
5月26日一篇论文登上Hacker News 107分热榜,说LLM需要"睡眠"来消化上下文。同一个月,Anthropic直接给Claude Agent加了"做梦"功能。这不是科幻,而是Agent长时记忆的工程解法——你的Agent不需要每次都从零开始。
一、论文说了什么:LLM的"睡眠"机制
5月26日,一篇名为《Language Models Need Sleep》的论文登上Hacker News热榜(107 points,80条评论,排名前10)。标题听起来像科幻,但内容非常硬核——这是一个关于Transformer模型如何处理长上下文的架构级方案。
论文的核心发现可以概括为:Transformer的Attention机制存在根本性的扩展性矛盾。你想让模型记住更多东西,但Self-Attention的复杂度随上下文长度平方增长。处理10万token的上下文,计算量是1万token的100倍。更糟的是,上下文越长,Attention的"注意力"反而越稀释——模型对关键信息的定位精度下降。
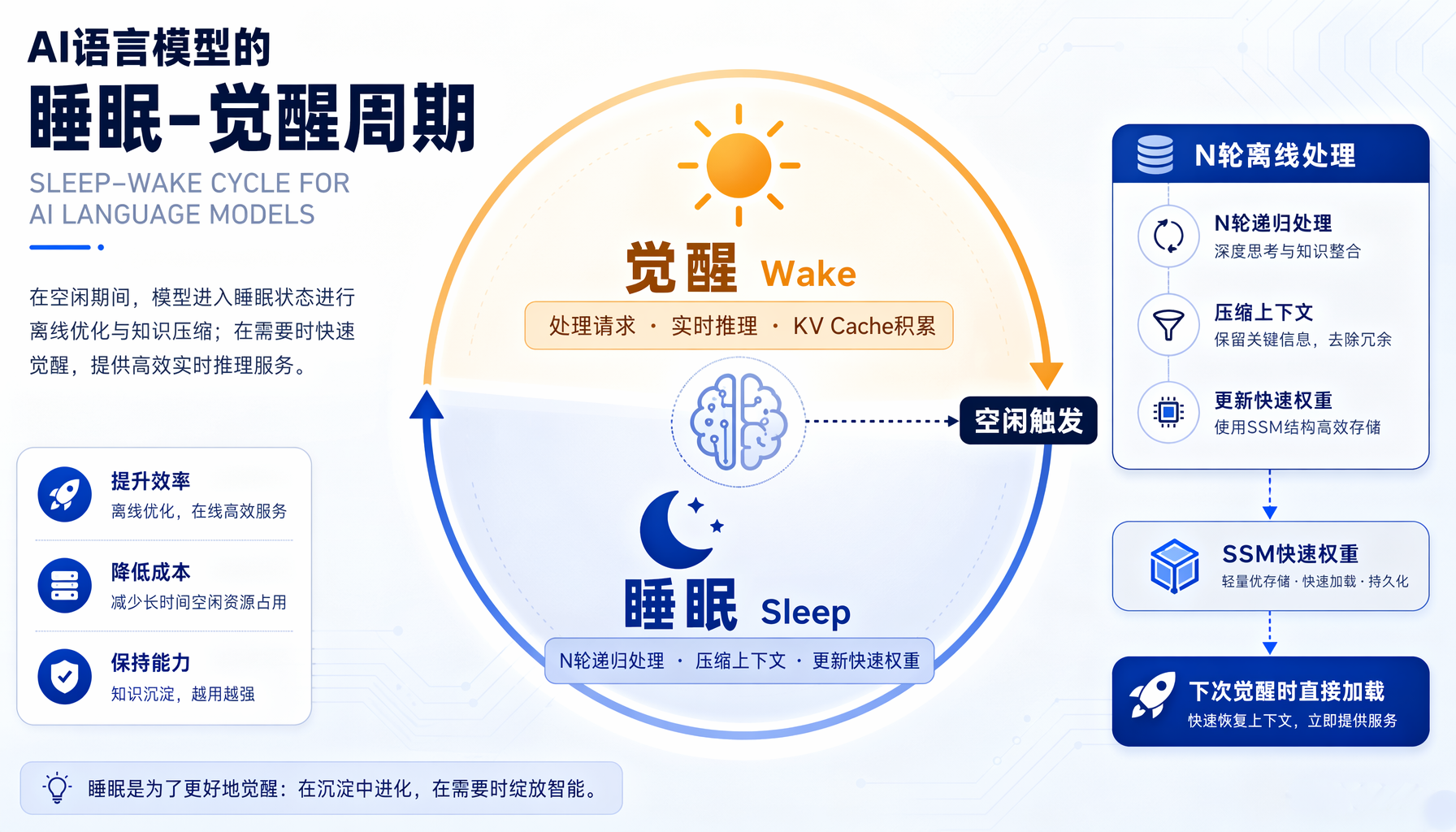
研究团队的解法叫做"睡眠-觉醒"循环机制(Sleep-Wake Cycle),分三个阶段:
第一阶段:觉醒(Wake) 模型正常工作。处理用户输入,生成响应。这个阶段和普通LLM推理没有区别——所有上下文都在KV Cache中。
第二阶段:睡眠(Sleep) 当模型进入空闲状态,系统启动离线处理。核心操作是:对累积的上下文进行N轮递归处理,通过一个学习到的局部更新规则,将关键信息从KV Cache"压缩"到State-Space Model(SSM)模块的快速权重(Fast Weights)中。
第三阶段:再次觉醒 下次推理时,模型直接从SSM的快速权重读取已消化的上下文。Attention只需要处理当前轮的增量信息,而不是从头计算整个对话历史。
翻译成工程语言:Agent在空闲时自动把对话记录"消化"成结构化的记忆模块,下次启动时直接加载,不再从头计算整个上下文。
论文在三个层级的实验上做了验证:
| 测试任务 | 类型 | 关键发现 |
|---|---|---|
| 元胞自动机(Cellular Automata) | 合成任务 | 标准Transformer失败,睡眠模型成功 |
| 多跳图检索(Multi-hop Graph) | 合成任务 | SSM-Attention混合模型优于纯Transformer |
| 数学推理(Math Reasoning) | 真实任务 | 增加睡眠迭代N,深层推理准确率持续提升 |
最关键的那句话在论文结论里:"增加睡眠时间N对性能的提升,在需要更深层推理的样本上最为显著。" 这意味着,越复杂的任务,越需要"睡够"。
