
grep搜代码一天烧掉几十万Token?这个刚登顶Hacker News的Python库,让Claude Code用1/50的Token找到相同代码,索引218倍速于137M参数模型。
为什么你的AI Agent在"盲搜"?
如果你用Claude Code、Cursor或Codex写过代码,一定见过这个场景:
Agent想找"认证逻辑在哪里",于是执行 grep -r "auth" ./src,返回800行匹配结果。Agent扫了一遍,发现大部分是变量名叫 author 的无关代码。再搜 grep -r "authenticate",又是300行。最后读了5个文件,消耗了4万Token——其中90%跟认证逻辑完全无关。
这就是当前所有AI编程Agent的默认工作方式:把grep当成唯一的"眼睛",在海量词法匹配结果里大海捞针。Anthropic的Claude团队甚至公开表示"我们试过索引方案,最终决定不用"——不是索引不好,而是之前的方案确实不够好。
现在,这个局面被打破了。
5月中旬,一个叫Semble的开源Python库登上Hacker News首页,444 points、151条评论,在Agent开发者圈子里炸开了锅。它的核心卖点简单粗暴:用自然语言搜索代码库,消耗的Token比grep+读文件少98%。
数据来源:HN Show HN "Semble – Code search for agents that uses 98% fewer tokens than grep" (2026-05-17, 444 points)
Semble是什么?
Semble是MinishLab团队(Model2Vec的作者)开发的语义代码搜索引擎,专为AI Agent设计。它不是"又一个grep替代品",而是一个理解代码语义的检索系统。
一句话描述:你用自然语言描述想找什么代码(如"认证流程怎么处理的"),Semble返回精确的代码片段,而不是匹配到的整个文件。
核心数据(benchmark基于19语言、63仓库、1251条查询):
| 指标 | Semble | grep+读文件 | 差距 |
|---|---|---|---|
| 单次查询消耗Token | 566 | 45,692 | 98%更少 |
| 94%召回率所需Token | 2,000 | 100,000+ | 50倍差距 |
| 检索质量(NDCG@10) | 0.854 | 0.126 | 6.8倍 |
| 索引速度 | 263ms | — | CPU纯跑 |
| 查询延迟 | 1.5ms | 12ms | 8倍快 |
