
Project Headroom 在 GitHub 开源仅5个月,已为全球用户节省2000亿Token、70万美元——而它的核心哲学出奇简单:你喂给大模型的东西,90%是它根本不需要的。
事件回顾
Netflix 高级工程师 Tejas Chopra 上个月收到了一张让他血压飙升的 Claude Sonnet 账单:287美元。
不是什么企业级工作负载。就是一个普通的家庭项目——写写代码、调调bug、用 MCP 工具查查数据库。按 Claude 的定价($3/百万输入 Token),这账单意味着他不知不觉往上下文窗口里灌了将近 1 亿个 Token。
Chopra 翻看了自己的对话记录后发现了一个惊人的事实:绝大部分传给模型的东西,根本不需要。JSON schema 里冗余的嵌套结构、API 响应里的机器元数据、日志里99%都是重复信息。"这不是散文,不是创意写作,"他在博客里写道,"这是可压缩的数据在伪装成文字。"
于是他写了一个工具——Project Headroom。今年1月在 GitHub 开源,5个月后已经收获 2000+ Star、120+ Fork,在刚刚结束的 Open Source Summit 上做了专场分享。
更震撼的是成果数据:Headroom 目前已为用户节省了约 70 万美元的 API 费用,释放了超过 2000 亿个 Token 用于更有价值的任务。
90%的Token是浪费——这不是直觉,是数据
Chopra 的发现背后有扎实的研究支撑。
一组研究者在 2025 年发表论文指出:读取用户输入占到了 76% 的 Token 消耗。另一组来自斯坦福大学的研究表明:LLM 对上下文窗口的注意力分布极不均匀——开头和结尾被重点关注,中间的"夹心层"几乎被忽略。
更致命的发现来自数据集成公司 Chroma:在 18 个主流 LLM 上的测试表明,输入越长,模型表现越不可靠。他们为这个现象创造了一个术语——"上下文腐蚀"(Context Rot)。
换句话说:你多塞进去的那些 Token,不仅烧钱,还可能让模型变得更蠢。
Headroom 就是为这个悖论设计的

▲ Project Headroom:智能压缩上下文,释放预算空间
。Headroom 是怎么做到的?