HN评论区有一位署名rahen的用户提出了一个非常精炼的总结,获得了大量赞同:
"这就是我之前一直在想的三层记忆系统——L1(KV Cache)做短期记忆,L2(LoRA微调)做中期记忆,L3(基础权重)做长期记忆。睡眠就是把信息从L1迁移到L2的过程。"
这个框架恰好和Anthropic最新的产品方向完全吻合。
▲ LLM睡眠-觉醒循环:觉醒阶段处理实时请求并积累KV Cache,睡眠阶段通过N轮递归压缩上下文并更新SSM快速权重,下一次觉醒时直接加载
二、Anthropic已经动手了:Claude Agent的"做梦"功能
论文刚火,但Anthropic的动作更快。
5月7日,Anthropic给Claude Managed Agents上线了三个新功能,其中最受关注的就是Dreaming(做梦)——目前处于Research Preview(研究预览)阶段。
Dreaming的运作逻辑非常直白:
- 检测空闲:当Agent处于无任务状态时,系统自动调度后台进程
- 扫描历史:遍历该Agent过往的所有对话记录、内存日志和已完成任务
- 提取模式:从中识别两类关键信息:
- 错误模式:反复出现的失败路径、被用户纠正的操作
- 成功模式:稳定有效的解决路径、用户的偏好习惯
与Dreaming同时发布的还有两个功能:
Outcomes(成果验收):开发者可以编写评分标准(rubric),由独立的评分系统对Agent的输出进行验收。不达标就退回重写,直到满足门槛。关键是评分系统与Agent的推理过程隔离——避免"自己给自己打分"的偏差。
Multiagent Orchestration(多Agent编排):允许多个Claude Agent并行处理复杂任务的不同模块。配合Webhooks的事件驱动触发,整个流程可以脱离持续的人工prompting,自动跑完。
5月14日,在旧金山Code with Claude开发者大会上,Anthropic进一步展示了这三个功能的协同效果:Agent接到一个复杂任务 → 自动拆分为子任务分发给多个Agent → 每个Agent独立执行 → Outcomes评分验收 → 完成后触发Dreaming复盘 → 所有经验沉淀到团队共享记忆。
这套组合拳的指向非常明确:让Agent从"执行单次指令"进化为"托管长期项目"。
Dreaming这个名字起得很诗意,但工程意图极其清晰。它不是让AI"思考"或"产生意识",而是给Agent加了一个定期整理的夜间模式——把散落的执行记录转化为可复用的模式识别。对于需要处理复杂、长周期任务的开发者来说,这种"越用越顺"的复利效应,可能比单次响应的智商提升更实用。
