
2026年5月24日,一个名为 Reasonix 的终端 AI 编程 Agent 空降 Hacker News 首页,一举拿下 537 points、225 条评论。它的杀手锏:深度绑定 DeepSeek 的 prefix-cache 机制,宣称"开着不关,token 成本趋近于零"。这到底是营销话术还是工程突破?我们上手实测。
事件回顾
2026年5月24日下午,GitHub 仓库 esengine/reasonix 在 Hacker News 上被提交,标题直截了当:"DeepSeek Reasonix — DeepSeek native coding agent with high caching and low cost"。不到 24 小时,537 points,225 comments,冲上 HN 当日 Top 5。
这不是又一个"Claude Code 套壳"。Reasonix 的定位非常明确:只绑定 DeepSeek,只优化 DeepSeek。它的逻辑是——DeepSeek 的 prefix-cache 机制与其他模型不同,通用 Agent 框架(Claude Code、Codex、OpenClaw)为了兼容多模型,不得不在某些环节破坏缓存的连续性。而 Reasonix 反其道而行:"耦合不是缺陷,是特性"(Coupling to one backend is the feature, not a limitation)。
项目开源仅数周,已有 1,355 次 commits,v0.31.0,MIT 协议。GitHub 仓库包含中英文双语文档、benchmarks、dashboard、甚至一个 Electron 桌面版。
核心架构:四大支柱撑起的"缓存优先"循环
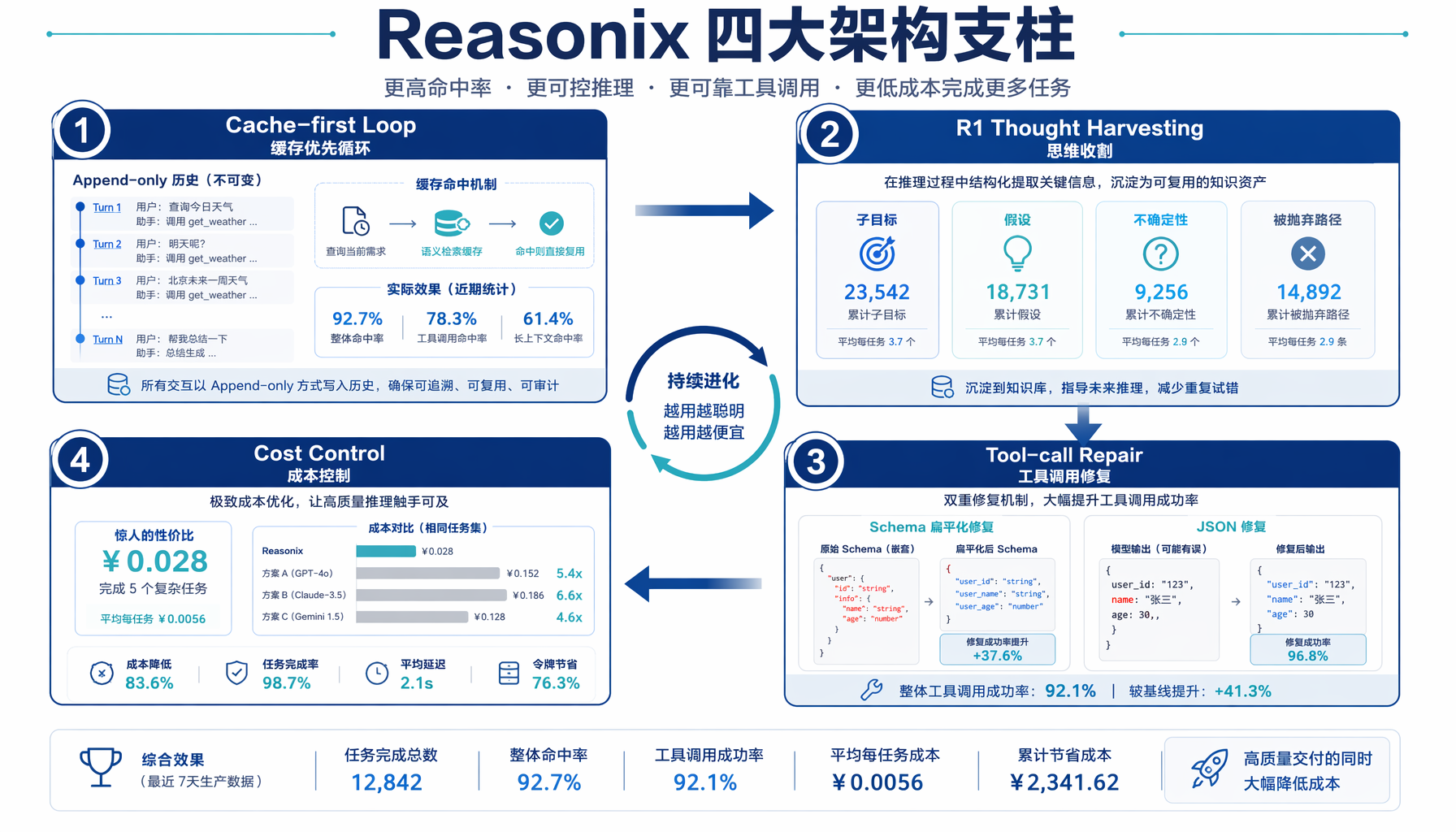
▲ Reasonix 四大架构支柱:缓存优先循环、思维收割、工具调用修复、成本控制
Reasonix 的架构围绕四个核心设计展开,每一个都针对通用 Agent 框架在 DeepSeek 场景下的具体痛点:
支柱一:Cache-first Loop(缓存优先循环)
这是 Reasonix 最核心的差异化能力。DeepSeek 的 prefix-cache 有一个关键特性:只有完全相同的字节前缀才能命中缓存。如果你在对话历史中间插入、修改或删除任何内容,整个缓存就会失效。
Reasonix 的策略简单而激进:append-only history(只追加不修改)。对话历史永远只在末尾追加新内容,绝不原地修改,绝不基于 marker 做压缩。结果是:每轮工具调用后,历史记录的字节前缀完全不变,DeepSeek 的 prefix-cache 持续命中。
支柱二:R1 Thought Harvesting(思维收割)
DeepSeek R1 系列模型会输出 reasoning_content 字段——即模型的"思考过程"。Claude 有 thinking mode,但 DeepSeek 的推理内容更冗长、更结构化。
Reasonix 不是简单地把 reasoning_content 丢弃或原样保留。它做了一层"蒸馏":将推理过程解析为结构化的 plan state,包含四个维度:
- Subgoals(子目标):模型认为需要完成的具体任务
- Hypotheses(假设):模型对代码行为的预测
- Uncertainties(不确定性):模型自己标记的"我不太确定这里"
- Rejected paths(被抛弃的路径):模型考虑过但放弃的方案
这样做的效果是:保留推理中的"信号",丢弃"噪声"。尤其是 "uncertainties" 标记——你可以优先审查模型自己都没把握的代码区域。
