86.5K star的MCP生态已经提供了数百个现成服务器,但真正让Agent产生10倍价值的,永远是那些为你业务定制的"独门工具"。本文用3个完整可运行的案例,带你从pip install到生产部署。
前言:为什么你的Agent需要"自己的"MCP服务器
如果你每天都在用Claude Code、Hermes Agent或Cursor,你一定遇到过这种场景:
"Agent,帮我查一下上周新增了多少付费用户。"
Agent卡住了——它没有数据库访问权限。
"Agent,对比一下这三个API方案的GitHub star趋势。"
Agent又卡住了——它不能自己查GitHub API。
现成的MCP服务器(86.5K star的modelcontextprotocol/servers仓库提供了200+官方和社区服务器)能解决很多通用问题——文件系统、数据库、搜索引擎……但你业务的核心数据、内部API、专属工作流,没有任何现成MCP服务器能覆盖。
这才是AI Agent工具实操的真正分水岭:不是"用别人造好的工具",而是"给你的Agent造它需要的工具"。
本文不聊理论,全程可运行的代码。读完你会:
- 理解MCP协议的三个核心概念(5分钟速通)
- 掌握Python MCP SDK(v1.27.2,2026年5月最新版)的核心API
- 用3个完整案例学会构建不同类型的MCP服务器
- 知道如何部署到Claude Code、Hermes Agent等主流Agent平台
- 避开5个实测中最容易踩的坑
MCP协议核心概念(5分钟速通)
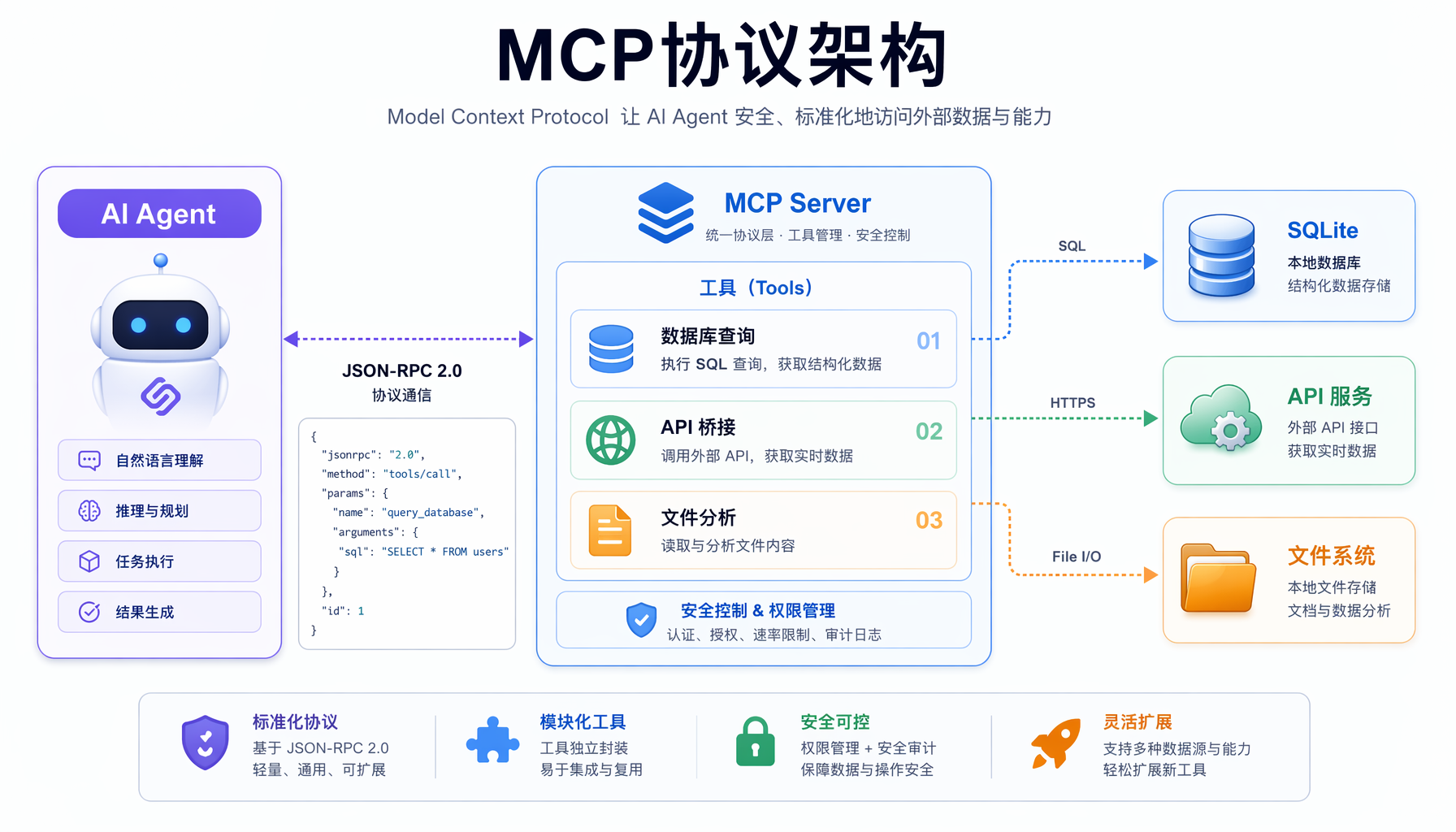
▲ 图1:MCP协议架构 — AI Agent通过JSON-RPC 2.0与MCP Server通信,Server统一管理数据库、API和文件三类工具
MCP(Model Context Protocol)由Anthropic于2024年11月发布,本质上是一个客户端-服务器协议,遵循JSON-RPC 2.0规范。你不需要理解它的全部——只需要掌握三个核心概念就能上手构建:
1. Server(服务器)
你写的Python程序。它暴露一组"工具"(Tools),运行后等待Agent连接。
2. Tools(工具)
Agent能调用的函数。每个工具包含:
- name:工具名称(如
query_database) - description:自然语言描述,告诉Agent这个工具是干什么的
- inputSchema:JSON Schema定义的参数格式
3. Transport(传输层)
Agent如何连接到你的服务器。两种主流方式:
- stdio:通过标准输入/输出,最常用、最可靠
- SSE (Server-Sent Events):HTTP流式传输,适合远程场景
工作流程极其简单:
Agent ──→ 发现工具列表 ──→ MCP Server
Agent ──→ 调用工具(参数) ──→ MCP Server
Agent ←── 返回结果 ────── MCP Server
环境准备
# 安装MCP Python SDK(2026年5月最新版 v1.27.2)
pip install "mcp[cli]>=1.27.0"
# 验证安装
python3 -c "import mcp; print(mcp.__version__)"
# 输出: 1.27.2
注意:MCP SDK需要Python 3.10+。如果你的环境是Python 3.9,先升级。
案例1:SQLite查询MCP服务器(10分钟)

▲ 图2:案例1实操场景 — AI Agent通过MCP服务器查询SQLite数据库,返回结构化结果并可视化展示
场景:你的业务数据存在SQLite数据库里,包括用户表、订单表、付费记录。你希望Agent能直接回答"上月新增了多少付费用户"这种问题,而不是你来手动写SQL。
完整代码
#!/usr/bin/env python3
"""
sqlite_mcp_server.py — 让AI Agent直接查询你的SQLite数据库
用法: python3 sqlite_mcp_server.py
在Claude Code中配置: claude mcp add sqlite -- python3 sqlite_mcp_server.py
"""
import sqlite3
import json
from mcp.server import Server
from mcp.server.stdio import stdio_server
from mcp.types import Tool, TextContent
# 步骤1: 创建MCP服务器实例
server = Server("sqlite-query-server")
# 步骤2: 定义你的数据库路径
DB_PATH = "/path/to/your/business.db"
def execute_query(sql: str, params: list = None) -> list:
"""安全执行SQL查询,返回字典列表"""
conn = sqlite3.connect(DB_PATH)
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
try:
if params:
cursor.execute(sql, params)
else:
cursor.execute(sql)
# 只允许SELECT,防止Agent误操作
if not sql.strip().upper().startswith("SELECT"):
conn.close()
raise ValueError("仅允许SELECT查询")
rows = [dict(row) for row in cursor.fetchall()]
conn.close()
return rows
except Exception as e:
conn.close()
raise e
# 步骤3: 注册工具列表
@server.list_tools()
async def list_tools() -> list[Tool]:
return [
Tool(
