
一位开发者逆向分析了自己一个月25,564次模型调用,发现你付的$200月费如果按API原价算,实际成本高达$3,371——而其中64%的钱花在了重复读取完全相同的上下文中。
事件回顾
5月27日,一位开发者在HN上发布了一个名为「Claude Code Token Xray」的开源工具,直接引爆了AI编程社区。这个工具做的事情很简单:读取你本地 ~/.claude/projects/*/*.jsonl 的日志文件,逆向还原出你一个月里Claude Code到底烧了多少Token,烧在了哪里。
结果令人震惊。
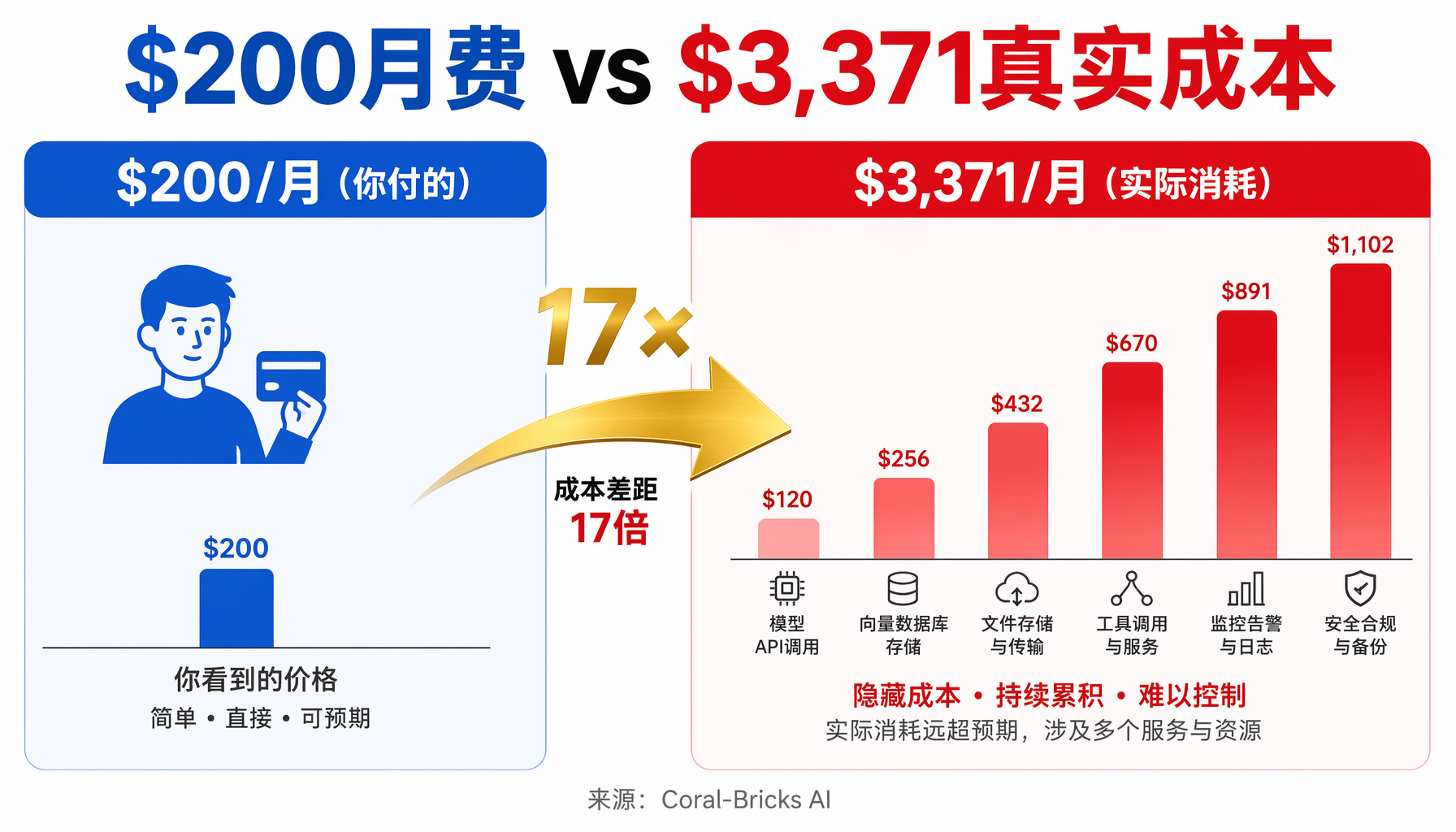
▲ $200月费 vs $3,371真实成本:17倍补贴差距
这位开发者在自己的181个session、25,564次模型调用中,发现了一个残酷的事实:Claude Code的$200月费计划,本质上是Anthropic在以17倍于收入的成本补贴重度用户。
按Opus 4.7的API列表价格计算,他一个月的实际Token消耗账单是 $3,371。而他付的月费只有$200。
更扎心的是,如果去掉Prompt Caching(提示缓存),同样的工作量按原价算将高达 $22,630——是实际月费的113倍。
你的Token到底烧在哪了
这个分析最颠覆认知的发现是:你以为钱花在生成代码上,实际上绝大部分花在了反复读取你已经看过的内容上。
具体分解如下:
| 支出项目 | 金额 | 占比 |
|---|---|---|
| 输入 — 重复读取上下文(缓存读取) | $2,176 | 64% |
| 输入 — 缓存写入 | $682 | 20% |
| 输入 — 全新(未缓存) | $2 | 0% |
| 输出 — 推理(隐藏思维链) | $429 | 13% |
| 输出 — 工具调用 + 摘要 | $82 | 2% |
| 总计 | $3,371 | 100% |
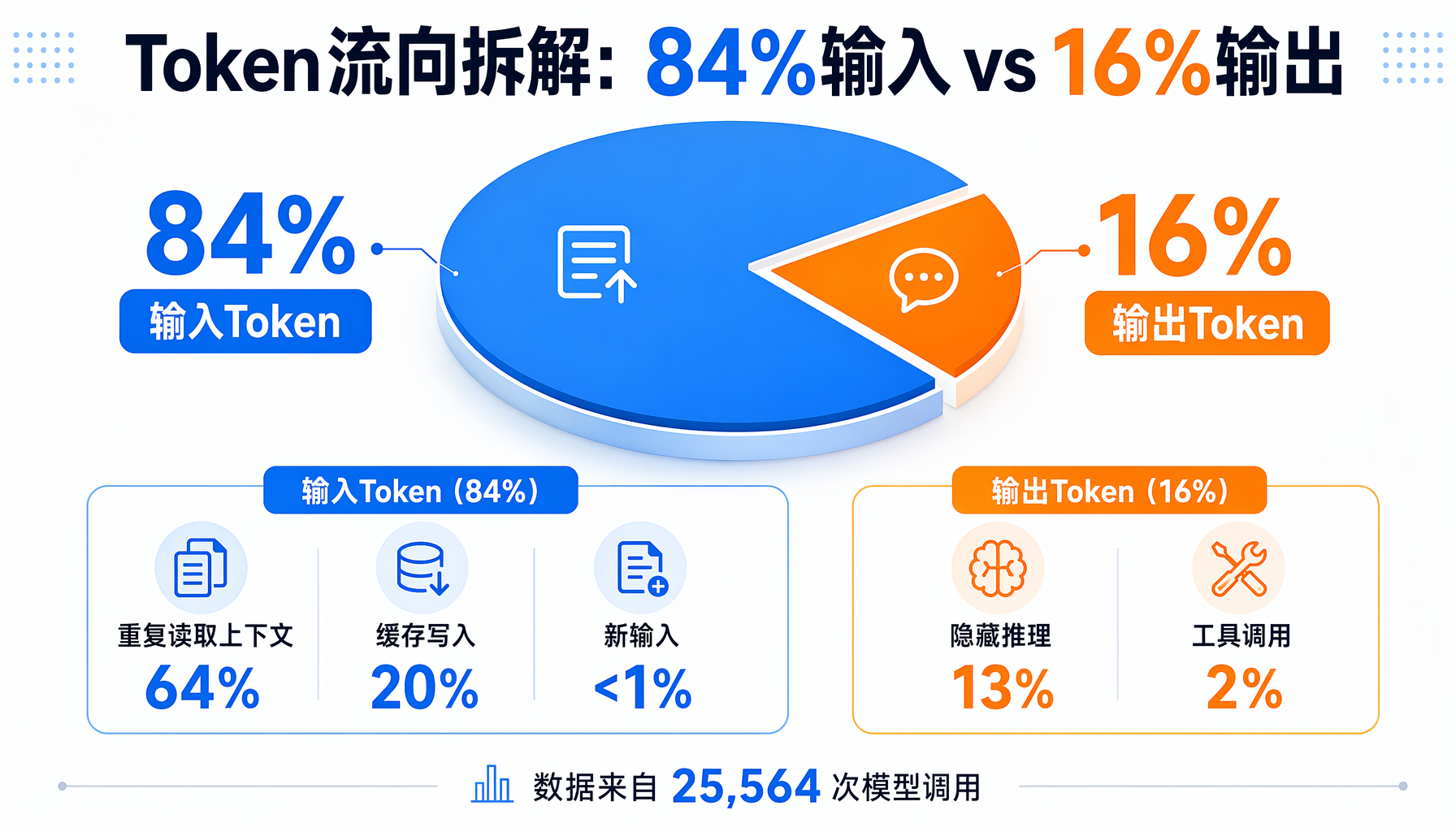
▲ Token流向:84%输入 vs 16%输出,重复读取占绝对大头
几个关键洞察:
1. 输入输出比是84:16。 你感觉自己在让AI"干活"(输出代码),但实际上84%的Token消耗在"喂上下文"(输入)。每轮对话Claude Code都要把整个对话历史重新发送一遍。