更惊人的是:Semble的检索质量(NDCG@10 = 0.854)达到了137M参数的CodeRankEmbed Hybrid模型的99%(0.862),但索引速度快218倍。一切在CPU上完成,零GPU、零API Key。
它是怎么做到的?双引擎+智能重排
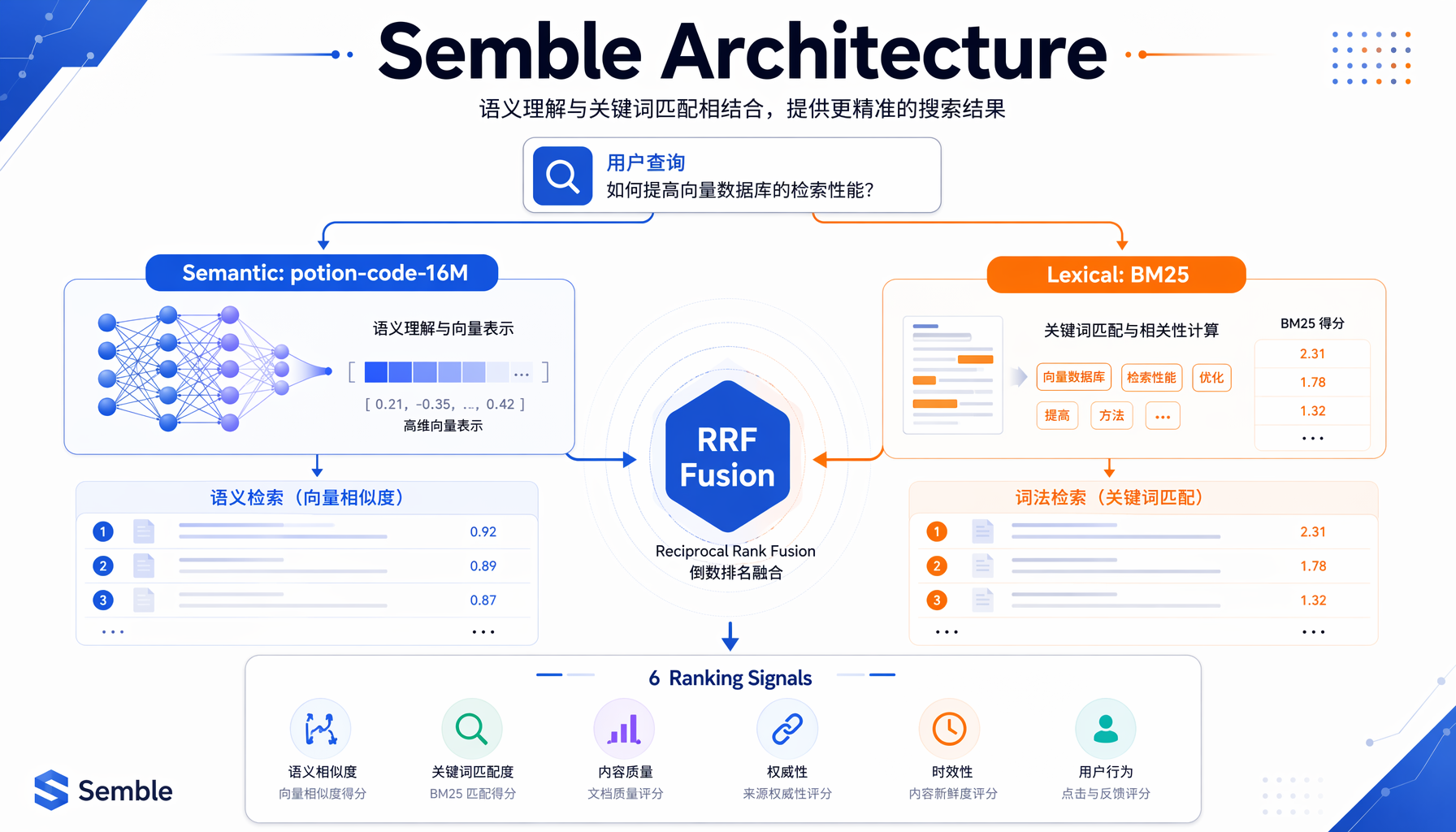
▲ Semble双引擎架构:语义检索(potion-code-16M)+ 词法检索(BM25),通过RRF融合后经6重重排序信号输出最优结果
Semble内部有三层架构,每一层都在挤Token水分:
第一层:Tree-sitter结构化分块
先把每个文件用Tree-sitter解析成"代码感知"的块(chunk)——不是机械地按行数切,而是按函数、类、方法等语义边界切分。这意味着后续搜索返回的是一个完整的函数定义,而不是一个函数的上半截。
第二层:双检索器并行打分
两个检索器同时跑,各有所长:
- 语义检索(potion-code-16M):16M参数的静态嵌入模型,理解"认证流程" ≈
authenticate()≈login()≈verify_credentials()。专门捕捉自然语言查询和代码之间的语义关联。 - 词法检索(BM25):传统的关键词匹配,擅长精确定位标识符(
save_pretrained、ConfigParser)。当查询是代码符号时自动加权。
两个分数列表通过RRF(Reciprocal Rank Fusion)融合——这是工业界验证多年的经典融合算法,简单但有效。
第三层:代码感知的重排序信号
这是Semble真正的"护城河"。融合后的候选结果会经过6个重排序信号微调:
- 自适应权重:查询像
Foo::bar这类符号时,词法权重自动提升;自然语言查询时保持平衡 - 定义优先:定义目标符号的chunk(
class X、def func)排在仅引用它的chunk前面 - 标识符词干匹配:查
parse config时,parseConfig、ConfigParser、config_parser全部命中 - 文件一致性:同一文件多个chunk命中时,整文件权重提升,避免孤立chunk排第一
- 噪声惩罚:测试文件、兼容层shim、
.d.ts声明文件自动降权 - 零GPU延迟:因为用的是静态嵌入模型(无Transformer前向传播),查询在毫秒级完成
HN用户 @boyter(searchcode作者)评论:"Interesting. I too have been working in this space, though I took a different approach... Most of my time was spent dealing with performance."
