
2026年5月28日,CNN正式起诉Perplexity,指控其AI搜索引擎"逐字逐句"复制CNN内容。这已经是Perplexity面临的第7起版权诉讼——从纽约时报到大英百科全书,从亚马逊到Reddit,几乎半个美国内容产业都在起诉这家AI搜索新贵。
事件回顾
5月28日(周四),CNN在纽约联邦法院正式对AI搜索引擎Perplexity提起诉讼。CNN指控Perplexity的AI工具在未经授权的情况下,大规模抓取其网站内容,并生成"逐字逐句"(verbatim)的复制品。
根据The Verge获取的起诉书内容,CNN列举了一个具体案例:当用户在Perplexity中输入CNN某篇报道的标题时——"What's next for Minneapolis? A shaky promise, mounting tensions and the fight for control"——Perplexity的AI搜索工具直接生成了该文章的"实质性逐字片段"。
起诉书中最引人注目的一句话是:"人类记者报道、研究、写作、编辑和创作的内容,Perplexity在未经许可、不付报酬的情况下自行取用。"
更令CNN愤怒的是,Perplexity不仅抓取了免费文章,还向用户提供了CNN付费墙后面的订阅内容。CNN声称,他们曾尝试通过技术手段识别和屏蔽Perplexity的爬虫,但对方"无视了这些努力"。
双方并非没有尝试过合作。起诉书披露,CNN在2025年10月曾通过Perplexity的Comet Plus订阅计划与对方达成初步合作意向,但最终"由于无法就多个问题达成一致"(包括Perplexity在回答用户问题时使用CNN内容的限制),协议未能落地。CNN称在那之后,Perplexity"据称没有回应"他们的后续沟通。
Perplexity发言人Jesse Dwyer对此回应简洁有力:"你不能给事实申请版权(You can't copyright facts)。"
Perplexity的"被告俱乐部"正在壮大
CNN远非第一个起诉Perplexity的媒体机构。截至目前,Perplexity已经面临至少以下机构的版权诉讼:
- 《纽约时报》:最早一批起诉者之一
- 《大英百科全书》:指责Perplexity系统性抓取百科内容
- 《梅里亚姆-韦伯斯特词典》:词典内容的版权纠纷
- 《华尔街日报》母公司News Corp:默多克旗下媒体集团
- 亚马逊:技术平台层面的诉讼
- Reddit:社区内容的版权争议
值得注意的是,2025年8月,Perplexity曾出价345亿美元竞购Google Chrome浏览器——一个充满野心的举动。但如今面对从媒体巨头到技术平台的多线诉讼,这家AI搜索新贵的法律账单正在以惊人速度膨胀。
为什么这对AI创业者很重要
1. "AI搜索+内容引用"的法律边界正在划定
Perplexity面临的情况,实际上是所有AI内容产品都在面对的问题:你能否抓取别人的内容来训练AI,然后用AI生成对这些内容的"回答"?
CNN的诉讼策略很聪明——他们不是泛泛地指责"AI侵权",而是聚焦在"实质性逐字复制"这个具体问题上。如果法院认定Perplexity的行为构成侵权,影响将远超Perplexity一家。
任何基于"抓取→索引→AI生成答案"模式的产品(包括各类AI搜索引擎、企业知识库问答、RAG应用)都将面临法律风险。
2. 版权方与AI公司的"合作谈判"正在全面破裂
CNN与Perplexity的故事揭示了一个关键模式:AI公司试图与内容方达成授权协议,但谈判往往在"AI如何使用内容"这个问题上卡住。
内容方想要的不仅是钱——他们要的是对AI如何使用自己内容的控制权。而AI公司希望的是"自由使用,事后付费"的模式。这两种诉求本质上是矛盾的。
对于AI创业者来说,这意味着:
- 不要指望能轻松拿到内容授权(即使你有预算)
- 构建产品时需要将"版权合规"作为基础设施而非事后补救
- 考虑使用自有内容、公开领域数据或明确授权的内容源
3. "You can't copyright facts" 是Perplexity的核心辩护——但未必站得住脚
Perplexity的辩护策略围绕着"事实不受版权保护"这一美国版权法的基本原则。这个论点在法律上有一定道理:新闻事实本身(如"CNN于5月28日提起诉讼")确实不受版权保护。
但问题在于,Perplexity被指控的不是"复述事实",而是"逐字逐句复制表达"。这正好踩在版权保护的核心区域——版权保护的就是"表达形式",而非"事实本身"。
CNN举出的具体例子——输入标题就能获得"实质性逐字片段"——如果属实,这对Perplexity将非常不利。

▲ AI时代的信息生态:从内容创作到智能搜索的信息流动
对AI创业者的3个行动建议
1. 立即审查你的内容来源
如果你的产品依赖抓取第三方网站内容来训练AI或生成回答,现在就应该开始审查:
- 你的数据源是否包含受版权保护的内容?