2. 重复读取占输入64%。 缓存已经命中了98%的输入——但即便如此,重复读取依然是最大的单项开支。原因很简单:每个session的上下文会增长到约17.3万Token,而每轮对话都要把这17.3万Token全部重发一遍。
3. 「隐藏思维链」比你想象的更贵。 Claude Code的推理过程(思考过程)不显示在界面上,但它占据了输出的84%。换句话说,你看不到的"AI内心独白",才是Token消耗的真正大户。这部分内容不仅消耗输出Token,还会在下轮对话中作为上下文的一部分被重复读取。
4. 缓存是唯一的救命稻草。 如果不开启缓存,同样的工作量将烧掉$22,630。Prompt Caching把99.99%的新输入成本削掉了,但64%的重复读取成本它无能为力——因为这不是"新输入",而是"旧输入每轮都要重发"。
那个150倍的乘数效应
整个分析中最震撼的数字是:29M唯一Token → 43.5亿计费Token = 150倍膨胀。
这是什么概念?你写的代码、你问的问题、AI的回答,所有这些内容的"唯一版本"只有2900万Token。但因为你每轮对话都要把它们全部重发一遍(加上缓存命中、写入、推理Token的输出又被当成输入重复读取),最终API计费的Token量膨胀到了43.5亿。
打个比方:你写了一本300页的书(29M Token),但因为每次开会都要把整本书重新朗读一遍,一个月的"朗读量"相当于把这本书读了150遍(43.5亿Token)。
这对AI创业者意味着什么
对于每天重度使用Claude Code的AI创业者来说,这个分析有三层启示:
第一层:$200月费是"AI创业红利期"的产物。
Anthropic在用一个不可持续的商业模式补贴开发者。17倍的补贴率意味着,一旦Anthropic开始追求盈利(他们已经在这么做了——参见4月底的Token预估成本翻倍),$200月费要么涨价,要么限制用量。你在享受的,本质上是一个有时间窗口的红利。
第二层:优化上下文,而非优化输出。
大多数人省Token的思路是"让AI少写点代码"——但输出只占16%。真正的省钱杠杆在输入端。减少每轮对话的上下文大小、避免在同一个session里堆积不相干的话题、定期开启新session重置上下文——这些才是真正有效的策略。