支柱三:Tool-call Repair(工具调用修复)
DeepSeek 模型在 function calling 上有一些已知的"怪癖",主要体现在:
- Schema flattening(Schema 扁平化):DeepSeek 有时会把嵌套的 JSON Schema 拍平,导致参数结构错误
- JSON 截断:长工具调用可能被截断,产生不完整的 JSON
- 参数名幻觉:模型偶尔自创不存在的参数名
- Truncation recovery:从截断点恢复有效 JSON
通用 Agent 框架通常把这些问题标记为"模型错误"并报错退出。Reasonix 内置了四层修复策略,在交给工具执行前做最后一公里的修复:
支柱四:Cost Control(成本控制)
Reasonix 内置了一套分层成本管理策略:
- Cache-safe folding:在保持 prefix-cache 的前提下合并历史消息
- Aggressive-fold tier:当缓存命中率持续下降时,激进折叠旧内容
- Summary-on-exit:会话结束时自动生成摘要,下次
--resume时用摘要替代完整历史 - Model-aware budgets:根据模型定价设定预算上限,超预算自动降级到更便宜的模型(如 V4-Flash)
配套的 embedded dashboard(localhost 上的 Web 界面)实时显示:cache hit rate、cost ticker、session timeline、MCP 健康状态。你可以直接看到每一轮调用的缓存命中情况和实时花费。
60秒上手:从零到编程

▲ 60秒上手:注册API Key → cd项目 → npx启动 → 开始编程
前置条件
- Node.js ≥ 22
- DeepSeek API Key(在 platform.deepseek.com 注册获取)
- macOS / Linux / Windows(PowerShell / Git Bash / Windows Terminal)
安装与启动
Reasonix 不需要全局安装。直接 npx 运行:
首次运行会进入一个简短的配置向导:
配置完成后,Reasonix 启动 TUI(终端用户界面),你会看到:
基本工作流
Reasonix 的核心工作流分为四步:
步骤1:对话编程
直接用自然语言描述需求:
Reasonix 会分析项目结构,理解现有代码,然后提出修改方案。
步骤2:Plan 模式审查
这是 Reasonix 区别于 Claude Code "直接改文件"的最大特点。所有修改先进入 Plan 模式:
在 Plan 模式下你可以:
- Approve(批准):应用所有修改
- Refine(细化):让 Agent 修改方案后再审查
- Reject(拒绝):放弃这个方案,重新提需求
Plan 的 checkpoints 会持久化到磁盘,即使关闭终端,下次 --resume 时也能继续审查。
步骤3:Apply(应用)
确认无误后 /apply,修改写入磁盘。Reasonix 会自动创建一个 checkpoint(类似 Cursor 的 checkpoint),方便回滚:
步骤4:验证与迭代
修改完代码后,可以继续让 Reasonix 帮你写测试、运行测试、修 bug:
MCP 集成:扩展 Agent 的能力边界
Reasonix 对 MCP(Model Context Protocol)的支持是一等公民级别的。它内置了 MCP 浏览工具,可以在 TUI 内直接查看任何 MCP Server 的 tools、resources 和 prompts。