三、三层记忆架构:你的Agent应该怎么设计
▲ AI Agent三层记忆架构:L1短期记忆(KV Cache)、L2中期记忆(LoRA/向量检索)、L3长期记忆(基础模型权重),睡眠机制实现L1→L2的知识迁移
结合论文的理论框架和Anthropic的工程实践,我总结了一套可以立即落地的三层记忆架构:
| 层级 | 类比 | 存储位置 | 内容 | 更新方式 | 典型延迟 |
|---|---|---|---|---|---|
| L1 短期记忆 | 工作记忆 | KV Cache | 当前会话的完整上下文 | 实时追加,会话结束清空 | ~0ms |
| L2 中期记忆 | 睡眠消化 | LoRA/向量库 | 跨会话的经验模式 | 后台"睡眠"时更新 | ~50ms(检索) |
| L3 长期记忆 | 晶体智力 | 基础模型权重 | 通用知识 | 完整训练周期 | 月级别 |
这个框架的美妙之处在于:每一层都有明确的职责边界,且更新成本逐层递增。L1最快但最贵(每次推理都计费),L3最便宜但更新最慢。
L1:短期记忆管理——触发式上下文压缩
这是Agent最"热"的记忆层。每条对话都在KV Cache中累积,遇到以下三个问题之一就必须管理:
- 上下文窗口逼近上限(Claude 200K,GPT-4 128K,DeepSeek V4 128K)
- Token成本失控——长上下文的API计费按token累计,一次50K上下文的推理比5K上下文贵10倍
- Attention稀释——上下文越长,模型对关键信息的"注意力权重"越低,回复质量反而下降
实战策略:触发式分层压缩。当上下文使用率超过窗口的60-70%时,自动触发压缩:
压缩prompt的设计是最关键的环节。一个有效的压缩prompt必须明确"不可丢失信息清单":
L2:中期记忆——"睡眠"机制的主战场
这是整个架构中最关键的一层,也是论文和Anthropic Dreams共同指向的核心。两种主流实现方式:
方案A:LoRA微调(论文+rahen方案)
每次L1压缩后,将压缩摘要存入重放缓冲区(Replay Buffer)。在Agent空闲时段:
- 从缓冲区采样N条历史摘要
- 用这些摘要作为训练数据,微调一个小型LoRA模块(典型大小:1-10MB)
- 下次会话自动加载这个LoRA,Agent直接获得"经验"
优点:推理时零额外延迟(LoRA已融入模型权重),经验"内化"最深。 缺点:需要GPU资源做微调,且微调不当可能引入灾难性遗忘。
方案B:向量检索(Anthropic Dreams的做法)
将每次会话的关键事件(成功/失败模式)编码为向量存入数据库:
- 用Embedding模型(如text-embedding-3-small)将事件文本转为向量