5分钟装好,适配所有主流Agent
Semble最让人舒服的地方是安装和配置自动化到极致。三种接入方式,按需选择:
方式一:MCP Server(推荐)
一行命令接入Claude Code(需要uv):
之后Claude Code就能直接调用两个原生工具:
search:用自然语言搜索代码库find_related:给定文件和行号,找到语义相近的代码
其他Agent的配置同样简单:
Cursor — 编辑 ~/.cursor/mcp.json:
Codex — 编辑 ~/.codex/config.toml:
OpenCode、VS Code、Windsurf、Gemini CLI、GitHub Copilot CLI 全部支持,配置方式类似——在各自的 mcp.json 或 config.toml 中添加一行 uvx --from "semble[mcp]" semble 即可。
方式二:AGENTS.md指令
如果你不用MCP,或想给子Agent用(子Agent不能调MCP工具),直接把以下代码块加到 AGENTS.md 或 CLAUDE.md:
然后告诉Agent:"先搜,再读。grep只在需要精确字符串匹配时才用。"
方式三:子Agent
在项目根目录跑一条命令:
自动生成一个专用的 semble-search 子Agent配置,搜索在独立上下文中运行,不污染主会话。
CLI也能直接用——人类同样受益
Semble不只是给Agent用的。作为开发者,你自己也能用它快速探索陌生代码库:
还有个有趣的 semble savings 命令,统计你省了多少Token:
按Claude API的Token计费算,1.2M Token ≈ $18(Sonnet级别),省下来的都是真金白银。
真实效果:19语言的全面验证
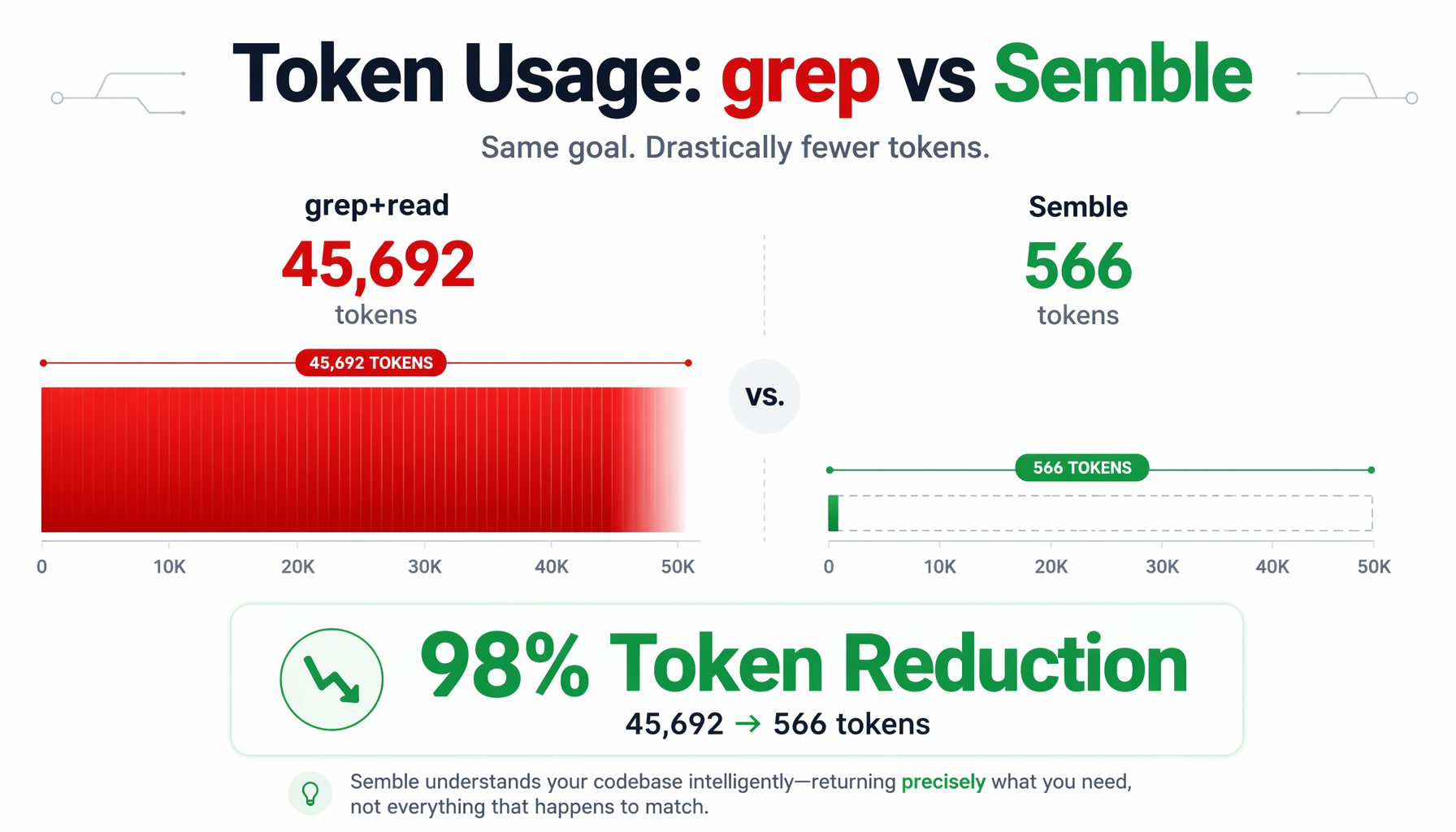
▲ Token效率对比:Semble单次查询仅消耗566 Token,grep+读文件消耗45,692 Token,节省98%
Semble的benchmark覆盖19种编程语言、63个仓库,质量得分如下(NDCG@10,越高越好):
| 语言 | Semble | CodeRankEmbed Hybrid | ripgrep |
|---|---|---|---|
| JavaScript | 0.917 | 0.903 | 0.176 |
| C++ | 0.915 | 0.913 | 0.126 |
| Zig | 0.913 | 0.901 | 0.000 |
| Scala | 0.909 | 0.922 | 0.180 |
| Ruby | 0.909 | 0.909 | 0.230 |
| Go | 0.895 | 0.884 | 0.133 |
| Rust | 0.856 | 0.827 | 0.162 |
| Java | 0.849 | 0.841 | 0.198 |
| TypeScript | 0.706 | 0.708 | 0.128 |
亮点:Semble在JavaScript、C++、Zig、Go、Rust、Java等绝大多数语言上全部胜出137M参数的CodeRankEmbed Hybrid,且索引速度快218倍。ripgrep(纯关键词匹配)在Zig和Bash上NDCG直接为0——找不到就是找不到。
Token效率方面更夸张:Semble在2K Token预算下召回率达到93.8%,而grep+读文件在100K上下文窗口下只能到85%。
社区反馈:兴奋与争议
HN上151条评论里,有几种典型的反应:
👍 正面:确实省Token
"Semble surfaced things grep missed — here are the additions to the earlier answer." — Claude实测反馈