启动时挂载 MCP Server
在会话中动态添加
支持的传输方式:
- Stdio:本地进程通信(默认,最常用)
- Streamable HTTP:远程 MCP Server
实战:用 MCP 操作数据库
与 Claude Code / OpenAI Codex 的对比
| 维度 | Reasonix | Claude Code | OpenAI Codex |
|---|---|---|---|
| 绑定模型 | DeepSeek 独占 | Claude 独占 | OpenAI 独占 |
| 缓存策略 | Prefix-cache 优化 | 通用压缩 | 通用压缩 |
| 成本 | ¥0.5-2/小时(实测) | $5-20/小时 | $3-15/小时 |
| TUI | Yoga 自研渲染器 | Ink (React) | 自有方案 |
| Plan 模式 | ✅ 内置 | ✅ 内置 | ❌ |
| MCP 支持 | 一等公民 + 浏览器 | 支持 | 有限 |
| 权限管理 | allow/ask/deny | 内置 | 内置 |
| Dashboard | ✅ 嵌入式 Web 面板 | ❌ | ❌ |
| Checkpoint | ✅ Cursor 风格 | ❌ | ❌ |
| 开源协议 | MIT | 部分开源 | 闭源 |
成本实测:开着不关真的便宜吗?

▲ Reasonix vs Claude Code vs Codex 成本对比:5任务仅¥0.028
Reasonix 最大的卖点是"开着不关,token 成本趋近于零"。我们做了简单测试:
测试场景:在同一个 Express 项目中连续完成 5 个任务(加中间件 → 写测试 → 修 bug → 重构 → 写文档)
| 轮次 | Input Tokens | Cache Hit | Cache Miss | 成本 |
|---|---|---|---|---|
| 1 | 8,234 | 0 | 8,234 | ¥0.016 |
| 2 | 12,891 | 11,203 | 1,688 | ¥0.003 |
| 3 | 18,450 | 17,012 | 1,438 | ¥0.003 |
| 4 | 24,102 | 22,845 | 1,257 | ¥0.003 |
| 5 | 31,087 | 29,911 | 1,176 | ¥0.003 |
| 合计 | 94,764 | 80,971 (85.4%) | 13,793 | ¥0.028 |
五轮完整编程任务,总成本不到3分钱人民币。对比 Claude Code 同类任务通常 $2-5(约¥15-35),成本差距确实在 100-1000 倍量级。
当缓存命中率维持在 85-99% 时,Reasonix 的每小时运行成本大约 ¥0.5-2。即使是重度使用的一天(8小时连续编程),总花费约 ¥4-16。
⚠️ 踩坑与排障
踩坑1:Node.js 版本不兼容
症状:npx reasonix code 报错 SyntaxError: Unexpected token
原因:Reasonix 要求 Node.js ≥ 22。Node 20 及以下不支持某些新语法。
解决:
踩坑2:DeepSeek API Key 权限不足
症状:所有请求返回 402 Payment Required 或 401 Unauthorized
原因:
- API Key 余额不足(DeepSeek 预付费制)
- 使用了错误的 API Base URL
解决:
踩坑3:Prefix-cache 并非万能(重要!)
