
Hermes Agent 发布了史上最大版本更新 v0.15.0,1302 commits、747 PRs,核心文件
run_agent.py从 16,083 行精简到 3,821 行(-76%),Kanban 升级为真正的多Agent平台。本文带你实操三条最有价值的更新:Swarm 拓扑编排、Skill Bundles 工作流打包、session_search 4500× 加速。
前言
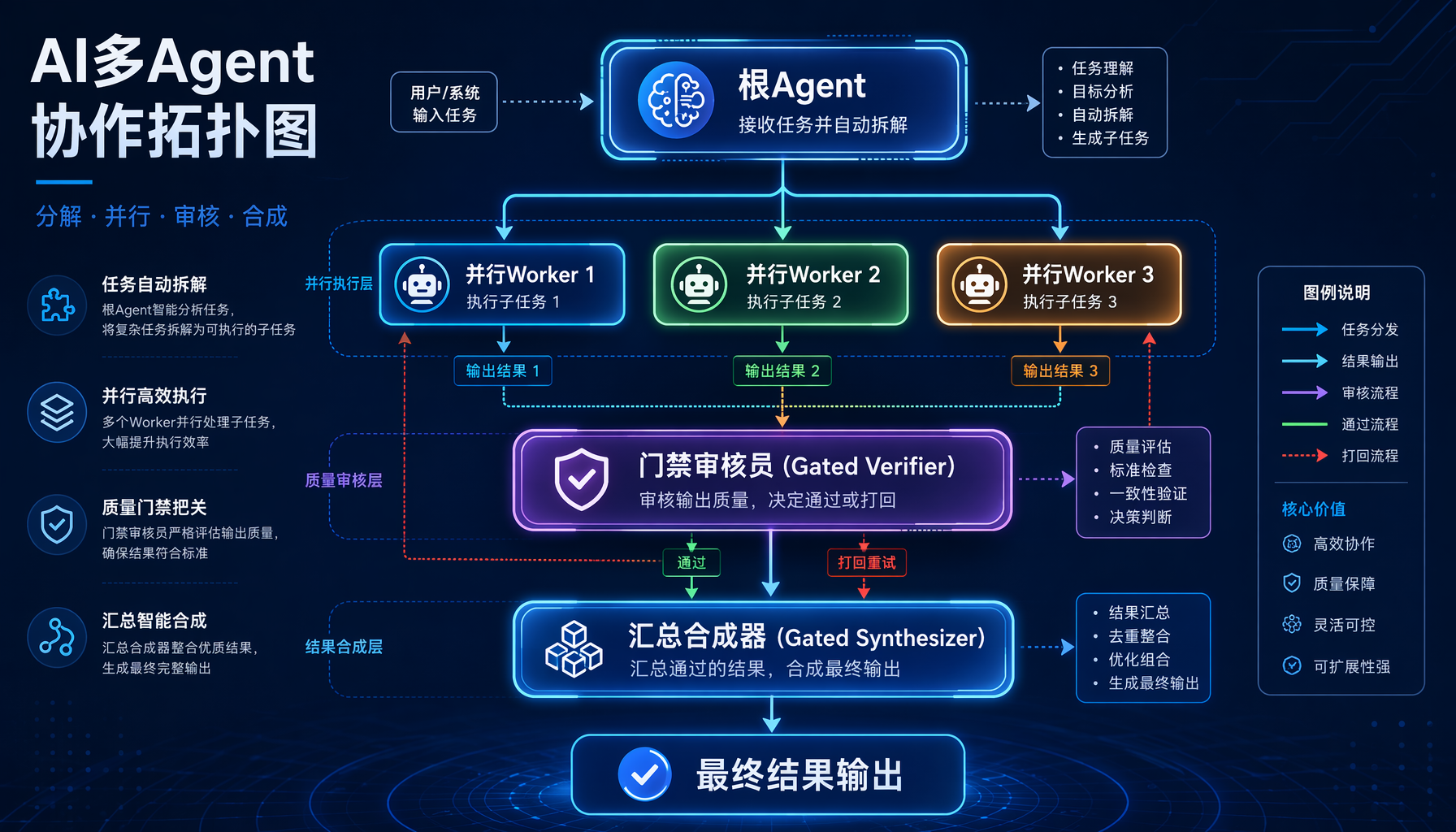
▲ 图1:Hermes Kanban Swarm 多Agent协作拓扑结构
2026年5月28日,Hermes Agent 发布了 v0.15.0 "The Velocity Release"——这是项目历史上最大的一次版本更新。1302 个 commits、747 个合并 PR、560+ issues 关闭,321 位社区贡献者参与。但数字只是表象,真正值得AI创业者关注的是:Hermes 从一个单Agent工具变成了一个真正的多Agent编排平台。
如果你正在用 AI Agent 做自动化——无论是内容生产、代码开发还是客户运营——v0.15.0 的三个核心更新会直接改变你的工作方式:
- Kanban Swarm:一条命令生成完整的多Agent协作拓扑(root → 并行 worker → 门禁审核员 → 汇总器)
- Skill Bundles:用一个斜杠命令加载整套工作流(比如
/writing-day一键激活 humanizer + ideation + obsidian + youtube-content) - session_search 4500× 加速:从 90 秒降到 20 毫秒,彻底免费