Headroom 不是简单的文本压缩工具。它是一套分阶段、可逆的 Token 优化流水线,运行在工程师本地(端口 8787),用一行命令即可接入:
包装后的 Codex(或任何 LLM CLI 工具)发出的所有请求都会经过 Headroom 的智能处理。
第一关:CacheAligner(缓存对齐器)
这是 Headroom 最巧妙的设计。传统的 KV Cache(模型服务商用来缓存上下文窗口的机制)有一个致命缺陷:哪怕你只改了系统 prompt 里的一个日期字段,整个缓存就会失效,全部 Token 重新计费。CacheAligner 精确追踪"哪些内容变了",只发送增量部分,大幅提升缓存命中率。
Chopra 在演讲中特别强调:"如果你的系统 prompt 里有一个每次会话都会变化的 UUID,你每次都在触发缓存未命中——这会让你的成本暴增。"
第二关:智能路由 + 专用压缩器
Headroom 会推断输入的"类型",然后分发给针对性的压缩器:
- AST 压缩器:处理代码,去除注释和格式化空格但不破坏语义
- JSON 压缩器:剪掉 MCP 工具输出中 70% 的冗余 JSON 结构
- DOM 压缩器:清理网页抓取内容中的 HTML 样板
- 统计 Squasher:分析文本和 JSON 输入,基于统计特征判断哪些部分与当前任务真正相关
Chopra 给出的实测数据:
- 服务器日志:90% 可被丢弃
- MCP 工具输出:70% 冗余
- 数据库输出:同一 schema 反复出现,只需传一次
- 文件树:大量重复的元数据
第三关:CCR(压缩-缓存-检索)——可逆压缩
这是 Headroom 区别于所有其他 Token 压缩工具的核心功能。
普通的压缩工具一旦砍掉内容就无法恢复。但 Headroom 在压缩后的 prompt 中嵌入"标记",当 LLM 需要查看被压缩掉的原始数据时,可以通过 Headroom 提供的 MCP 工具,从本地 Redis 或 SQLite 存储中检索完整内容。
这意味着:压缩是无损且可逆的。模型不会因为压缩而丢失任何信息。
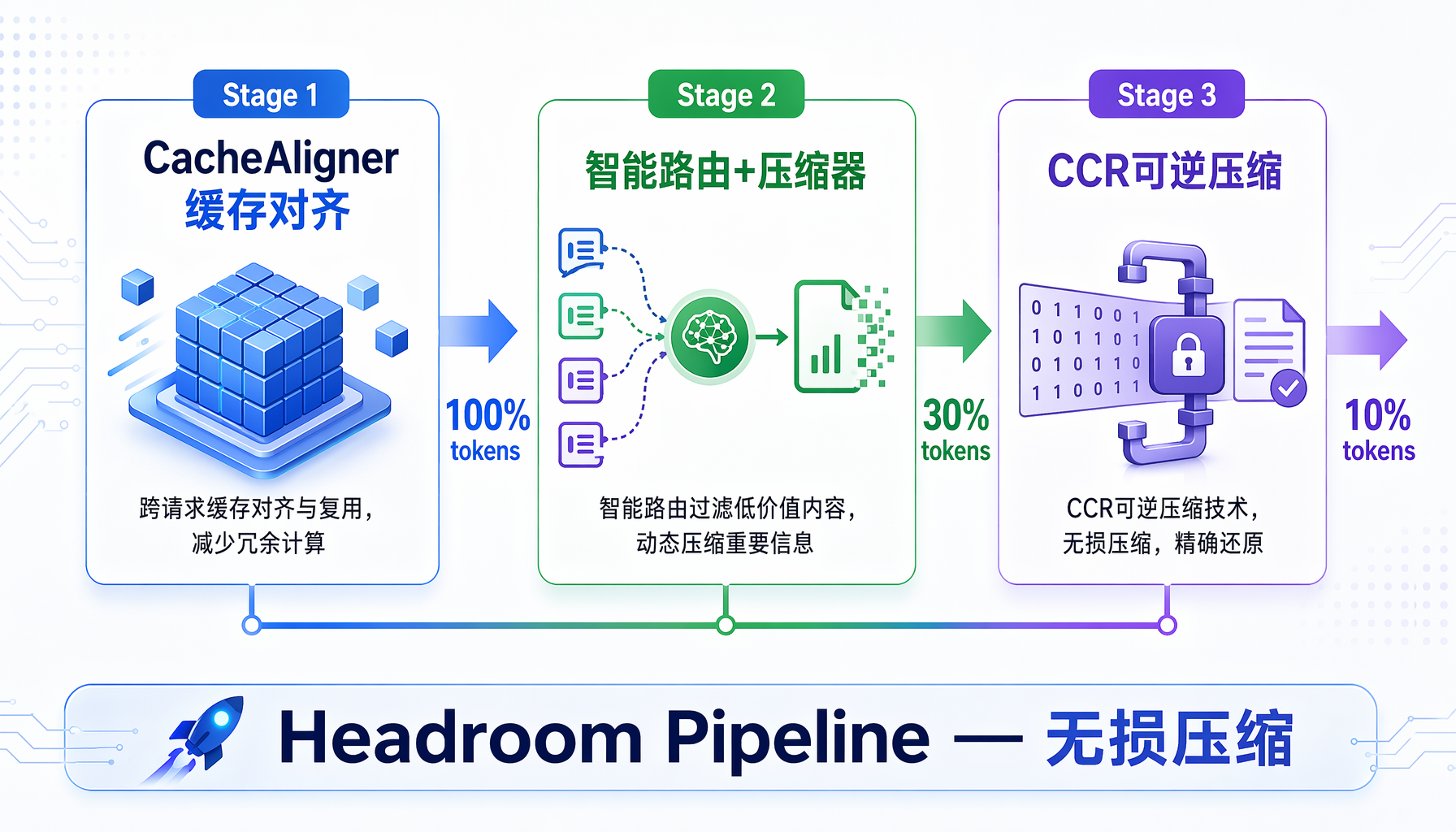
▲ Headroom Pipeline:三阶段无损压缩架构
竞品对比:为什么不是别的工具?
