
独立基准测试平台MarginLab的每日追踪数据揭示了一个惊人模式:Opus 4.8发布前5天,Claude Code的SWE-Bench-Pro通过率从65%骤降至50%,工具调用量飙升60%——但Opus 4.8一上线,所有指标瞬间恢复正常。
事件回顾
2026年5月28日,Anthropic正式发布了Claude Opus 4.8。同一天,一个籍籍无名的独立基准测试平台MarginLab,发布了一篇让整个AI开发者社区侧目的博客文章。
MarginLab的团队每天用Claude Code跑SWE-Bench-Pro的一个精筛子集。他们的目标不是发论文,而是追踪一个学术基准无法回答的问题:AI编程工具在日常使用中,性能是否在悄悄变化?
答案令人不安——是的,而且变化恰好发生在Opus 4.8发布前一周。
数据不会说谎
从5月22日到5月26日,Opus 4.7在SWE-Bench-Pro子集上的通过率连续5天跌至50%左右:
| 日期 | Claude Code版本 | 日通过率 |
|---|---|---|
| 5月21日 | 2.1.148 | 64% |
| 5月22日 | 2.1.150 | 50% |
| 5月23日 | 2.1.150 | 54% |
| 5月24日 | 2.1.150 | 50% |
| 5月25日 | 2.1.150 | 50% |
| 5月26日 | 2.1.152 | 52% |
| 5月27日 | 2.1.153 | 66% |
| 5月28日 | 2.1.156 | 72% |
65%的基线通过率 → 50%的低谷 → Opus 4.8上线后瞬间反弹至72%。这个"V型"曲线在统计上显著——MarginLab用的是95%置信区间,意味着这不是随机的日常波动。
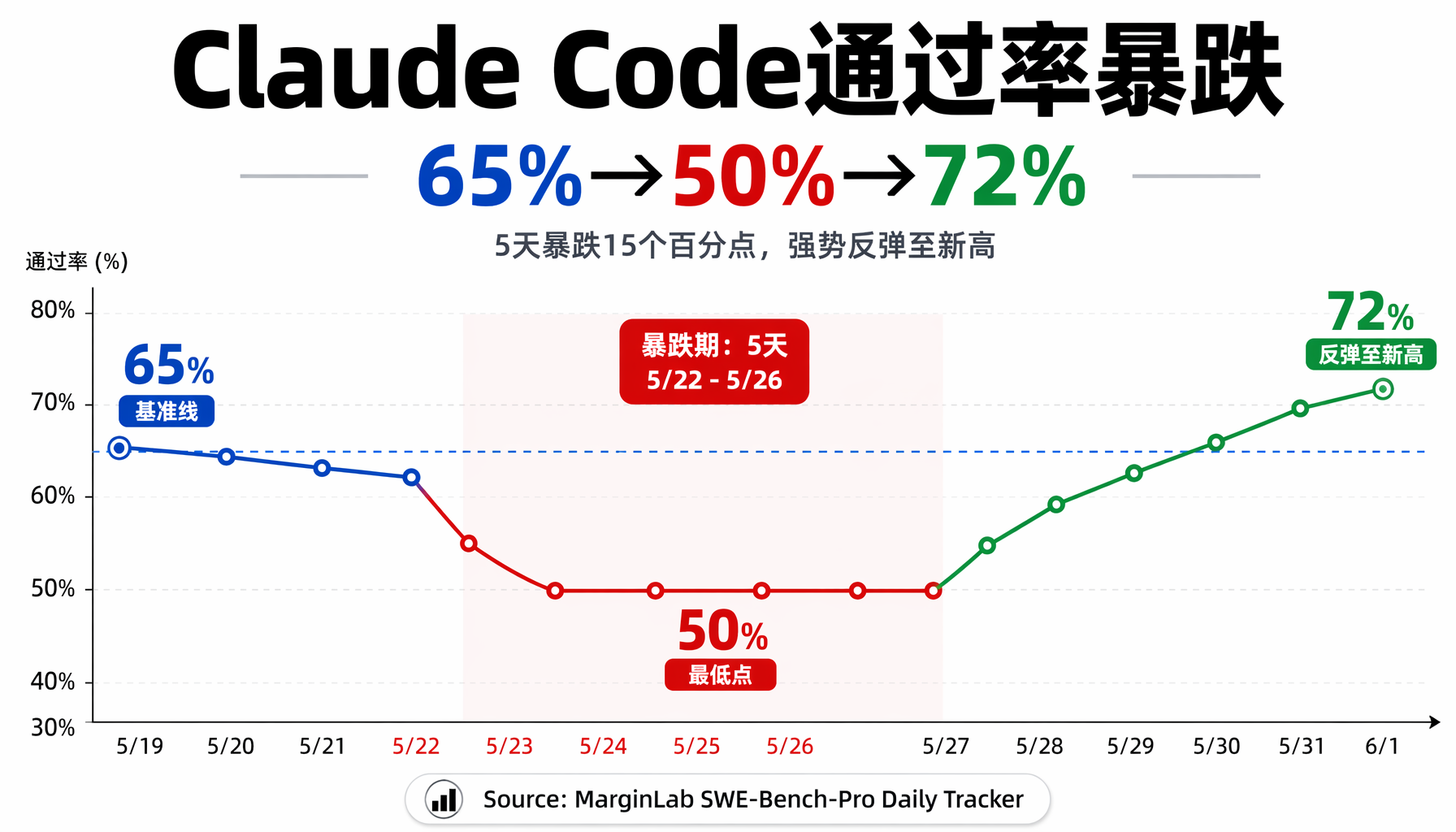
▲ Claude Code SWE-Bench-Pro日通过率:从65%到50%再反弹至72%的V型曲线
更诡异的细节:不是模型的问题,是工具层的问题
MarginLab的分析团队挖得更深。他们发现:
- Opus 4.7模型本身没变——在退化期间,模型版本一直没换。变化发生在Claude Code这个CLI工具层。
- 工具调用量暴增60%——Agent在执行任务时,开始做出更多工具调用(文件读写、shell命令、搜索)。就像一个人突然变得犹豫不决,反复检查同一个文件。
- 输入Token反而下降了——模型"看"的内容变少了,但"动"的次数变多了。这指向一个经典问题:Agent的上下文管理出了bug,导致它在信息不足的情况下做出更多徒劳尝试。
- 退化与Claude Code版本精确对齐——退化从2.1.150版本安装那天开始,在2.1.153版本发布那天结束。这不是巧合。
为什么重要
1. 你每天依赖的AI工具,性能可能在你不注意的时候悄悄变化
Claude Code是当前最主流的AI编程Agent之一。成千上万的开发者每天用它写代码、调试、部署。如果它的通过率突然下降15个百分点——从"大部分时候能完成中等难度任务"降到"一半时间都搞不定"——这是生产力层面的重大事件。
但问题是:普通用户几乎不可能察觉到这种变化。 你不会每天都跑SWE-Bench基准测试。你只会感觉"今天Claude怎么不太好用"——然后怀疑是不是自己的prompt写得不好。
MarginLab的这篇博客之所以有冲击力,正是因为它把"感觉"变成了"数据"。
2. 这是一个"先降级再升级"的模式吗?