本文将逐一拆解这三个功能的原理、配置方法和实战案例。读完你可以在 15 分钟内搭建自己的多Agent工作流。
背景:为什么 v0.15.0 是一个分水岭
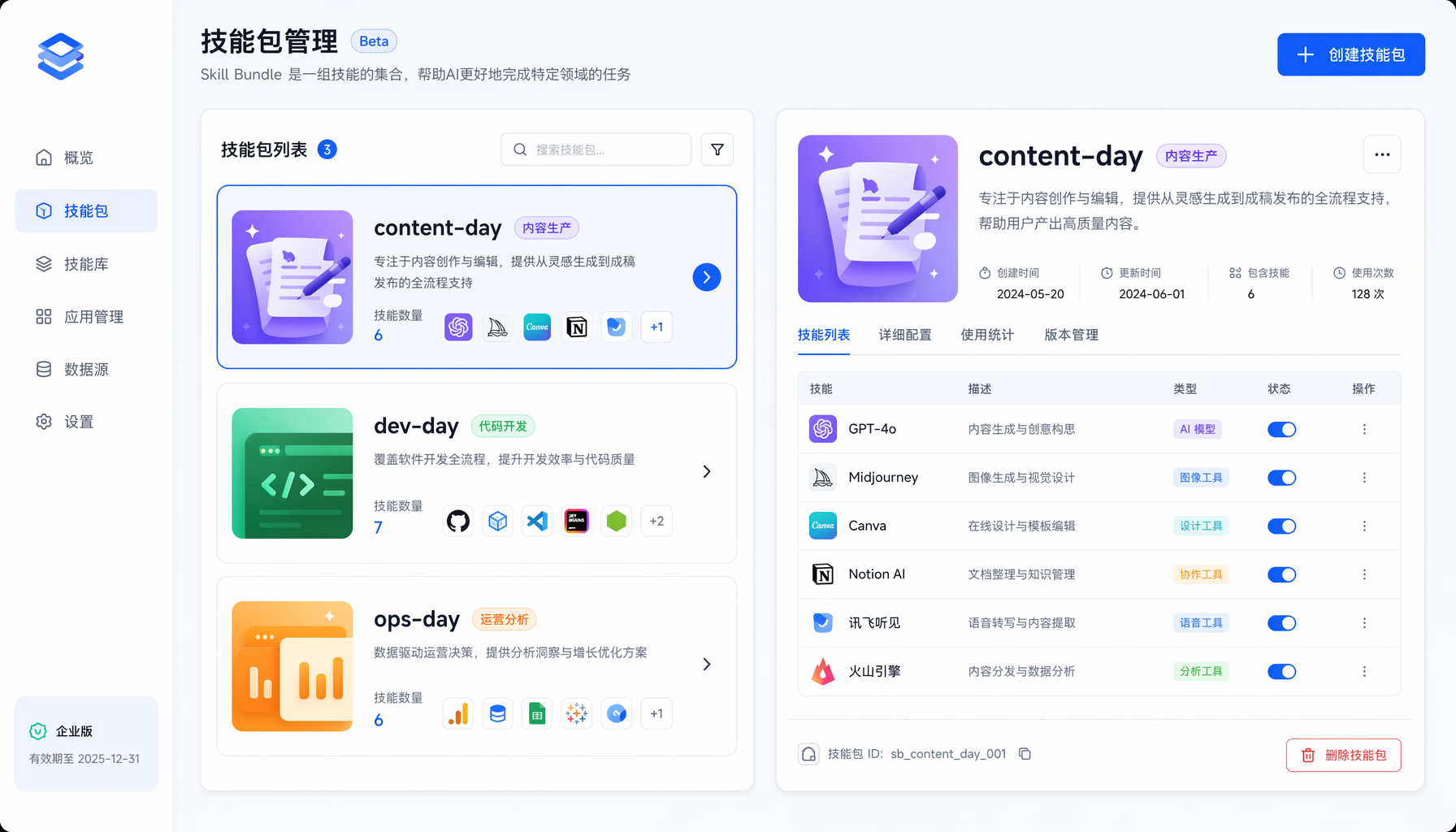
▲ 图2:Skill Bundles 技能包管理界面
在 v0.14.0 时代,Hermes 的核心还是一个单Agent循环——一个模型、一个对话、串行执行任务。你可以通过 /delegate 把子任务分派出去,但本质上那是"一个Agent找另一个Agent帮忙",不是真正的多Agent协作。
v0.15.0 改变了这个范式。Kanban 看板从任务管理工具升级为多Agent编排引擎——你现在可以定义 Agent 之间的拓扑关系(谁在前、谁在后、谁审核谁、谁汇总谁),让多个Agent像工厂流水线一样协作。
而且这个升级不是"加了一堆配置项让你自己摸索"。hermes kanban swarm 一条命令,自动生成一个 Swarm v1 图:root → 并行 workers → gated verifier(带门禁的审核员)→ gated synthesizer(带门禁的汇总器)→ shared blackboard(共享黑板)。这是 Nous Research 团队把多Agent架构的最佳实践内置进了工具。
核心实战一:Kanban Swarm — 多Agent协作流水线

▲ 图3:Hermes v0.14.0 vs v0.15.0 关键性能指标对比
Swarm 是什么?
Swarm 是 Hermes v0.15.0 新增的多Agent拓扑模式。它的结构是这样的:
创建你的第一个 Swarm
在终端执行一条命令:
这条命令会自动创建:
- 1 个 Root Agent(负责接收需求并自动拆解为子任务)