Token 压缩不是新概念。市面上已经有:
- Token Company(YC 投资):Token 压缩即服务,但需要把数据发给第三方
- RTK(Rust Token Killer):开源,但只处理命令行输出
- LeanCTX:RTK 的变体,能力有限
Chopra 认为这些工具都有用,但 Headroom 的独特价值在于:
- 完全本地运行——数据不出你的电脑
- 可逆压缩——LLM 随时可以调回原始数据
- 覆盖全面——不只是文本,代码、JSON、日志、DOM 各有专用压缩器
- 开源免费——不像商业方案按 Token 量收费(省下的钱又花在工具上)
谁在用 Headroom?
The Register 的报道中提到,Netflix 内部已有多个团队在使用 Headroom(虽然这"不是官方项目")。此外,Chopra 透露了一个跨界应用案例:
一家语音 AI 公司将 Headroom fork 后用于降低语音交互延迟。在语音场景下,200 毫秒的响应延迟就会让对话变得不自然。通过压缩上下文,他们成功把延迟压到了可接受范围内。
还有用户 fork 了项目,专门用于视频内容解析。
即将到来:Headlight
Chopra 透露了一个即将开源的相关项目——Headlight。
Headroom 解决的是"压缩",Headlight 解决的是"溯源":追踪每个 Token 的来源。在多模型协作场景下(比如一个 Agent 调用多个 LLM),知道每个 Token 从哪来、经过了怎样的处理链,对于准确性验证和质量控制至关重要。
Chopra 说 Headlight 将在近期开源。
我们能学到什么?
1. Token 成本是你最容易忽视的"隐形支出"
$287 的账单可能看起来不多,但 Chopra 的点在于:如果这不是一个工程师的个人项目,而是一个每天跑几百次 Agent 调用的创业公司呢?
算一笔账:假设你的 AI 产品每天处理 1000 次 Agent 对话,每次平均消耗 50 万 Token。如果 76% 是冗余的,按 Claude Sonnet 的定价($3/百万 Token),你每天烧掉 $114 在无用数据上。一个月就是 $3,420,一年 $41,000。
而 Headroom 是免费的。
2. "多塞上下文 = 更好结果"是危险的幻觉
Chopra 反复强调的一个研究发现:上下文不是越多越好。超过一定阈值后,更多信息不仅浪费钱,还会降低模型输出质量。
这对 AI 创业者是个关键提示:不要盲目追求"把一切放进上下文窗口"。质量 > 数量,这是一个反直觉但被数据证明的规律。
3. 开源工具正在重塑 AI 基础设施层
Headroom 不是第一个、也不会是最后一个"帮用户省 AI 钱"的开源工具。从 Token 压缩到 Prompt 缓存管理,AI 基础设施的"中间件"层正在快速成熟。
对于 AI 创业者来说,这意味着:你不必从零搭建一切。留意开源社区的最新工具,可能一行命令就能省下几千刀的月账单。
行动建议
- 今天就审计你的 Token 消耗:大部分 LLM 服务商(OpenAI、Anthropic)都提供用量 Dashboard,看看你的上下文窗口里塞了什么
- 检查系统 Prompt 中的"缓存杀手":动态日期、UUID、会话 ID——这些让你的 KV Cache 形同虚设
- 试试 Headroom:
git clone后在本地跑起来,用headroom wrap包住你的 CLI 工具,对比前后的 Token 消耗 - 关注 Headlight:当多 Agent 协作成为常态,Token 溯源将成为质量控制的刚需
#AI创业 #Token优化 #开源工具 #成本控制 #AI风向
本文由AI辅助创作,经人工审核编辑发布