MarginLab的结论很克制:"这看起来是Claude Code CLI层的Harness问题,不是模型回归。"但他们在文末加了一句意味深长的话:
"This is not the first time a degradation has aligned before a new model release, and leaves open questions."
翻译:这不是第一次在新模型发布前出现性能退化。问题没有答案,但值得继续追问。
这句话的价值在于:MarginLab是一个独立第三方,他们不说阴谋论,但数据本身已经足够让人产生合理的怀疑——如果一个工具在新版本发布前"恰好"性能下降,新版本"恰好"让性能飙升,那么用户对新版本的正面感受会被放大。
3. 对AI创业者的直接启示
如果你是AI创业者,你的业务可能依赖Claude Code、Cursor、Codex这样的AI编程工具。这个故事告诉你三件事:
- 不要把AI工具当黑盒。建立自己的性能监控——哪怕只是每天跑几个固定的prompt,记录通过率和耗时。
- 新版本上线前后的1-2周,是最关键的观察窗口。如果性能突然变化,不要急着怀疑自己的prompt,先检查工具版本。
- 独立基准测试正在成为AI生态的必需品。学术基准发布时标注的分数,不代表你实际使用时能拿到。持续、独立的日常追踪才是真相。
我们能学到什么
一、建立你的"Agent性能日志"
不需要复杂的SWE-Bench设置。给你一个最简单的方法:
- 准备5个固定的编程任务——覆盖你日常工作的典型场景(比如:写一个API端点、修复一个特定bug、重构一段代码)
- 每天用同样的prompt、同样的工具、同样的模型跑一遍
- 记录通过/失败、耗时、工具调用次数
用一个简单的表格就能捕捉到MarginLab发现的那种模式。比如:
如果某天通过率突然下降20个百分点,你就知道不是你的问题——是工具的问题。
二、理解"Agent退化"的三种可能原因
MarginLab的分析指向了一个关键结论:这不是模型的退化,是Agent Harness(CLI层)的问题。 具体来说:
- 上下文窗口管理bug:Agent的system prompt或上下文拼接逻辑有变化,导致模型"看到"的信息不完整,于是反复调用工具试图获取缺失的上下文。
- 工具调用策略调整:CLI层可能在某个版本中改变了允许的工具调用模式、频率或顺序,影响了Agent的探索效率。
- 有意或无意的"调参":团队可能在调优某些参数(temperature、max_tokens等),这些微调对单个任务影响不大,但在统计显著的样本量下会露出马脚。
三、警惕"版本号惯性依赖"
很多团队的习惯是:npm install完了就不管版本号了。但AI编程工具的版本更新频率远高于传统软件——Claude Code在8天内更新了至少8个小版本(2.1.148到2.1.156)。
建议做法:
- 锁定你的AI工具版本,不要自动更新
- 新版本先在小范围测试,验证通过率没有下降后再全量升级
- 关注像MarginLab这样的独立追踪平台,它们比你更早发现系统性退化

▲ 建立Agent性能日志:每天5个固定任务,记录版本号和通过率
行动建议
- 今天就开始建立Agent性能日志(10分钟):选3-5个你的典型编程任务,固定prompt和上下文,每天跑一次记录结果。
- 锁定Claude Code版本(1分钟):
claude --version查看当前版本,在CI/CD中固定版本号,新版本先测试再升级。 - 关注独立基准测试平台(5分钟):MarginLab(marginlab.ai)的Claude Code和Codex退化追踪器是公开的,每天更新。类似的还有SWE-Bench的官方排行榜。
- 建立"版本变更→性能回归"的敏感度:下次觉得AI工具"今天不太好用"时,先检查版本号,而不是怀疑自己的prompt。
MarginLab原文:marginlab.ai/blog/claude-code-degraded-before-opus-4-8(2026年5月28日发布)
数据来源:MarginLab每天对Claude Code运行SWE-Bench-Pro精筛子集,使用当前SOTA模型、原生CLI、无自定义Harness。所有数据在其公开追踪器上可查。
#AI风向 #ClaudeCode #Anthropic #AI编程 #Opus4.8 #Agent退化 #独立基准测试
本文由AI辅助创作,经人工审核编辑发布