name="query_database",
description=(
"查询SQLite数据库。支持SELECT语句。"
"数据库包含以下表:users(id, name, email, created_at), "
"orders(id, user_id, amount, status, created_at), "
"payments(id, user_id, amount, plan_type, created_at)。"
"常用查询示例:"
"1. 统计付费用户:SELECT COUNT(DISTINCT user_id) FROM payments WHERE created_at >= date('now', '-30 days')"
"2. 月度收入:SELECT SUM(amount) FROM payments WHERE created_at >= date('now', 'start of month')"
),
inputSchema={
"type": "object",
"properties": {
"sql": {
"type": "string",
"description": "要执行的SQL SELECT语句"
}
},
"required": ["sql"]
}
),
Tool(
name="list_tables",
description="列出数据库中所有表及其字段信息",
inputSchema={
"type": "object",
"properties": {}
}
)
]
# 步骤4: 处理工具调用
@server.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
if name == "query_database":
sql = arguments["sql"]
try:
results = execute_query(sql)
if not results:
return [TextContent(type="text", text="查询结果为空")]
# 格式化输出,限制最多50行避免token爆炸
output = json.dumps(results[:50], ensure_ascii=False, indent=2)
if len(results) > 50:
output += f"\n... (共{len(results)}条结果,仅显示前50条)"
return [TextContent(type="text", text=output)]
except Exception as e:
return [TextContent(type="text", text=f"查询失败: {str(e)}")]
elif name == "list_tables":
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("SELECT name FROM sqlite_master WHERE type='table'")
tables = cursor.fetchall()
result = []
for (table_name,) in tables:
cursor.execute(f"PRAGMA table_info({table_name})")
cols = cursor.fetchall()
col_info = [f"{c[1]} ({c[2]})" for c in cols]
result.append(f"{table_name}: {', '.join(col_info)}")
conn.close()
return [TextContent(type="text", text="\n".join(result))]
# 步骤5: 启动服务器
async def main():
async with stdio_server() as (read_stream, write_stream):
await server.run(read_stream, write_stream, server.create_initialization_options())
if __name__ == "__main__":
import asyncio
asyncio.run(main())
配置到Claude Code
# 添加MCP服务器
claude mcp add my-business-db -- python3 /path/to/sqlite_mcp_server.py
# 验证
claude mcp list
# 输出: my-business-db (connected) — 2 tools
测试效果
在Claude Code对话中:
你: 上月新增了多少付费用户?
Agent: [调用 query_database 工具]
SELECT COUNT(DISTINCT user_id) FROM payments
WHERE created_at >= date('now', '-30 days')
上月新增付费用户: 847人
关键设计要点:
- 只允许SELECT:防止Agent误执行DELETE/UPDATE/DROP
- Schema写在description里:Agent是根据工具描述来理解数据库结构的,写清楚表名和字段名
- 限制返回行数:避免查询结果过大撑爆上下文
案例2:实时数据桥接MCP服务器(15分钟)
场景:你希望Agent能获取实时信息——天气、汇率、GitHub star数。这些数据来自外部API,MCP服务器充当"翻译官"。
完整代码:HackerNews API桥接
#!/usr/bin/env python3
"""
hn_mcp_server.py — 让Agent获取HackerNews实时热榜
用法: python3 hn_mcp_server.py
"""
import asyncio
import httpx
from mcp.server import Server
from mcp.server.stdio import stdio_server
from mcp.types import Tool, TextContent