- 存入ChromaDB/Pinecone/Weaviate
- 新会话启动时,用当前任务描述做相似性检索
- 将检索到的相关历史经验注入系统提示词
优点:实现简单,无需GPU,实时更新。 缺点:检索延迟~50ms,经验"外挂"在prompt中,占用当前会话的token预算。
成本对比:
| 维度 | LoRA微调 | 向量检索 |
|---|---|---|
| 存储成本 | 1-10MB/adapter | 每事件~1KB |
| 查询延迟 | ~0ms(已融合) | ~50ms(检索+注入) |
| 更新频率 | 天级别(需微调) | 实时(写入即生效) |
| GPU需求 | 需要 | 不需要 |
| Token消耗 | 0(内化) | 每次注入~500-2000 token |
| 适用场景 | 高频固定任务的Agent | 多样化任务的Agent |
L3:长期记忆——基础模型更新
这一层Agent开发者通常不需要操心——等基础模型厂商更新即可。但如果你用开源模型(如DeepSeek V4、Qwen),可以通过持续的指令微调来更新L3。注意:L3的更新成本极高(需要大量GPU小时),且存在灾难性遗忘风险,不建议作为常规操作。
四、手把手:给你的Agent加"睡眠"功能
以最常见的Python Agent为例,实现一个最小可行的"睡眠"机制。完整代码约200行,核心分三个模块:
模块1:会话跟踪器(Session Tracker)
模块2:睡眠处理器(Sleep Processor)
模块3:Agent主循环
五、成本分析:为什么"睡眠"能省钱
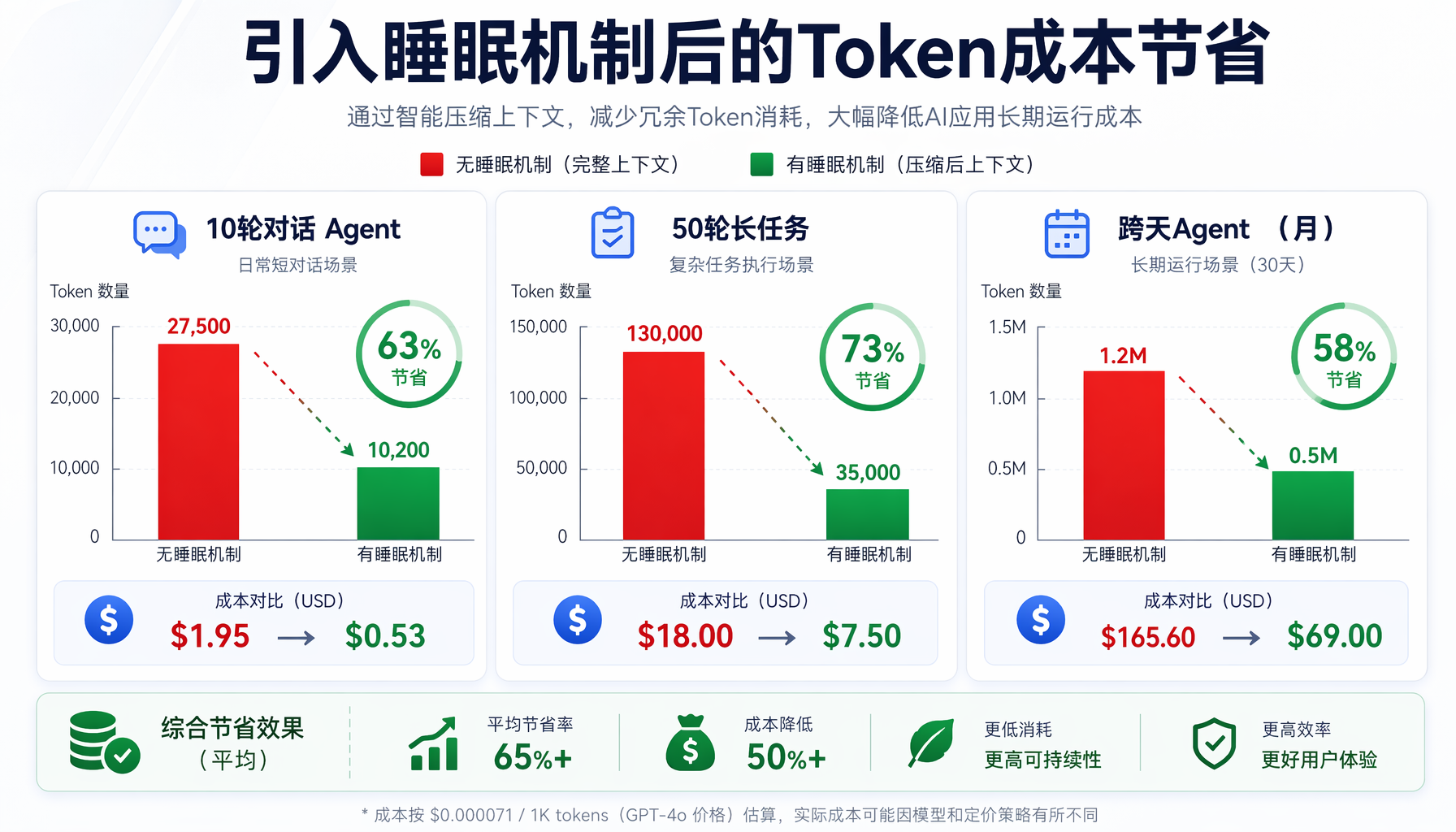
▲ 引入睡眠机制后的Token成本节省:10轮对话Agent节省63%、50轮长任务节省73%、跨天运行Agent月均节省58%
结合论文数据和社区实际经验,来算一笔真实的成本账:
场景1:10轮对话的Agent(典型客服/助手)
| 指标 | 无睡眠 | 有睡眠(L1+L2) | 节省 |
|---|---|---|---|
| 首轮token | 500 | 500 + 200(记忆注入) | -40% |
| 第10轮token | 5000(累积10轮) | 800(当前轮+压缩摘要) | -84% |
| 10轮总token | ~27500 | ~10200 | -63% |
场景2:50轮长任务(代码审查/项目跟踪Agent)
| 指标 | 无睡眠 | 有睡眠 | 节省 |
|---|---|---|---|
| 总token | ~130000 | ~35000 | -73% |