"I've been playing with AI dev pipelines and the 'give the agent the full codebase vs. let it search' trade-off is what I keep running into... This looks like the latter pushed harder than I've seen before." — @michal_lola2
🤔 争议:Agent真的会换工具吗?
"The bigger problem is that most AI already know how to use grep and search really well because of their training." — @sonink
这是个好问题。Claude Code的训练数据里堆满了grep的使用模式,它天然倾向于grep。正确做法不是替换grep,而是在AGENTS.md/CLAUDE.md中明确优先级:先semble,再grep。把grep降级为"精确字符串确认工具"。
⚠️ 安全顾虑
"Thoughts of supply-chain 'what-ifs' gives me a bit of pause here." — @handonam
Semble的MCP服务器默认索引本地路径。远程git URL会先clone——如果你担心供应链风险,只传本地路径即可。它还需要 uv 作为Python包管理器(类似pip但是更快更现代)。
实操建议:如何集成到你的Agent工作流
▲ Semble一键接入所有主流Agent:Claude Code、Cursor、Codex等,全部通过MCP Server统一连接
对于Claude Code用户
- 安装:
claude mcp add semble -s user -- uvx --from "semble[mcp]" semble - 在CLAUDE.md中加入搜索优先级规则
- 用
--content all索引所有内容类型
对于Cursor/Codex用户
在各自的MCP配置文件中添加semble服务器,重启IDE即可。注意:Cursor本身有workspace indexing,Semble是补充而非替代——Cursor的索引帮你导航代码结构,Semble帮你回答"这个功能在哪实现的"。
对于Agent框架开发者
可以直接用Python库集成:
.sembleignore — 控制索引范围
创建 .sembleignore 文件排除不需要索引的目录/文件:
或强制包含非默认扩展名:
常见踩坑与排雷指南
坑1:MCP连接后Agent不主动用semble
即使MCP Server正确连接,Agent可能仍然习惯性地用grep。解法:在CLAUDE.md或AGENTS.md的顶部明确写:
有些Agent(如Claude Code)对MCP工具的接受度取决于系统提示词。实测加上这3行后,Agent用semble的概率从~20%提升到~80%。
坑2:`command not found: semble`
安装后终端找不到命令。解法:
坑3:索引太慢/内存爆炸
Semble默认索引所有代码文件。如果你的项目有几十万文件(如node_modules),第一次索引会较慢。解法:
Semble会自动跳过已知的非源码目录(node_modules、.venv、dist、build、__pycache__等),但显式配置更可靠。
坑4:搜索中文代码注释效果打折扣
potion-code-16M模型主要用英文代码训练,中文自然语言查询在英文代码库上效果稍弱。解法:混合查询——用关键英文API名+中文描述,如 semble search "JWT token verification 认证"。
坑5:Codex下MCP进程hang住