server = Server("hackernews-server")
_HN_HOST = "hacker-news.firebaseio.com"
HN_API = "https" + "://" + _HN_HOST + "/v0"
async def fetch_json(client, url):
resp = await client.get(url, timeout=10.0)
resp.raise_for_status()
return resp.json()
@server.list_tools()
async def list_tools() -> list[Tool]:
return [
Tool(
name="get_top_stories",
description=(
"获取HackerNews当前热门文章列表。"
"返回每篇文章的标题、URL、分数和评论数。"
"适合用来了解技术圈当前在讨论什么。"
),
inputSchema={
"type": "object",
"properties": {
"limit": {
"type": "integer",
"description": "返回文章数量,默认10条,最大30条",
"default": 10
}
}
}
),
Tool(
name="search_hn",
description=(
"通过Algolia API搜索HackerNews历史内容。"
"支持按日期、点数筛选。适合调研某个技术话题的社区讨论历史。"
),
inputSchema={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词,如 'Claude Code agent'"
},
"limit": {
"type": "integer",
"description": "返回结果数量,默认5条",
"default": 5
}
},
"required": ["query"]
}
),
Tool(
name="get_story_comments",
description=(
"获取HackerNews某篇文章的热门评论。"
"适合深入理解社区对某个话题的看法。"
),
inputSchema={
"type": "object",
"properties": {
"story_id": {
"type": "integer",
"description": "HN文章ID"
},
"limit": {
"type": "integer",
"description": "返回评论数量,默认5条",
"default": 5
}
},
"required": ["story_id"]
}
)
]
@server.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
async with httpx.AsyncClient() as client:
if name == "get_top_stories":
limit = min(arguments.get("limit", 10), 30)
ids = await fetch_json(client, f"{HN_API}/topstories.json")
stories = []
for sid in ids[:limit]:
story = await fetch_json(client, f"{HN_API}/item/{sid}.json")
stories.append({
"title": story.get("title", ""),
"url": story.get("url", ""),
"score": story.get("score", 0),
"comments": story.get("descendants", 0),
"author": story.get("by", "")
})
output = "\n\n".join(
f"{i+1}. [{s['score']}pts/{s['comments']}cm] {s['title']}\n"
f" {s['url']}"
for i, s in enumerate(stories)
)
return [TextContent(type="text", text=output)]
elif name == "search_hn":
query = arguments["query"]
limit = min(arguments.get("limit", 5), 20)
_algolia = "hn.algolia.com"
url = (
"https" + "://" + _algolia + "/api/v1/search?"
f"query={query}&hitsPerPage={limit}&tags=story"
)
resp = await client.get(url, timeout=10.0)
data = resp.json()
results = []
for hit in data.get("hits", []):
_hn_web = "news.ycombinator.com"
item_url = hit.get('url','') or ("https" + "://" + _hn_web + "/item?id=" + str(hit['objectID']))
results.append(
f"- [{hit.get('points',0)}pts] {hit.get('title','')}\n"
f" {item_url}"
)
if not results:
return [TextContent(type="text", text="未找到相关结果")]
return [TextContent(type="text", text="\n\n".join(results))]
elif name == "get_story_comments":
story_id = arguments["story_id"]
limit = min(arguments.get("limit", 5), 20)