- 3 个并行 Worker(各自认领子任务执行)
- 1 个 Gated Verifier(检查输出质量,不合格就退回重做)
- 1 个 Gated Synthesizer(汇总所有 worker 输出,消除矛盾,合成终稿)
- 1 个 Shared Blackboard(所有 Agent 都能读写的共享上下文)
给每个 Worker 分配不同的模型
Swarm 的一个关键能力是 per-task model override——你可以给不同的子任务分配不同成本和能力的模型:
这个策略对AI创业者来说非常实用:贵的模型做核心创作,便宜的模型做辅助工作。 DeepSeek V4 Pro 写文章(复杂推理),V4 Flash 检查格式(简单任务),成本可以降低 60-70%。
查看 Worker 运行状态
Swarm 提供了三个监控端点:
你也可以直接在 TUI 里通过 /workers 斜杠命令查看。
Swarm 的可靠性设计
Hermes 团队在 104 个 Kanban PR 中埋了大量可靠性机制,这里是最关键的几个:
- Respawn Guard:防止 worker 崩溃后无限重启(风暴保护)。如果同一个 worker 在短时间内连续崩溃,系统会自动暂停它并通知你。
- Retry Fingerprinting:对崩溃错误做指纹识别,同一个错误不会触发全集群重试——避免"一个 worker 的 bug 拖垮整个 swarm"。
- Stale Task Detection:自动检测卡死的任务,超时后重新分配。
- Cycle Detection:在任务拆解时预检依赖循环,防止 A→B→C→A 的死锁。
核心实战二:Skill Bundles — 一键加载整个工作流
痛点:Skill 多了怎么管?
