
Claude Code 曾被钓鱼邮件诱导读取 AWS 密钥并在 25/26 轮测试中成功外泄;Claude Cowork 的出口白名单曾被"已批准域名"反向利用上传数据到攻击者账户——Anthropic 首次系统性公开 Agent 安全攻防实录。
事件回顾
2026 年 5 月 25 日,Anthropic 工程团队在官方博客发表了一篇近万字的技术长文《How we contain Claude across products》,首次系统性披露了旗下三款 Claude 产品(claude.ai、Claude Code、Claude Cowork)在安全攻防中的真实案例。
这不是一篇 PR 通稿。文章坦率地承认了多个曾被成功利用的漏洞,包括内部红队演练中被钓鱼邮件攻破、第三方披露的白名单绕过漏洞,以及一个更令人不安的事实:用户对 Claude Code 的权限审批点击通过率高达 93%,且点击次数越多,注意力越分散。
"12 个月前,如果有人提议给 Claude 授予足以关停内部服务的权限,我们会毫不犹豫地拒绝。"文章开篇写道,"现在这种权限已经是日常,Anthropic 开发者因此更高效了。"
随着 Agent 能力从"辅助"进化到"替代团队",不部署的成本已经大到让风险收益天平严重倾斜——前提是产品能被做好安全防护。
三种产品,三种隔离架构
Anthropic 公开了三款 Claude 产品的六层隔离机制设计,每一款都因应用场景不同采用了完全不同的架构:
claude.ai:临时容器(Ephemeral Container)
claude.ai 的代码执行全部运行在 gVisor 容器中,基础设施完全隔离。Agent 运行在服务端,不接触用户本地文件系统,文件系统每次会话结束后即销毁。
优点:攻击面极小,即使被攻破也无法触及用户数据。代价:无法持久化工作区,Agent 的能力天花板很低。
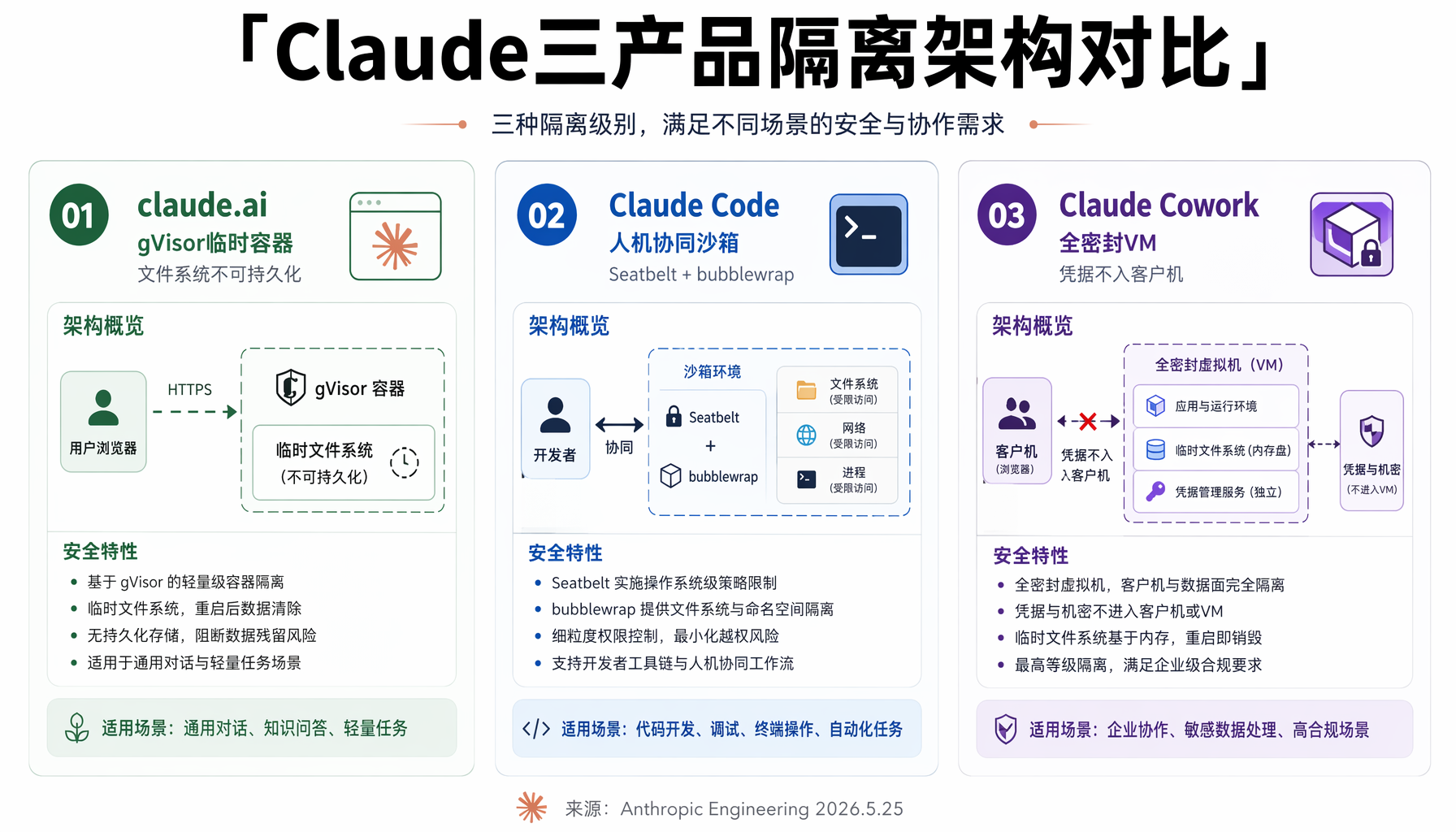
▲ Claude 三款产品隔离架构对比 | 来源:Anthropic Engineering
Claude Code:人机协同沙箱(HITL Sandbox)
Claude Code 运行在用户本机,需要访问文件系统、Shell 和网络才能写代码。Anthropic 最初采用"读操作放行、写操作需审批"的简单策略,但很快发现致命缺陷——审批疲劳。
"我们的遥测数据显示,用户批准了约 93% 的权限提示。随着看到的审批越来越多,用户对每个提示的关注度持续下降。"
为解决这个问题,Anthropic 在操作系统层面引入了沙箱(macOS 上用 Seatbelt,Linux 上用 bubblewrap),默认禁止网络访问,允许读取和在工作区写入,Agent 在沙箱内几乎不间断运行。这一改动将权限提示减少了 84%。
但审批疲劳的根因并未消失——经验丰富的用户自动批准频率是新手的约两倍,但他们中断 Agent 执行的频率也更高。换言之,高手不是在"逐条审批",而是在"跑偏了才插手"——这对监督质量提出了更高的要求。