- 你的AI输出是否有"过度引用"或"逐字复制"的风险?
- 你是否实施了robots.txt尊重机制和内容方的屏蔽请求?
2. 设计"版权安全"的AI产品架构
与其等诉讼来敲门,不如在产品设计阶段就考虑合规:
- 强制AI进行摘要而非复制(在prompt层面增加"请用自己的话重述"指令)
- 对AI输出进行相似度检测(与源文本比对,超过阈值则标记或阻止)
- 为所有引用提供明确的来源归属和链接(像Google News那样)
- 提供内容方的opt-out机制(并确保技术层面真正生效)
3. 关注这个案子的判决——它将成为行业标准
CNN vs Perplexity案的结果将直接影响整个AI内容产业。以下几个可能的走向值得关注:
- 和解:最可能的结果。Perplexity支付赔偿金并签署内容授权协议
- 禁令:法院发布禁令禁止Perplexity使用CNN内容,这将开创先例
- Perplexity胜诉:如果法院认可"事实不受版权保护"的辩护,AI搜索行业将获得巨大法律空间
- CNN胜诉:将触发更多媒体机构加入诉讼,AI内容产品的法律成本将大幅上升
更深层的思考:AI时代的"内容养活AI"悖论
这场诉讼背后有一个更深刻的矛盾:AI搜索引擎的价值高度依赖高质量的人类内容,但它们的存在又在削弱这些内容生产者的商业模式。
CNN需要付费记者去明尼阿波利斯做现场报道,需要编辑把关、法务审核——这些成本每年数以亿计。而Perplexity不需要承担这些成本,却可以通过"引用"CNN的内容来为用户提供价值,同时赚取订阅费(Comet Plus)和广告收入。