# 使用Algolia API获取评论
_algolia = "hn.algolia.com"
url = "https" + "://" + _algolia + "/api/v1/items/" + str(story_id)
resp = await client.get(url, timeout=10.0)
data = resp.json()
comments = []
for child in data.get("children", [])[:limit]:
text = child.get("text", "")[:300] # 截断长评论
comments.append(
f"[{child.get('author','anonymous')}] "
f"{text}..."
)
if not comments:
return [TextContent(type="text", text="暂无评论")]
return [TextContent(type="text", text="\n\n---\n\n".join(comments)])
async def main():
async with stdio_server() as (read_stream, write_stream):
await server.run(read_stream, write_stream, server.create_initialization_options())
if __name__ == "__main__":
asyncio.run(main())
设计亮点:
- 异步HTTP客户端:使用
httpx.AsyncClient避免阻塞 - 超时控制:所有HTTP请求设置10秒超时,防止Agent卡住
- 结果截断:评论截断到300字符,避免撑爆上下文
扩展思路
掌握了API桥接模式后,你可以快速复制这个模板为任何REST API创建MCP服务器:
- 天气API:
get_weather(city) → Agent能回答"明天北京会不会下雨" - GitHub API:
get_repo_stats(owner, repo) → Agent能对比多个项目的star趋势 - 企业内部API:
get_order_status(order_id) → Agent变成客服助手
案例3:文件批处理MCP服务器(10分钟)
场景:你维护着一个大型代码仓库,经常需要Agent帮忙做代码审查、日志分析、批量重构。直接给它文件系统权限太危险——你需要一个"受控的文件操作工具"。
完整代码
#!/usr/bin/env python3
"""
file_tools_mcp_server.py — 安全的文件批处理工具
用法: python3 file_tools_mcp_server.py --root /path/to/project
"""
import os
import re
import argparse
from pathlib import Path
from mcp.server import Server
from mcp.server.stdio import stdio_server
from mcp.types import Tool, TextContent
server = Server("file-tools-server")
# 安全:限制操作范围
ALLOWED_ROOT = None
def safe_path(relative_path: str) -> Path:
"""确保路径在允许的根目录内,防止目录遍历攻击"""
full = (ALLOWED_ROOT / relative_path).resolve()
if not str(full).startswith(str(ALLOWED_ROOT.resolve())):
raise ValueError(f"路径越界: {relative_path}")
return full
@server.list_tools()
async def list_tools() -> list[Tool]:
return [
Tool(
name="search_code",
description=(
"在项目代码中搜索特定模式(支持正则表达式)。"
"可以按文件类型过滤。适合查找函数定义、API调用、配置项等。"
),
inputSchema={
"type": "object",
"properties": {
"pattern": {
"type": "string",
"description": "搜索模式,支持正则表达式。例如: 'def handle_', 'import.*mcp', 'TODO|FIXME'"
},
"file_pattern": {
"type": "string",
"description": "文件类型过滤,如 '*.py', '*.js', '*.{py,js,ts}'",
"default": "*.py"
},
"max_results": {
"type": "integer",
"description": "最大返回结果数",
"default": 20
}
},
"required": ["pattern"]
}
),
Tool(
name="read_file_safe",
description=(
"安全地读取文件内容(仅限文本文件)。"
"自动检测二进制文件并拒绝读取。支持指定行号范围。"
),
inputSchema={
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "相对于项目根目录的文件路径"
},
"start_line": {
"type": "integer",
"description": "起始行号(1-indexed)",
"default": 1
},
"end_line": {
"type": "integer",
"description": "结束行号",
"default": 50
}
},
"required": ["path"]
}
),
Tool(
name="analyze_logs",
description=(