根据实测数据,一个session的上下文通常在最初的10-15轮对话中快速增长到10万Token以上,之后就稳定在15-18万Token的"稳态"。每次你觉得"再聊一会儿就好了",AI都在默默把这18万Token重新发一遍。
第三层:本地化推理可能是下一个突破点。
"隐藏思维链"占据了输出Token的84%。如果未来能在本地完成推理(类似DeepSeek-R1的本地蒸馏版),不仅能大幅降低API成本,还能避免重复读取推理Token的二次消耗。
行动建议
- 立刻跑一次你自己的账单。 这个工具是开源的(GitHub: Coral-Bricks-AI/coral-ai,Apache 2.0协议),只读本地日志,不发送任何数据。
pip install -r requirements.txt && python3 cost.py就能看到你自己一个月的真实成本。 - 养成"分session"的习惯。 不要在一个session里解决所有问题。每完成一个独立任务就开新session。上下文从零开始,比从18万Token开始便宜得多。
- 关注Anthropic的定价变动。 4月底他们已经上调了企业开发者的Token预估成本100%+。$200月费的17倍补贴不可能是永久的。提前做好成本预案。
- 考虑多模型组合策略。 不是所有任务都需要Opus 4.7。简单的代码重构、格式调整,用更便宜的模型(如Haiku或DeepSeek-V4)同样能完成——而它们的API价格只有Opus的1/10甚至更低。
一个值得深思的问题
当一位独立开发者用一个周末写出的开源工具,能比Anthropic自己的成本仪表盘更清晰地揭示Claude Code的真实经济学——这本身就说明了一个问题:我们离"透明的AI成本"还有多远?
Claude Code的$200定价之所以能成立,恰恰是因为大多数用户不知道自己的实际消耗是多少。当你知道了真相(一个月实际烧了$3,371),还会觉得$200很便宜吗?还是会开始担心,这个价格还能维持多久?
对于AI创业者来说,答案很明确:在红利还在的时候充分利用它,但永远不要把它当成永久的成本结构来规划你的商业模式。
#AI创业 #ClaudeCode #Token优化 #一人公司 #AI编程
本文由AI辅助创作,经人工审核编辑发布