
5月28日,Anthropic 三连发:发布 Claude Opus 4.8、推出 Claude Code 动态工作流、宣布 650 亿美元 H 轮融资。HN 热榜瞬间被 Anthropic 屠榜——Opus 4.8 获得 835 分登顶,融资新闻 125 分,动态工作流 104 分。一家公司在一个下午,同时刷新了模型能力上限和 AI 融资纪录。
事件回顾:一个下午,三重核爆
5月28日,Anthropic 上演了可能是 AI 行业历史上密度最高的一次产品+资本双重发布。
第一弹:Claude Opus 4.8 正式发布。 这是继 Opus 4.7 之后的最新旗舰模型,主打"更好的判断力"和"更强的 Agent 能力"。价格与 4.7 持平,但快速模式降价 67%(速度快 2.5 倍却只要原来的 1/3 价格)。模型同步上线 GitHub Copilot,成为开发者可即刻使用的编程助手。
第二弹:Claude Code 动态工作流(Dynamic Workflows)上线。 这是一个研究预览功能,允许 Claude Code 动态编写编排脚本,在单次会话中并行运行数十到数百个子 Agent。Anthropic 的说法是——"过去需要一个季度的工作,现在几天就能完成"。
第三弹:650 亿美元 H 轮融资。 Anthropic 宣布完成 65B 美元 Series H,投后估值 9650 亿美元。本轮由 Altimeter Capital、Dragoneer、Greenoaks 和红杉资本联合领投,参与方包括 Capital Group、Coatue、Fidelity、General Catalyst、Lightspeed 等几乎所有顶级机构。亚马逊追加 50 亿美元,三星、SK 海力士、美光作为战略基础设施合作伙伴加入。
三件事同一天发生,HN 热榜被 Anthropic 相关帖子霸占——Opus 4.8 以 835 points 登顶,融资新闻 125 points,动态工作流 104 points。
Opus 4.8 到底强在哪?
从 Anthropic 官方公布的测试数据来看,Opus 4.8 的核心升级不在"生成更花哨的文本",而在Agent 场景下的可靠性和判断力。
1. Super-Agent 基准测试:唯一全通关模型
在 Super-Agent 基准测试中,Claude Opus 4.8 是唯一一个端到端完成全部测试用例的模型,在同等成本下超越了此前的 Opus 系列和 GPT-5.5。Kay Zhu(某 Co-Founder & CTO)的测试反馈是:"在翻译、深度研究、幻灯片生成和分析类 Agent 产品中,Opus 4.8 提供了强大的可靠性。"
2. 计算机使用/浏览器 Agent:84% 准确率
Opus 4.8 在 Online-Mind2Web(衡量模型操作浏览器能力的基准)上得分 84%,显著超越 Opus 4.7 和 GPT-5。这是目前最强的计算机使用(computer-use)和浏览器 Agent 模型。
3. CursorBench:全努力级别超越前代
在 CursorBench 上,Opus 4.8 在所有努力级别(effort level)上都超越了此前的 Opus 型号。工具调用效率也显著提升——用更少的步骤达到相同的智能水平。