| 总API费用(Claude $15/M token) | $1.95 | $0.53 | 节省$1.42/任务 |
场景3:跨天Agent(每日运行的自动化Agent)
假设每天20轮对话,一个月30天:
| 指标 | 无睡眠 | 有睡眠 | 节省 |
|---|---|---|---|
| 月总token | ~1.2M | ~0.5M | -58% |
| 月API费用 | ~$18 | ~$7.5 | 节省$10.5/月 |
HN上有用户的评论非常到点子上:Claude Max用户如果Agent能有效利用"睡眠"机制,同样的$200月费能多处理2-3倍的任务量。因为每轮对话不再被长上下文拖累,token消耗大幅下降。
更关键的是隐性收益:质量提升。上下文超过60%窗口后,模型定位关键信息的能力明显下降。有睡眠机制的Agent始终在"干净"的上下文中工作,回复准确率更高。
六、踩坑与排障
坑1:过度压缩导致信息丢失
症状:Agent"睡醒"后反而变蠢了——忘记了用户之前提到的关键偏好或约束。
根因:摘要prompt没有明确定义"不可丢失信息"清单,LLM自行判断哪些重要哪些不重要。
解决:在压缩prompt中加入explicit声明:
坑2:睡眠频率过高
症状:Agent反复进入睡眠状态,打断正常对话流。
根因:idle_threshold设置太短(如2分钟),或没有检查"是否还有待完成任务"。
解决:
- idle_threshold至少10分钟
- 加入min_active_time检查(至少活跃5分钟后才允许睡眠)
- 检查task_queue是否为空——有待完成任务绝不睡眠
坑3:记忆膨胀
症状:Agent运行数周后,L2记忆文件从几KB膨胀到几十MB,启动时加载缓慢。
根因:没有给L2记忆设置上限和归档机制。
解决:
- 设置max_memories上限(推荐50-100条)
- 超出部分自动归档到冷存储
- 启动时只加载最近N条(N≤5),不加载全部历史
- 提供"深度搜索"功能:用户明确要求时可以检索归档记忆
坑4:向量检索的相似度陷阱
症状:向量检索返回的"相似历史"实际上毫无关联。
根因:Embedding模型对领域术语的语义理解不准确。
解决:
- 用text-embedding-3-large(比small版本语义区分度更好)
- 加入关键词过滤:先用BM25做关键词匹配筛选,再用向量做精排
- 设置相似度阈值(如cosine similarity > 0.75),低于阈值的不返回
七、常见问题(FAQ)
Q:我的Agent才跑几十轮对话,需要"睡眠"吗?
A:对话少于20轮时收益不明显。但如果你的Agent每天处理50+轮对话,或单次会话超过10K token,"睡眠"机制能显著降低API成本(30-60%)并提升回复质量。判断标准:如果你的Agent已经遇到了上下文窗口不够用或API账单过高的问题,就是引入"睡眠"机制的时机。