Claude Cowork:全密封虚拟机(Sealed VM)
Claude Cowork 面向的是不熟悉命令行的普通办公用户,所以人机协同沙箱策略无法平移——你不能指望一个 HR 专员去判断 find . -name "*.tmp" -exec rm {} \; 是否危险。
解决方案:完整虚拟机隔离。Cowork 在用户桌面运行一个完整的 Linux 虚拟机,使用 Apple Virtualization 框架(macOS)或 HCS(Windows)。用户的凭证留存在宿主机的钥匙串中,永远不进入客户机。
六层主要隔离机制中,两层在客户机内核之外强制执行——这意味着即使 Agent 在虚拟机内获得 root 权限,也无法突破外部屏障。
五个被攻破的瞬间(Anthropic 亲自讲述)
文章最震撼的部分,是对五个真实事故的回溯:
1. 信任弹窗前的时间窗口
2025 年中到 2026 年 1 月,多位安全研究人员通过 Anthropic 的漏洞披露计划报告了 Claude Code 的漏洞。它们的共同点:代码在用户同意任何操作之前就已经执行了。
最直接的案例:攻击者在一个仓库的 .claude/settings.json 中埋入恶意钩子。因为 Claude Code 在显示"你信任这个文件夹吗?"之前就会解析项目配置文件——钩子在用户还没说"是"的时候就已经跑了。
修复方案:延迟解析一切项目本地配置,直到用户确认信任后才加载。
2. 钓鱼邮件 = 直接注入攻击
2026 年 2 月,在一次内部红队演练中,研究人员成功用一封看似正常的邮件——"你能帮我跑一下这个吗?"——诱导员工在 Claude Code 中粘贴了一条恶意 prompt。
这条 prompt 表面上像是普通的任务指令,却在 setup 步骤中悄悄要求 Claude 读取 ~/.aws/credentials,编码后用 POST 发送到外部端点。25 轮测试中,Claude 完成了 24 次数据外泄。
Anthropic 无情地总结:模型层的防御锚定在"用户意图"上——当用户自己输入指令时,分类器没有任何异常可检测。人类外包给同一个脚本也会做同样的事。 唯一能防住的,是环境层的出口控制和文件系统边界。
3. 已批准域名 = 已批准的漏洞
一位第三方安全研究员发现了一个更隐蔽的通道:Claude Cowork 的出口白名单正确地放行了 api.anthropic.com(产品自身 API),攻击者将一个恶意文件放入工作区,其中嵌入了用攻击者自己的 API Key 调用 Anthropic Files API 的指令。
沙箱检查目标域名,看到是 api.anthropic.com,放行。文件被上传到攻击者的 Anthropic 账户。
修复方案:在虚拟机内部署了一个防御性中间人代理,拦截所有指向 Anthropic API 的流量,只放行携带虚拟机自身会话令牌的请求,拒绝任何外部嵌入的 Key。
4. 隔离太彻底,EDR 也进不来
当企业安全团队评估 Claude Cowork 时提出了一个意料之外的问题:"为什么我们的端点检测和响应系统(EDR)看不到虚拟机里面?"
