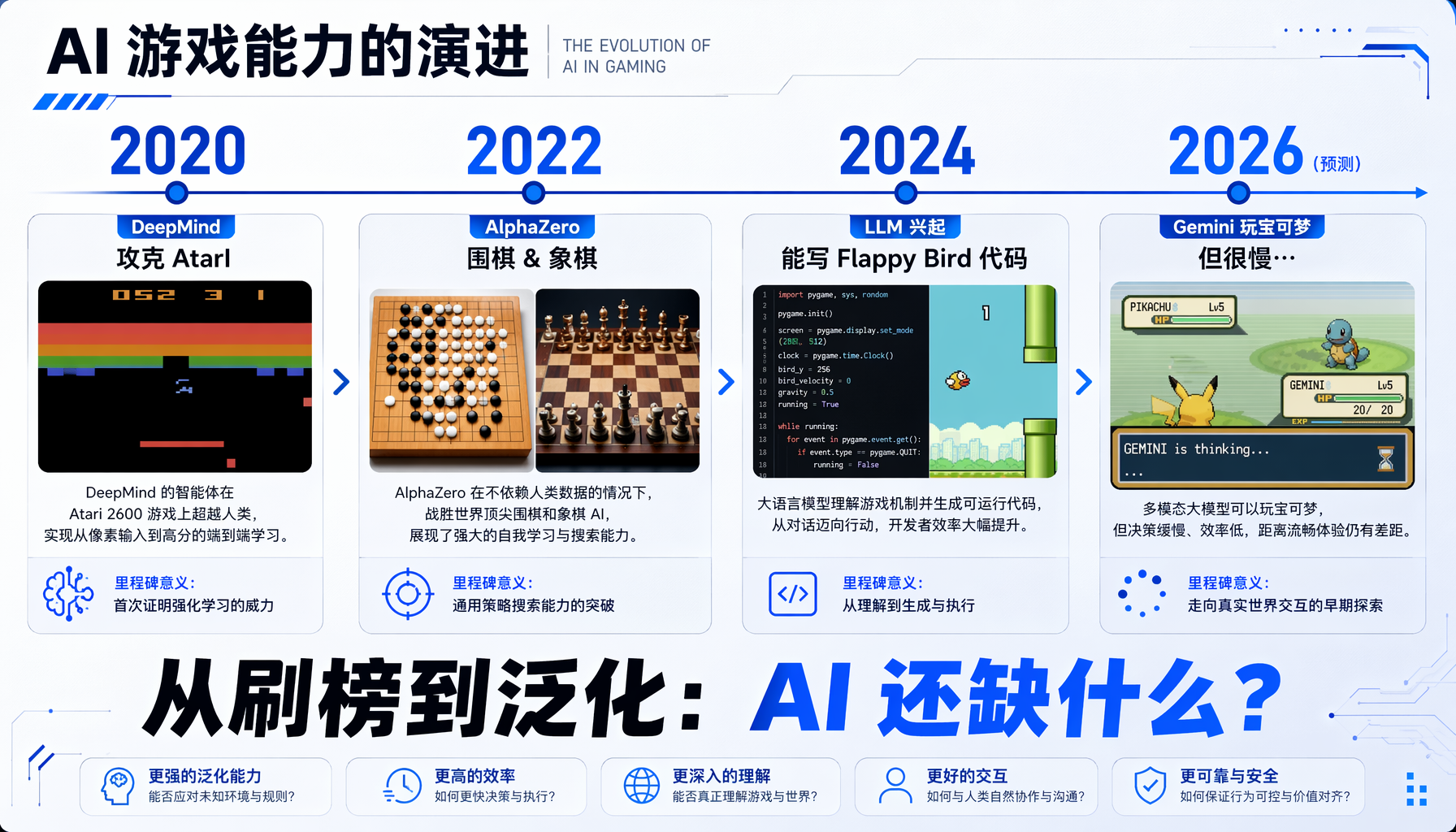
▲ 从刷榜到泛化:AI 游戏能力的演进与缺失
行动建议
- 重新审视你的 Agent 产品边界:你的 AI 是在"封闭世界"还是"开放世界"里运行?如果反馈信号不清晰、需要空间推理或长期规划,做好心理准备——当前 LLM 架构存在硬天花板。
- 关注多模态 + 空间推理组合:如果你的产品涉及 UI 操作、图像理解、物理世界交互,开始研究 VLM(视觉语言模型)和 world model 方向的最新进展。
- 在"AI 质量保证"赛道寻找机会:游戏测试是 AI 无法自举的典型案例。延伸到其他领域——AI 写的代码谁来测试?AI 生成的内容谁来审核?AI 做的决策谁来验证?这个需求只会越来越大。
- 用游戏思维设计 Agent 评估体系:如果你的 Agent 需要处理多种不同类型的任务,参考 GVGAI 竞赛的做法——不断发明新任务来测试,而不是在固定 benchmark 上刷分。
参考资料
- IEEE Spectrum 原文:Why Are Large Language Models So Terrible at Video Games?(Matthew S. Smith 专访 Julian Togelius,2026年6月1日)
- Julian Togelius:NYU Game Innovation Lab 主任,Modl.ai 联合创始人
- GVGAI(General Video Game AI Competition):
- HN 讨论:487 points,Hacker News 热榜 #1(2026年6月1日)
本文由AI辅助创作,经人工审核编辑发布