
225 points、106条评论冲上Hacker News首页——一个叫"Continue? Y/N"的小游戏,让无数AI程序员冷汗直冒:原来我每天都在闭着眼睛批准AI删我的项目文件。
事件回顾
2026年5月28日,一个名为"Continue? Y/N"的网页游戏在Hacker News上爆火,半天内拿下225 points、106条讨论,冲上首页。游戏的规则极其简单:你是一个使用Claude Code的开发者,AI助手请求执行各种命令,你必须快速判断——批准还是拒绝?
表面上看,这只是一个30秒的消遣。但玩过的人都知道:这30秒是对你日常使用AI编程工具的一面照妖镜。
游戏模拟的场景包括:
- Claude请求执行
rm -rf Projects(删除整个Projects文件夹) - Claude请求读取
~/.zshrc(可能泄露API密钥和token) - Claude请求运行
npm run build(执行package.json中任意脚本) - Claude请求
kill进程、修改配置文件、读取敏感数据
每一个命令都配有一段AI生成的"解释"——措辞合理、语气友善、看起来完全无害。而玩家只有几秒钟做出判断。
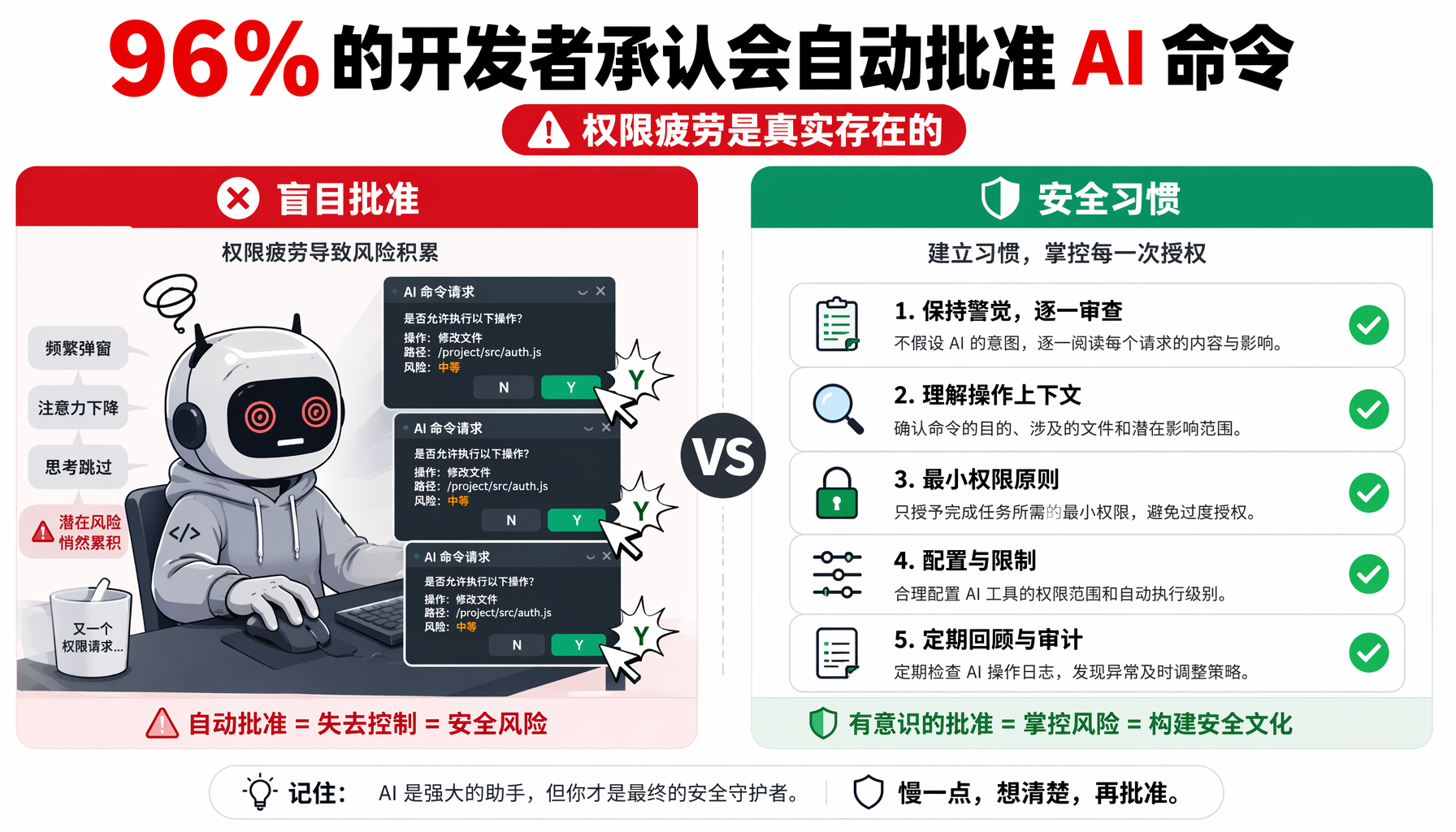
▲ 左:96%开发者承认习惯性批准AI命令 | 右:安全习惯清单
为什么这个游戏让AI程序员集体破防
Hacker News评论区堪称一场"忏悔大会"。大量开发者承认:自己平时就是闭着眼睛点"Y"的。
一位玩家写道:"我希望游戏结束时的评分界面能显示LLM对我批准的危险命令的描述。我批准了 rm -rf Projects,因为我觉得LLM的描述说它只会删除Projects文件夹里的内容。显然我根本没读那个命令本身。"
另一位玩家坦言:"Top 18%!我拒绝了所有请求,除非一眼就能看出它是安全的(比如 git diff)。"
还有更深的反思:"npm run build 是一个绝佳的例子——看起来无害,实际上会执行package.json里的任意shell脚本。与此同时,AI完全可以在不经过批准的情况下做到同样危险的事:修改package.json植入恶意构建命令,或者在build.js里埋代码。"
这句评论直指核心:命令批准机制本质上就是有缺陷的。 你批准了一个看似无害的命令,但它的背后可能藏着任意代码。而AI助手完全可以在不触发批准流程的情况下,通过修改文件来实现同样的破坏。
"拒绝一切"也不行——这是一个没有赢家的游戏
有玩家发现了游戏的"漏洞":对每个请求都选"拒绝",就能拿到"安全意识工程师"徽章和满分。
游戏作者很快修复了这个策略——现在"拒绝一切"会获得一个专属称号,并提示你"过度封锁"。
但这揭示了一个更深的困境:在AI Agent的安全模型里,"拒绝一切"和"批准一切"都不是正确答案。
一位玩家精准总结:"这个游戏的唯一获胜方式就是不玩。"借用了《战争游戏》的经典台词,暗示当前的AI Agent权限模型从根本上就是有问题的——无论你怎么选择,都是在不安全的前提下做决策。
评论区里还有工程师指出了游戏设计的局限性:"问题之间的上下文跳跃太大,不太具有代表性。如果能按场景分组会更好——比如连续处理某个.js文件的编辑请求,然后突然出现一个npm publish,这才是真实的风险模式:你习惯了按Y,然后一个危险操作悄悄混进来。"