4. 法律 Agent 基准:首破 10% 全通过率
在 Legal Agent Benchmark 上,Opus 4.8 录得历史最高分,并成为首个在全通过标准(all-pass standard)下突破 10% 的模型。用测试方的话说:"这种准确度提升直接转化为客户可以放心委托的真实律师工作量。"
5. 更好的"判断力"
多个早期测试者提到同一个关键词:judgment(判断力)。Tom Pritchard(Staff Engineer)说:"Opus 4.8 在 Claude Code 中会提出正确的问题、发现自己的错误、在计划不靠谱时提出反对意见、在做出重大改动前先建立信心。"
这恰好是 AI Agent 落地中最稀缺的能力——不是"能做什么",而是"知道什么时候不做什么"。

▲ Claude Opus 4.8 在 Super-Agent、Online-Mind2Web、CursorBench 三大基准测试中的表现对比
650 亿美元融资:数字背后的三个信号
Anthropic 这笔 H 轮融资有几个值得拆解的关键数字。
年化营收突破 470 亿美元。 Anthropic 在公告中透露,自今年 2 月 G 轮以来,全球企业客户采用率持续增长,年化营收(run-rate revenue)已于本月早些时候突破 470 亿美元。这不是一个小型创业公司的数字——这是科技巨头的量级。
估值 9650 亿美元,逼近万亿美元俱乐部。 965B 的估值让 Anthropic 成为全球最有价值的未上市公司之一。HN 上有评论调侃:"差一点就是第一个 kilocorn(千角兽,即万亿估值)。"
15B 来自云计算厂商的承诺投资,其中亚马逊 5B。 这笔融资不只是现金——Anthropic 同时宣布与亚马逊签署了高达 5 吉瓦的新算力协议,与 Google 和 Broadcom 签署了 5 吉瓦的下一代 TPU 协议,还获得了 SpaceX Colossus 1 和 Colossus 2 的 GPU 算力访问权。
三星、SK 海力士、美光的加入更说明问题——当存储芯片和逻辑芯片制造商开始直接参与 AI 公司的融资轮,这意味着 AI 基础设施的军备竞赛已经深入到了半导体供应链层面。
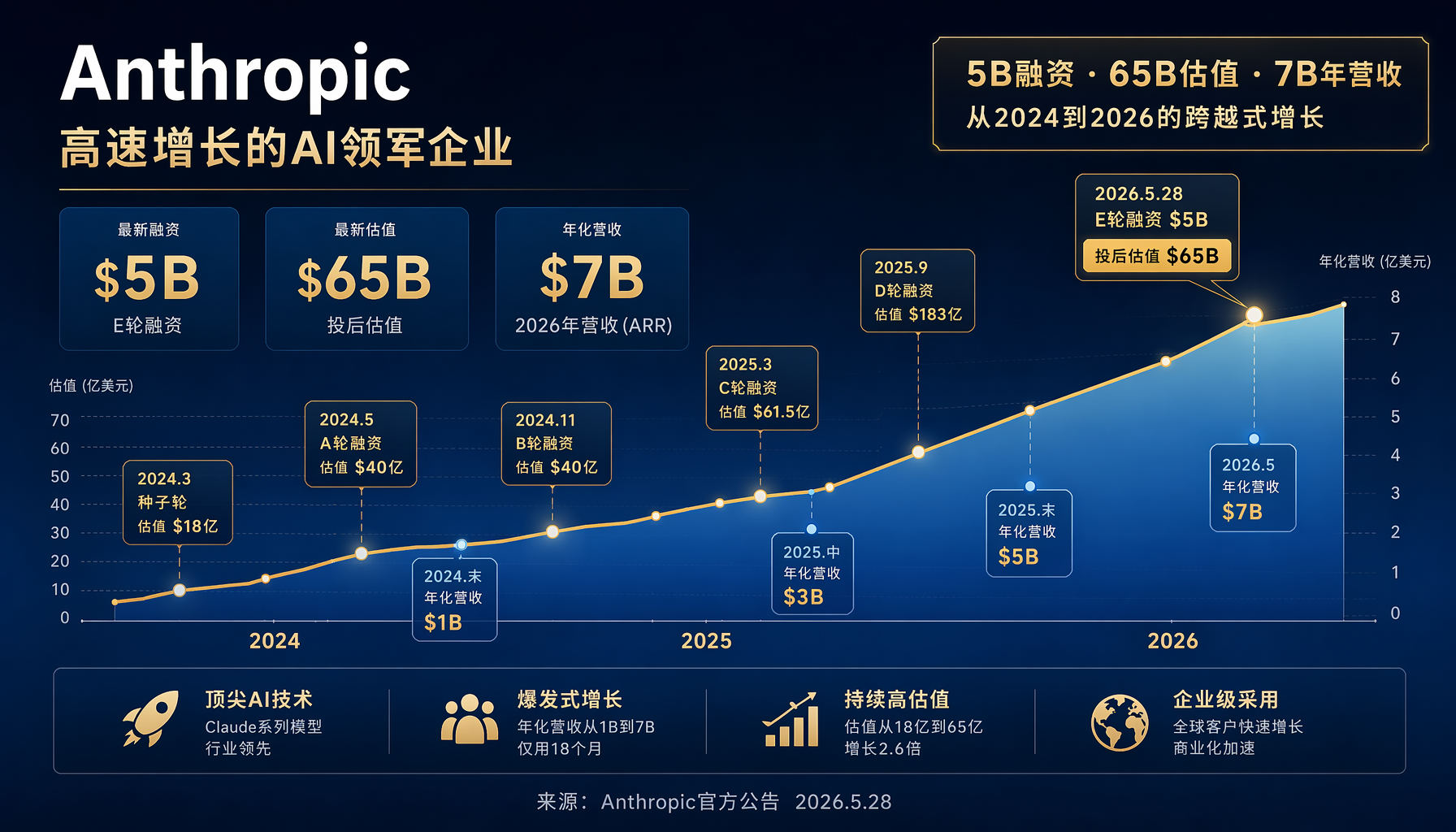
▲ Anthropic 从2024到2026的融资与营收增长轨迹
Dynamic Workflows:AI Agent 从"单兵"到"军团"
Claude Code 的动态工作流功能虽然还在研究预览阶段,但其设计思路值得关注。
传统 AI Agent 模式:一个 Agent 顺序执行任务 → 遇到复杂问题时容易在单一上下文中迷失。
Dynamic Workflows 模式:Claude 动态编写编排脚本 → 并行启动数十到数百个子 Agent → 所有子 Agent 共享同一会话上下文 → 工作完成前自动检查结果。
Anthropic 举了几个典型场景:跨整个服务的 Bug 追踪、涉及数百个文件的代码迁移、多角度压力测试一个计划。这些都是传统单 Agent 模式难以高效完成的任务。