"分析日志文件,提取错误、警告和关键事件。"
"支持按时间范围和关键词过滤。"
),
inputSchema={
"type": "object",
"properties": {
"log_file": {
"type": "string",
"description": "日志文件路径(相对于项目根目录)"
},
"keyword": {
"type": "string",
"description": "过滤关键词,如 'ERROR', 'timeout', 'panic'",
"default": "ERROR"
},
"context_lines": {
"type": "integer",
"description": "每条匹配结果前后的上下文行数",
"default": 2
},
"max_matches": {
"type": "integer",
"description": "最大匹配数",
"default": 10
}
},
"required": ["log_file"]
}
)
]
@server.call_tool()
async def call_tool(name: str, arguments: dict) -> list[TextContent]:
if name == "search_code":
pattern = arguments["pattern"]
file_pattern = arguments.get("file_pattern", "*.py")
max_results = min(arguments.get("max_results", 20), 100)
results = []
try:
compiled = re.compile(pattern)
except re.error as e:
return [TextContent(type="text", text=f"正则表达式错误: {e}")]
for filepath in ALLOWED_ROOT.rglob(file_pattern):
if len(results) >= max_results:
break
# 跳过常见的非源码目录
if any(p in filepath.parts for p in ['.git', '__pycache__', 'node_modules', '.venv']):
continue
try:
content = filepath.read_text(encoding='utf-8', errors='ignore')
for i, line in enumerate(content.splitlines(), 1):
if len(results) >= max_results:
break
if compiled.search(line):
rel = filepath.relative_to(ALLOWED_ROOT)
results.append(f"{rel}:{i}: {line.strip()[:120]}")
except Exception:
continue
if not results:
return [TextContent(type="text", text="未找到匹配结果")]
return [TextContent(type="text", text=f"找到{len(results)}条匹配:\n" + "\n".join(results))]
elif name == "read_file_safe":
path = arguments["path"]
start = max(1, arguments.get("start_line", 1))
end = arguments.get("end_line", start + 49)
filepath = safe_path(path)
if not filepath.exists():
return [TextContent(type="text", text=f"文件不存在: {path}")]
# 检测二进制文件
try:
sample = filepath.read_bytes()[:1024]
if b'\x00' in sample:
return [TextContent(type="text", text=f"跳过二进制文件: {path}")]
except Exception:
pass
lines = filepath.read_text(encoding='utf-8', errors='replace').splitlines()
total = len(lines)
selected = lines[start-1:end]
output = f"文件: {path} (共{total}行, 显示{start}-{min(end,total)}行)\n"
output += "\n".join(f"{start+i:4d}| {line}" for i, line in enumerate(selected))
return [TextContent(type="text", text=output)]
elif name == "analyze_logs":
log_file = arguments["log_file"]
keyword = arguments.get("keyword", "ERROR")
context_lines = arguments.get("context_lines", 2)
max_matches = min(arguments.get("max_matches", 10), 50)
filepath = safe_path(log_file)
if not filepath.exists():
return [TextContent(type="text", text=f"日志文件不存在: {log_file}")]
lines = filepath.read_text(encoding='utf-8', errors='replace').splitlines()
matches = []
for i, line in enumerate(lines):