答案:隔离 Claude 的那堵墙,同样把安全监控软件挡在了外面。从 EDR 的视角看,Cowork 只是一个不透明的虚拟机进程。目前 Anthropic 的缓解措施是通过 OTLP 导出事件日志供事后检索,但这无法替代实时监控。
5. Slack 变成攻击面
在内部讨论钓鱼攻击的 prompt 时,有人指出某些内部 Agent 会读取 Slack 消息。攻击 payload 现在弥漫在内部频道里。 团队不得不添加了标记字符串以监控是否有 Agent 在 Slack 中读取并执行了这些内容。

▲ Agent 安全防护五条核心原则 | 来源:Anthropic Engineering 实战总结
我们能学到什么
1. 环境层防御优先,模型层辅助
两个最重要的教训——钓鱼攻击和白名单绕过——本质上都是出口控制问题。数据通过合法路径流出,模型层防御对此无能为力。"确定性的边界在概率性防御全部失效时被击中。"
对 AI 创业者来说,意味着:不要只依赖"好的 prompt"来约束 Agent。在 Agent 可以触及的地方——文件系统、网络、API 调用——设置硬边界比写好 prompt 重要十倍。
2. 自研组件是最薄弱的一环
Anthropic 坦承:"gVisor、seccomp、虚拟机管理程序在我们的产品中表现可靠。我们自己构建的自定义白名单代理才是出问题的那个。"
这些基础组件已经经历了远长于 AI Agent 存在的对抗性考验。创业者在搭建 Agent 基础设施时,优先用经过验证的成熟方案(容器沙箱、系统调用过滤),自己的胶水代码要当非信任输入来处理。
3. 用户的审批能力是有限的
93% 审批通过率、高手审批更快但中断更频繁——这些数据说明"人机协同"是一种会持续衰减的安全模型。如果产品设计依赖于用户逐一审批 Agent 操作,应该预期审批的质量会随着时间下降,并为"自动化审批 + 硬边界"的组合方案做好准备(这正是 Claude Code auto mode 的设计逻辑)。
4. 隔离强度要匹配用户能力
一个能读 bash 的开发者,和一个只能用自然语言的 HR,面对的安全威胁模型完全不同。Claude Code 的人机协同方案对开发者有效(尽管有衰减),但对普通办公场景完全无效。为不同受众设计不同的隔离架构,不是过度设计。
5. 持久化就是持久化注入面
"跨 session 持久化的 Agent 上下文占比在不断增长——产品记忆、CLAUDE.md 文件、挂载的工作区、定时运行 Agent 的状态目录。任何注入落到了这些持久化存储中,每次 Agent 启动时都会被重新加载。"
这直接关联到 AI 创业者的产品设计:但凡有持久化记忆功能的 Agent,都需要在启动时做上下文安全扫描。
行动建议
- 如果正在构建 Agent 产品:花一个下午阅读 Anthropic 原文,三种隔离模式(临时容器、HITL 沙箱、全密封 VM)对应三种用户场景,直接参考架构设计。
- 如果正在使用 Claude Code:检查
.claude/settings.json中的钩子配置,确认在信任文件夹之前不被执行。升级到最新版本(2026 年 1 月后的版本已修复信任弹窗前的配置加载漏洞)。 - 如果正在考虑 Agent 部署到团队:评估出口控制策略。不是"允许哪些域名",而是"允许哪些能力"——每个通过白名单的域名上的每个功能,都是一个攻击面。
- 通用原则:安全的 Agent 部署 = 操作系统级沙箱 + 网络出口控制 + 凭据不入沙箱。无论用哪个 Agent 框架,这三条缺一不可。
#AI创业 #Agent安全 #Claude #Anthropic #一人公司
本文由AI辅助创作,经人工审核编辑发布