对于 AI 创业者来说,这个功能释放了一个重要信号:多 Agent 协作正在从实验性概念变成生产力工具。 如果你在构建 AI Agent 产品,现在就应该考虑你的架构是否支持并行 Agent 编排。
对 AI 创业者的三个启示
1. 模型能力的"军备竞赛"远未结束
就在有人开始讨论"模型能力是否见顶"的时候,Opus 4.8 在 Agent 基准测试上的提升表明——基础模型的进步空间还很大,尤其是"判断力"和"可靠性"这两个维度。 不要过早押注"模型能力已经够了"的假设。
2. 成本在快速下降
Opus 4.8 快速模式降价 67%(速度快 2.5 倍,价格只要 1/3),这是一个强烈的信号:前沿模型的推理成本正在以超线性速度下降。 如果你的 AI 产品定价基于今天的 API 成本,你需要为半年后成本腰斩做好准备——竞争对手也会。
3. AI 基础设施正在重塑半导体产业链
三星、SK 海力士、美光直接参与 Anthropic 融资轮,这不是普通的财务投资——这是AI 算力需求已经大到足以改变半导体行业的供需格局。 作为 AI 创业者,这意味着两件事:算力供给在可预见的未来会大幅增长(利好),但算力的战略重要性也会被推得更高(如果你高度依赖特定云厂商,议价能力可能下降)。
HN 社区怎么看?
Hacker News 上的反应并不全是赞美。最高赞评论中不乏质疑:
"看起来是个很小的升级?" —— 确实,从普通用户的对话体验来看,Opus 4.8 和 4.7 的差异可能不太明显。
"这些发布越来越像 iPhone 更新——每年都说是最薄最快续航最长,但其实差不多。" —— 这个比喻有一定道理。基础模型的代际提升正在从"震撼"走向"渐进"。
但也有开发者认真指出:在 Agent 场景下,"可靠性"和"判断力"的 5-10% 提升,远比在闲聊场景下的提升重要。 当 AI 在无人监督的情况下操作浏览器、写代码、处理法律文件时,90% 和 95% 的准确率差距意味着"能用"和"不能用"的区别。
至于融资,HN 上有人戏称:"我们得到了更多 Claude Code 补贴!让 VC 继续烧 1000 美元数据中心成本换 200 美元收入吧。" 也有冷静的声音指出:"这很可能是 IPO 前最后一轮融资。Anthropic 和 OpenAI 的拼写里都藏着'IPO'三个字母。"
行动建议
- 如果你是 AI 产品开发者:尽快测试 Opus 4.8 在 Agent 场景下的表现——尤其是"判断力"和"工具调用效率"这两个维度。如果 Opus 4.8 确实能减少 Agent 的无效操作,你的产品体验可能会有明显提升。
- 如果你是 AI 创业者:关注 Dynamic Workflows 的多 Agent 架构设计。如果你的产品涉及复杂任务编排,现在就应该考虑从单 Agent 架构向多 Agent 架构演进。
- 如果你在追踪 AI 行业趋势:Anthropic 的 470 亿美元年化营收和 9650 亿美元估值是一个里程碑。这不是"泡沫"——这是真金白银的企业采购。但同时,如果 Anthropic 和 OpenAI 都在加速奔向 IPO,行业透明度将大幅提升,一些"皇帝的新衣"可能会被揭开。
本文由AI辅助创作,经人工审核编辑发布