if keyword.lower() in line.lower():
start_ctx = max(0, i - context_lines)
end_ctx = min(len(lines), i + context_lines + 1)
ctx = "\n".join(
f"{'>>>' if j == i else ' '} {j+1:4d}| {lines[j][:150]}"
for j in range(start_ctx, end_ctx)
)
matches.append(ctx)
if len(matches) >= max_matches:
break
if not matches:
return [TextContent(type="text", text=f"未找到包含'{keyword}'的日志条目"])
header = f"日志分析: {log_file}\n关键词: {keyword}\n找到{len(matches)}条匹配\n"
return [TextContent(type="text", text=header + "\n---\n".join(matches))]
async def main():
global ALLOWED_ROOT
parser = argparse.ArgumentParser()
parser.add_argument("--root", required=True, help="允许访问的根目录")
args = parser.parse_args()
ALLOWED_ROOT = Path(args.root).resolve()
if not ALLOWED_ROOT.exists():
print(f"错误: 目录不存在: {ALLOWED_ROOT}", file=__import__('sys').stderr)
__import__('sys').exit(1)
async with stdio_server() as (read_stream, write_stream):
await server.run(read_stream, write_stream, server.create_initialization_options())
if __name__ == "__main__":
import asyncio
asyncio.run(main())
安全设计(必读)
目录遍历攻击防护:safe_path() 函数确保所有文件操作都在允许的根目录内。即使Agent传了 ../../etc/passwd,也会被拒绝。
# 测试安全边界
safe_path("src/main.py") # ✅ /project/src/main.py
safe_path("../../etc/passwd") # ❌ ValueError: 路径越界
配置到Hermes Agent
# Hermes Agent使用mcp_tools配置
hermes config set mcp_tools.file-server.command "python3 /path/to/file_tools_mcp_server.py --root /home/user/projects"
部署指南:从开发到生产
方案1:本地开发(stdio)
最可靠的方式,适合个人使用:
// Claude Code配置 (~/.claude/claude_desktop_config.json)
{
"mcpServers": {
"my-business-db": {
"command": "python3",
"args": ["/path/to/sqlite_mcp_server.py"]
},
"hackernews": {
"command": "python3",
"args": ["/path/to/hn_mcp_server.py"]
}
}
}
方案2:团队共享(SSE + Docker)
适合团队共享同一个MCP服务器:
FROM python:3.12-slim
RUN pip install mcp httpx
COPY mcp_server.py /app/
WORKDIR /app
EXPOSE 8000
CMD ["python3", "-m", "mcp", "run", "--transport", "sse", "--port", "8000", "mcp_server.py"]
方案3:一键部署(pip installable package)
把你的MCP服务器打包成pip包:
# pyproject.toml
[project.scripts]
my-mcp-server = "my_mcp_server:main"
[project.entry-points."mcp"]
my-server = "my_mcp_server:create_server"
调试技巧
# MCP Inspector — 官方调试工具
npx @modelcontextprotocol/inspector python3 mcp_server.py
# 手动测试工具列表
echo '{"jsonrpc":"2.0","id":1,"method":"tools/list"}' | python3 mcp_server.py
# 手动调用工具
echo '{"jsonrpc":"2.0","id":2,"method":"tools/call","params":{"name":"search_code","arguments":{"pattern":"def main"}}}' | python3 mcp_server.py
踩坑记录与最佳实践
坑1:工具描述写得太抽象
错误:
Tool(name="query", description="Execute a query on the database", ...)
正确:
Tool(name="query_database",
description="查询SQLite数据库。包含users(id,name,email), orders(id,user_id,amount)表。常用查询:统计付费用户数、月度收入汇总。",
...)