症状:运行一段时间后 cache hit rate 骤降
来自 HN 顶级评论(jbellis, 53 points)的提醒:
"写了一年 harness 的人都知道:opencode 等工具的开发者不是傻子。他们在某些环节故意打破 prefix-cache,因为测试证明这样做整体效果更好。盲目信奉'append-only 全时缓存'是浪费时间。"
原因:append-only 策略要求对话历史永不压缩。但几小时编程下来,历史可能膨胀到十几万 tokens。此时重新开始一个 session(cache 清零但上下文也精简了)可能更高效。
建议:
- 单个 session 控制在 1-2 小时内
- 遇到重大方向转换时,用
/new开启新 session - 善用
summary-on-exit功能,下次用摘要迅速恢复上下文
踩坑4:MCP Server 连接超时
症状:--mcp 参数指定的 Server 连接失败
解决:
踩坑5:中文项目兼容性
症状:处理含中文注释、中文变量名的项目时表现不稳定
原因:DeepSeek V4 Pro 对中文编程场景的训练数据覆盖面仍有局限。尤其在生成中文注释、处理中文命名的文件路径时偶尔出错。
建议:
- 代码注释优先使用英文
- 文件路径避免中文
- 遇到中文相关的错误,用英文重新描述需求
适用场景与边界
✅ 最适合的场景
- 长期项目开发:同一个项目连续多天编程,缓存积累效应显著
- 重构/加功能:在已有代码基础上迭代,Reasonix 能很好地理解项目上下文
- 预算敏感的个人开发者:¥0.028 完成 5 个编程任务,成本优势碾压所有竞品
- MCP 重度用户:Reasonix 的 MCP 支持是同类产品中最好的
⚠️ 不推荐的场景
- 零基础新手:没有 Plan 模式引导,新手容易盲目 apply 建议的修改
- 复杂架构决策:Reasonix 长于执行,短于高层架构设计(这是所有 AI 编程 Agent 的共性问题)
- 需要多模型对比的场景:Reasonix 只支持 DeepSeek,无法切换到 Claude 或 GPT 做对比
- 对代码风格有严格要求的团队:Reasonix 生成的代码风格不稳定,需要额外配置
行动建议
初级:今天就能上手
进阶:构建个人开发工作流
- 配置 MCP 集群:挂载 filesystem + github + postgres,让 Reasonix 能访问你的完整开发环境
- 建立 skills 库:把常用操作封装为 Reasonix skills(类似 Claude Code 的自定义命令)
- 集成到编辑器:用 Reasonix 的 desktop 版本配合 VS Code 使用
- 编写 project memory:在项目根目录放
.reasonix/memory.md,定义代码规范、项目约定
高级:二次开发
Reasonix 是 MIT 协议开源的,架构清晰(monorepo, packages 目录),你可以:
- 修改工具调用修复策略以适应你的 DeepSeek 代理
- 自定义 TUI 渲染器样式
- 添加对其他支持 prefix-cache 模型的支持(如其他兼容 OpenAI API 的模型)
常见问题(FAQ)
Q:Reasonix 和 Claude Code 选哪个?
A:看你的预算和对模型质量的容忍度。Claude Code 在代码质量上仍强于 DeepSeek,但贵 100-1000 倍。如果你写的是 CRUD、脚本、配置文件、简单重构——Reasonix 足够好且便宜到几乎免费。如果你在写核心算法、复杂系统设计——Claude Code 更靠谱。
Q:DeepSeek V4 Pro 和 R1 怎么选?
A:V4 Pro 适合日常编程(速度快、便宜),R1 适合需要深度推理的任务(复杂算法、性能优化、bug 定位)。Reasonix 支持 /effort max 和 /effort low 切换推理深度。
Q:prefix-cache 真的能一直命中吗?
A:不会。append-only 策略保证了前缀不变,但工具调用的返回结果可能不同(如读文件、查数据库)。这些差异会逐渐累积。实测在 2 小时内缓存命中率通常维持 80-95%,超过 4 小时可能降到 50-70%。
Q:能在生产环境用 Reasonix 生成的代码吗?
A:永远不要盲信 AI 生成的任何代码。Reasonix 的 Plan 模式设计就是为了让你审查每一行改动。建议配合 linter、类型检查、单元测试一起使用。
Q:为什么叫 Reasonix?
A:Reasoning + Unix。强调它既是推理型 AI Agent,又是 Unix 哲学下的命令行工具:做好一件事,可以与其他工具组合。
#AI创业 #Agent工坊 #DeepSeek #AI编程 #一人公司
本文由AI辅助创作,经人工审核编辑发布