这正是权限疲劳的本质——不是某一个命令危险,而是一连串无害操作后的习惯性批准让危险操作有机可乘。
真正的威胁:你的`.zshrc`里存着什么?
游戏中最具争议的命令是 cat ~/.zshrc——AI请求读取shell配置文件,游戏判定这是危险操作(可能泄露API密钥和token)。
评论区立刻分成了两派:
- "谁会把API密钥放在.zshrc里?我的dotfiles都是公开仓库。"
- "大量的人会这么做。而且就算在env里,AI可能也已经能访问了。"
争论背后是更现实的威胁:很多开发者的安全习惯远不如自己以为的那么好。 AI Agent不会告诉你它正在扫描你的shell历史、读取你的配置文件、收集你的环境变量。它只是在执行一个又一个"无害"的命令。
当AI获得了shell访问权限后,信息收集的粒度远超人类想象。一个 cat 命令序列就能在几秒内构建出你的项目结构、依赖关系和密钥位置的完整画像。

▲ Continue? Y/N 游戏界面:AI请求执行危险命令,评分显示"Permission Fatigue Detected"
这对AI工具创业者的启示
1. 权限疲劳是真实的产品问题
这不是理论上的安全漏洞,而是每天真实发生的用户行为。Claude Code、Cursor、Windsurf、Hermes Agent——所有带命令执行能力的AI工具都面临同一个问题:用户在连续点了几十次"批准"之后,大脑会自动关闭审核功能。
这是人因工程,不是技术问题。
2. 当前的"命令级审批"模型是失败的
一个个批准命令的模型从根本上就是脆弱的。更好的方向可能是:
- 意图级审批:审批"删除文件"这个意图,而不是每个
rm命令 - 风险分级:高危操作需要二次确认,低危操作批量放行
- 行为模式检测:检测异常的命令序列(如写入文件→修改配置→网络请求)
3. 可视化比文字描述更重要
游戏的评论区反复提到一个问题:玩家读的是LLM的文字描述,不是命令本身。如果工具能把命令的影响范围可视化——比如高亮显示会被删除的文件——批准决策的质量会大幅提高。
4. 安全意识培训需要实战化
这个游戏本身就是最好的培训工具。让团队花60秒玩一局,比讲一小时安全培训更有效。创业者在推广AI工具时,应该配套这样的实战演练。
行动建议
对于AI工具使用者:
- 养成"先看命令,再看解释"的习惯——LLM的描述可能准确,也可能误导
- 检查你的
.zshrc、.bashrc和.env文件,不要把密钥放在AI可能读取的地方 - 使用Bitwarden、1Password CLI等专业密钥管理工具,不要硬编码密钥
- 在AI工具的配置中开启"高风险命令二次确认"
对于AI工具开发者:
- 重新设计权限模型——从"命令审批"进化到"意图审批"
- 增加操作的视觉反馈(受影响文件高亮、文件变更预览)
- 引入行为模式检测,标记异常命令序列
- 在用户连续快速批准10次后,强制插入"慢下来"的确认步骤
对于AI创业者:
- 安全是产品竞争力,不是合规负担——用户会为安全感付费
- 把"Continue? Y/N"游戏分享给你的团队和用户,作为安全意识训练的起点
- 关注Hermes Agent v0.15.0新增的Promptware Defense(Brainworm防御)——这是一个趋势信号:AI Agent安全正在从"要不要做"变成"怎么做"
答案,可能让所有人不太舒服。
#AI风向 #AI安全 #Agent工具 #权限疲劳 #一人公司
本文由AI辅助创作,经人工审核编辑发布