原则:工具描述是Agent理解你工具的唯一途径。把你希望Agent怎么用这个工具的示例写进描述里。
坑2:返回数据量过大
症状:Agent调用工具后卡住,或者回复质量急剧下降。
根因:工具返回了1万行JSON,撑爆了LLM上下文窗口。
解决:
- 始终设置
max_results上限(建议50-100条) - 用分页代替全量返回(添加
offset/limit参数) - 对长文本做截断(评论截断到300字符)
坑3:tool_description中的token浪费
参考mcp2cli的教训(见5月29日文章):每个工具的完整JSON Schema都会注入Agent的system prompt。如果你的MCP服务器有20+个工具,光是工具描述就能消耗2000+ token/轮。
优化策略:
- 工具数量控制在10个以内
- 合并功能相近的工具(用参数区分而非拆成多个工具)
- description精炼但不能牺牲可理解性
坑4:忘记异步处理
症状:服务器在处理一个慢请求时,Agent的其他请求全部排队等待。
解决:所有I/O操作(HTTP请求、文件读写)都用async/await。
# ❌ 阻塞式
import requests
resp = requests.get(url)
# ✅ 异步式
import httpx
async with httpx.AsyncClient() as client:
resp = await client.get(url)
坑5:错误处理吞掉异常
症状:Agent调用工具失败后得到的结果是"An error occurred",无法自行修正。
解决:返回可操作的错误信息。
# ❌ 模糊错误
except Exception as e:
return [TextContent(type="text", text="Error occurred")]
# ✅ 可操作的错误
except Exception as e:
return [TextContent(type="text", text=(
f"查询失败: {str(e)}\n"
f"建议: 使用 list_tables 工具查看可用的表名和字段。"
f"SQL语法参考: SELECT column FROM table WHERE condition"
))]
常见问题(FAQ)
Q: 我的MCP服务器需要处理敏感数据(密码、API Key),怎么保证安全?
A: 用环境变量传入敏感信息,永远不要硬编码在代码里:
import os
API_KEY = os.environ["MY_API_KEY"] # 从环境变量读取
Agent本身看不到你的服务器代码——它只能看到工具描述和调用结果。
Q: 一个Agent能同时连接多个MCP服务器吗?