Q:Anthropic Dreams和论文的"睡眠"是一回事吗?
A:核心思想完全一致——都是在Agent空闲时将上下文压缩为可复用的记忆。但实现路径不同。论文走的是底层架构路线(修改SSM-Attention混合模型,在推理层面实现快速权重更新),Anthropic走的是应用层路线(后台扫描对话记录+记忆库更新)。对于普通开发者,应用层方案更实际、成本更低。论文方案需要模型架构级别的改动。
Q:开源方案有哪些可以参考?
A:Letta团队的"sleep-time compute"论文(arxiv 2504.13171)提供了开源参考实现——核心思路是让模型在用户提问前就预计算可能需要的中间结果。工程层面,Mem0(github.com/mem0ai/mem0)提供了开箱即用的Agent记忆管理,LangChain的ConversationSummaryMemory也提供了可组合的上下文摘要组件。
Q:睡眠期间Agent还能响应请求吗?
A:这取决于你的架构设计。论文的方案是"离线睡眠"(前台不工作,专注消化),Anthropic Dreams是"后台睡眠"(前台继续响应请求,后台独立进程做复盘)。推荐采用后台模式——用户体验完全不受影响。如果资源有限只能做离线睡眠,建议在明确的"空闲时段"触发(如夜间或用户明确表示"暂时不需要你")。
Q:会不会出现"噩梦"——Agent在睡眠中强化了错误模式?
A:这是真实风险,也是Anthropic设计"人工审核"选项的原因。如果你的Agent在某个领域出错率高,睡眠压缩可能会把错误当成"经验"固化。防护措施:①设置人工审核模式(确认后再生效)②在压缩prompt中加入"区分正确和错误"的指令③定期审查L2记忆库的内容质量。
*本文参考来源:* *Language Models Need Sleep (arxiv:2605.26099),Hacker News讨论 (107pts/80 comments)* *Anthropic Claude Managed Agents Dreams功能 (2026年5月7日发布)* *Claude Code with Claude开发者大会 (2026年5月14日,旧金山)* *Letta Team Sleep-Time Compute (arxiv:2504.13171)* *HN社区讨论中的三层记忆架构 (user: rahen)*
本文由AI辅助创作,经人工审核编辑发布
#AI创业 #Agent工坊 #LLM #上下文管理 #一人公司
本文由AI辅助创作,经人工审核编辑发布