这不仅仅是法律问题,更是整个互联网信息生态的可持续性问题。如果内容生产者无法通过内容获利,谁来生产内容?如果没人生产内容,AI搜索又能"搜索"什么?
Perplexity发言人说"你不能给事实申请版权"——这是对的,但事实的采集、验证、呈现需要成本。而当AI可以免费"收割"这些成果时,整个信息生产的激励结构就被打破了。
纽约时报、CNN、大英百科全书——这些机构的存在本身,就是Perplexity能提供高质量答案的前提。起诉它们,某种程度上是在起诉自己的数据来源。
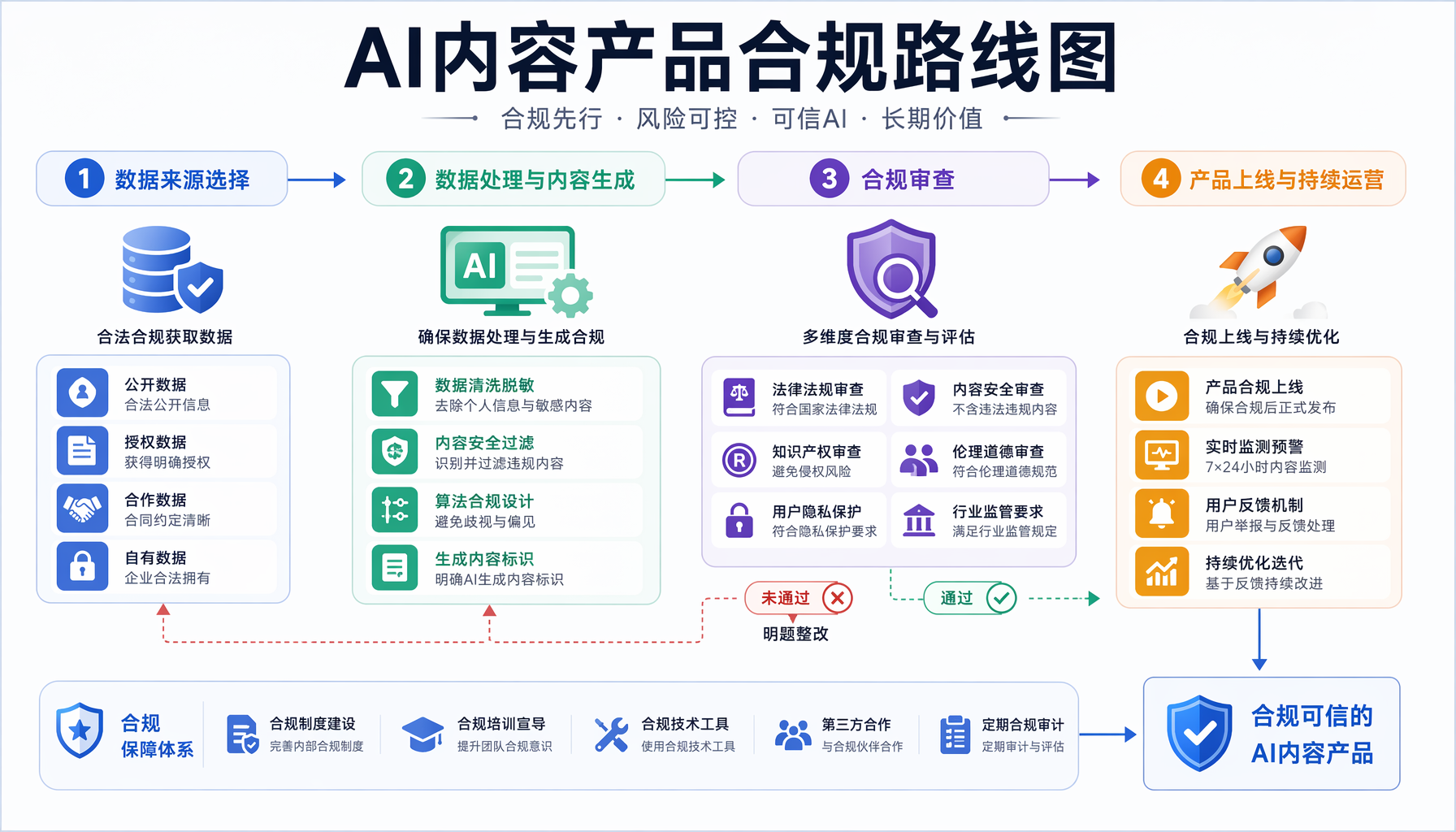
▲ AI内容产品合规路线图:从数据来源到产品上线的完整路径
结论
CNN诉Perplexity案是AI创业领域今年最重要的法律事件之一。无论判决结果如何,它都将重新定义AI产品与内容产业的关系。
对AI创业者而言,这不是一个可以"等判决出来后再说"的问题。版权合规应该从现在开始,成为产品设计和商业模式的核心考量——而不是事后补救的法律支出。
记住CNN诉状里那句话:"人类记者报道、研究、写作、编辑和创作的内容,Perplexity在未经许可、不付报酬的情况下自行取用。"
如果你的AI产品也在"取用"别人的内容——现在是时候想清楚,你的"取用"和"偷窃"之间的那条线,到底画在哪里了。
*本文基于The Verge、Reuters等多家媒体对CNN诉Perplexity案的报道编写。案件仍在审理中,具体事实以法院最终认定为准。*
#AI风向 #AI版权 #Perplexity #CNN #AI创业 #内容合规
本文由AI辅助创作,经人工审核编辑发布