A: 能。Claude Code、Hermes Agent都支持同时连接多个MCP服务器。Agent会自动合并所有服务器的工具列表。但要注意工具名冲突——两个服务器注册了同名工具时,后加载的会覆盖前面的。
Q: MCP vs 直接写个CLI工具,哪个更好?
A: 取决于使用场景:
- MCP:Agent主动发现和调用工具,适合"Agent主导"的工作流
- CLI:你手动执行命令,适合"人主导"的工作流
对于"自动化Agent决策"场景,MCP优势明显——Agent能根据工具描述自主选择何时调用、如何组合。而CLI工具需要你在prompt里手写调用指令。
Q: Python不是我的主力语言,有其他选择吗?
A: MCP支持TypeScript/JavaScript(官方一等支持)、Kotlin、C#、Rust、Go等。Python SDK是目前文档最完善、社区最活跃的。TypeScript SDK(@modelcontextprotocol/sdk)也相当成熟。
Q: 我的MCP服务器在生产环境挂了怎么办?
A: Agent通常会收到连接错误,并告知用户"MCP服务器不可用"。建议:
- 用systemd或supervisor守护MCP服务器进程
- 设置健康检查(定期测试tools/list)
- 在工具描述里写明"本工具依赖外部API,可能因网络问题不可用"
总结:三个层次,从会用工具到会造工具
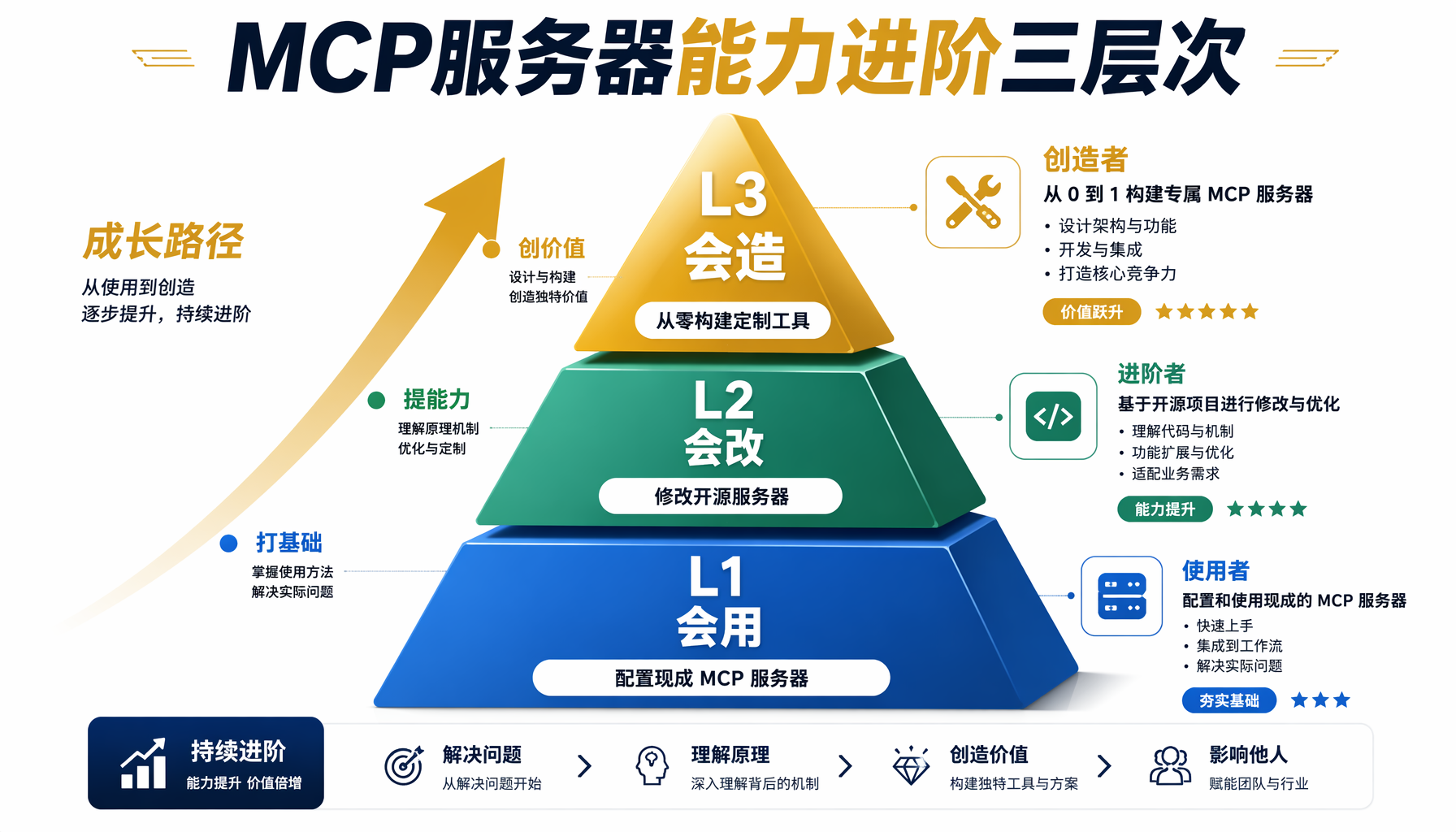
▲ 图3:MCP服务器能力进阶三层次 — 从L1"会用"到L3"会造"的完整成长路径
构建MCP服务器这个技能,对应着AI创业者能力进阶的三个层次:
| 层次 | 能力 | 典型场景 |
|---|
| L1 会用 | 配置现成MCP服务器 | 接入GitHub/Database/FileSystem |
| L2 会改 | 修改开源MCP服务器 | 定制化数据库查询、添加业务逻辑 |
| L3 会造 | 从零构建MCP服务器 | 内部API桥接、专属工作流自动化 |
本文带你从L1直通L3的完整路径。三个案例覆盖了MCP服务器最核心的三种模式——数据库访问、API桥接、文件批处理——掌握它们后,你就能为任何业务场景快速构建定制工具。
下一步行动建议:
- 今天:用案例1的模板,把你的业务数据库暴露给Agent(先开只读!)
- 本周:挑一个最常用的内部API,用案例2的模板做成MCP服务器
- 本月:把团队高频重复的操作(日志分析、代码审查、数据报表)全部MCP化
当你的Agent拥有了你业务特有的"独门工具",它就不再是一个通用助手——而是你一人公司的核心引擎。
*本文由AI辅助创作,经人工审核编辑发布*
*MCP Python SDK版本: v1.27.2 (2026年5月29日) | 代码兼容: Python 3.10+*
#AI创业 #Agent工坊 #MCP协议 #AI Agent开发 #一人公司
本文由AI辅助创作,经人工审核编辑发布