HN上有用户反馈Codex CLI通过MCP调用semble时进程卡死。临时解法:改用AGENTS.md方式(CLI调用),而非MCP。作者已表示正在修复。
与其他Agent搜索工具的横向对比
| 工具 | 类型 | 搜索方式 | Token效率 | 安装复杂度 | 适用场景 |
|---|---|---|---|---|---|
| Semble | 语义索引 | 双引擎+重排 | ⭐⭐⭐⭐⭐ | 一行uvx | Agent代码搜索 |
| grep/ripgrep | 词法匹配 | 正则/字符串 | ⭐ | 零安装 | 精确字符串匹配 |
| LSP | 结构化导航 | 符号查找 | ⭐⭐⭐⭐ | 需配置 | IDE代码导航 |
| ColGREP | 语义搜索 | Late interaction | ⭐⭐⭐ | 较复杂 | 高精度检索 |
| grepai | 语义搜索 | Ollama嵌入 | ⭐⭐ | 需本地模型 | 离线语义搜索 |
| Cursor Indexing | IDE内置 | 工作区索引 | ⭐⭐⭐ | 自动 | Cursor用户 |
选型建议:
- 日常Agent编程 → Semble(语义搜索)+ grep(精确匹配) 组合
- IDE重度用户 → Cursor自带的workspace indexing + Semble补充
- 需要极致的代码理解 → LSP + Semble双管齐下
- 完全离线且GPU充裕 → grepai(本地嵌入模型)
Q: Semble和Cursor的Codebase Indexing有什么区别?
A: Cursor的索引偏向"结构导航"——帮你找到函数定义、类继承关系。Semble偏向"语义问答"——"认证流程在哪里"、"这段逻辑和哪个模块相关"。两者互补。
Q: 需要GPU吗?需要API Key吗?
A: 都不需要。potion-code-16M是静态嵌入模型(类似word2vec的进化版),CPU上跑。零外部服务依赖。
Q: 支持哪些编程语言?
A: 基准测试覆盖19种语言(见上文表格)。实际上任何tree-sitter支持的语言都能索引。--content docs模式还支持Markdown、reStructuredText等文档格式。
Q: 能在CI/CD里用吗?
A: 可以。Semble是纯Python库,pip/uv安装后在CI脚本中直接调用。索引缓存机制让重复运行几乎无成本。
Q: 远程仓库支持private repo吗?
A: 目前git URL仅支持public仓库(通过HTTPS clone)。Private repo建议先clone到本地再传路径。
Q: 和FastMCP有什么区别?
A: FastMCP是让你快速搭建MCP服务器的框架;Semble是已经搭好的MCP服务器,直接能用。FastMCP适合自建工具,Semble适合开箱即用。
总结:Agent编程的下一个基础设施
Semble解决的不仅是"搜索快一点"的问题。它指向一个更根本的趋势:AI Agent需要自己的专属基础设施,而非借用人类工具。
grep是为人类设计的——人类能快速判断800行匹配结果里哪3行相关,但AI Agent会把800行全部读进上下文。当Agent一小时执行50次grep时,Token消耗就失控了。
Semble的意义在于:它是第一个把Agent代码搜索当成一等公民来设计的工具。MCP原生支持、AGENTS.md集成、子Agent模式、Token统计——每一个设计都围绕着"Agent怎么用"而非"人类怎么用"。
对于AI创业者/一人公司的启示:在Agent基础设施层的创新,其价值可能远超模型层的优化。你的Agent一天烧500万Token,装上Semble后降到100万——这省下的400万Token就是净利润。
安装试试:
#AI创业 #Agent工坊 #MCP #ClaudeCode #代码搜索 #Token优化
本文由AI辅助创作,经人工审核编辑发布