当你的 Agent 配置了 10+ 个 Skills 后,每次开始一个新会话,你都要手动告诉 Agent:"加载 writing skill、加载 research skill、加载排版 skill..."。而且不同场景需要不同的 skill 组合——写文章需要 humanizer + ideation + obsidian,写代码需要 code-review + testing + docs。
Skill Bundles 就是解决这个问题的:把一个工作流所需的所有 skills 打包成一个命名组,一个斜杠命令全部激活。
创建你的第一个 Bundle
在 ~/.hermes/bundles/ 目录下创建一个 YAML 文件:
然后在 Hermes 对话中:
这一个命令会同时加载全部 5 个 skill,Agent 立刻进入"写作日模式"。
实战:一人公司三件套 Bundle
我给自己建了三个 Bundle,覆盖日常 90% 的工作场景:
Bundle 1:内容生产 (/content-day)
Bundle 2:代码开发 (/dev-day)
Bundle 3:运营分析 (/ops-day)
Skills Hub 健康监控
v0.15.0 还升级了 Skills Hub——现在每个 skill 都有健康检查和新鲜度徽章,还有一个 watchdog cron 自动检测 skill 是否过时:
对于依赖第三方 API 的 skill(比如搜索插件、支付接口),这个健康检查特别重要——你不会想在发布文章时才发现某个 API key 过期了。
核心实战三:session_search — 从 90 秒到 20 毫秒
旧版 session_search 的问题
在 v0.14.0 及之前,session_search 是一个"辅助 LLM"驱动的工具——它启动一个小模型来阅读和总结你的历史会话。这带来三个问题:
- 慢:搜索 3 个历史会话需要约 90 秒
- 贵:每次调用约 $0.30
- 不可靠:小模型有时会"脑补"信息,把不在候选列表里的会话内容编造出来
新版:零 LLM、零成本、20 毫秒
v0.15.0 完全重写了 session_search,核心变化:
新 session_search 有三种模式,通过你传的参数自动推断(不需要手动指定 mode):
| 模式 | 触发条件 | 速度 | 用途 |
|---|---|---|---|
| Discovery | 传 query 参数 | ~20ms | 搜索关键词,返回匹配的会话列表 |
| Scroll | 传 session_id + offset | ~1ms | 在某个会话里翻页浏览 |
| Browse | 传 session_id 不传 offset | ~1ms | 打开某个会话查看全部内容 |
实战效果对比:
对于每天要和 Agent 对话几十轮的AI创业者来说,这个改进意味着你可以随时回溯任何历史讨论,不需要担心成本和等待时间。
其他值得关注的更新
Bitwarden Secrets Manager 集成
API Key 管理一直是一人公司运营的痛点——.env 文件里堆了十几个 API key,换一台机器要手动同步,key 泄露了不知道。
v0.15.0 集成了 Bitwarden Secrets Manager:你只需要一个 BWS_ACCESS_TOKEN,所有其他 key 都从 Bitwarden 拉取。在 Bitwarden 网页端改一个 key,所有机器的 Hermes 下次启动自动生效。
Promptware 防御
v0.15.0 引入了针对 Brainworm 类攻击的三级防御:
- 工具输出保护:所有工具的输出结果会被包上分隔标记,恶意文件或远程服务返回的内容无法伪装成 Hermes 的系统指令
- 记忆加载时扫描:从
MEMORY.md加载记忆时,自动扫描是否包含已知的注入模式(~15 种 Brainworm/C2 模式) - 安全指引插件:
security-guidance插件用模式匹配检测危险的代码写入行为
对于使用 Agent 做自动化运营的创业者来说,这个更新意味着你不用担心一个恶意网页的内容通过搜索工具注入到你的 Agent 里。
性能提升汇总
| 指标 | v0.14.0 | v0.15.0 | 提升 |
|---|---|---|---|
run_agent.py 行数 | 16,083 | 3,821 | -76% |
| 31轮对话函数调用 | 399,000 | 213,000 | -47% |
| CLI 冷启动(Termux) | 2.9s | 0.8s | -72% |
hermes --version | 701ms | 258ms | -63% |
| session_search | 90s | 20ms | -99.98% |
| session_search 成本 | $0.30/次 | $0.00 | -100% |
总结与行动建议
Hermes v0.15.0 是一次质变——从单Agent工具升级为多Agent平台。对于AI创业者,我建议按以下优先级行动:
今天就可以做的(15分钟):
- 升级到 v0.15.0:
hermes update - 创建一个 Skill Bundle:把你最常用的 3-5 个 skill 打包
- 体验新版 session_search:搜一下"上周的某个讨论",感受 20ms 的速度
本周可以做的(1小时):
- 用
hermes kanban swarm创建一个 3-worker 的简单流水线 - 给不同 worker 分配不同模型,对比成本差异
- 配置 Bitwarden Secrets Manager,告别
.env里的明文 key
本月可以探索的:
- 搭建内容生产 Swarm:选题调研(DeepSeek V4 Pro)→ 写作(DeepSeek V4 Pro)→ 审核(DeepSeek V4 Pro)→ 排版检查(DeepSeek V4 Flash)
- 把 Swarm 接入 cron 定时任务,实现真正的"无人值守"内容工厂
- Hermes Agent v0.15.0 Release Notes(GitHub: NousResearch/hermes-agent/releases/tag/v2026.5.28)
- Kanban Swarm PR #28443(GitHub: NousResearch/hermes-agent/pull/28443)
- Skill Bundles PR #28373(GitHub: NousResearch/hermes-agent/pull/28373)
- session_search Rewrite PR #27590(GitHub: NousResearch/hermes-agent/pull/27590)
本文由AI辅助创作,经人工审核编辑发布