
不必依赖第三方舆情工具,用Hermes Agent的cron + web_search + web_extract 三件套,30分钟搭建属于你自己的7×24小时AI热点雷达。
前言
AI内容创业者的核心竞争力之一,就是信息差——谁能第一时间捕捉行业动态,谁就能抢占内容先机。市面上有各种舆情监控SaaS(Meltwater、Brandwatch),但对于一人公司或小团队来说,动辄每月$500-$2000的费用实在不友好。
好消息是:如果你已经在使用 Hermes Agent,你其实已经有了搭建完整热点监控系统所需的一切基础设施。它的 cron、web_search、web_extract 三个内置工具,结合起来就是一台7×24小时运转的内容雷达。
本文带你从零搭建一套生产级热点监控流水线,整个过程不需要写一行代码——全部通过 Hermes Agent 的 skill 配置文件完成。
你将学到
- 如何用 cron 配置定时扫描任务
- 如何用 web_search 多关键词交叉搜索
- 如何用 web_extract 深度提取文章正文
- 如何设置去重逻辑,避免重复发现
- 如何自动生成草稿并推送到草稿箱
- 常见踩坑与排障方案
1.1 cron — 定时触发器
Hermes Agent 的 cron 系统支持在指定时间间隔自动执行 skill。配置文件位于 ~/.hermes/profiles/default/cron/。
关键参数:
schedule:标准 crontab 格式(分 时 日 月 周)skill:要触发的 skill 文件名(不含.md扩展名)enabled:true/false开关,不需要注释掉整段配置
生产建议:
- 高频话题(AI融资、新品发布)→ 每15分钟
- 中频话题(行业报告、竞品动态)→ 每2小时
- 低频话题(政策法规、学术论文)→ 每天1次
1.2 web_search — 搜索引擎
web_search 是 Hermes Agent 内置的搜索工具,支持多后端(Tavily、博查、DuckDuckGo)。
搜索效率技巧:
- 用
site:限定来源(知乎、CSDN、GitHub) - 用时间限定符避免旧闻(加年份 "2026")
- 中英文分开搜索(中文社区和英文社区信息不同步)
- 产品名 + 竞品名组合搜索(如 "Hermes Agent OpenClaw 对比")
1.3 web_extract — 内容提取器
web_extract 从 URL 提取文章正文,自动转换为 Markdown 格式。
重要限制:
- 单次最多5个URL
- 超过5K字符的文章会智能摘要
- 超过2M字符的页面直接拒绝
- 中文站点(新浪、虎嗅、人民网移动端)可能返回空结果——需要先搜标题再取URL
在 ~/.hermes/profiles/default/skills/ 下创建 ai-hotspot-monitor.md:
去重逻辑的关键实现
去重是监控系统最容易出问题的地方。以下是经过生产验证的检查步骤:
真实教训:同一热点话题(如 OpenAI 发布新品)可能在 HN 热榜上持续显示数小时。如果前一个 cron cycle 已经写了草稿,后续 cycle 再次发现同一话题时必须跳过,否则会产生重复内容。
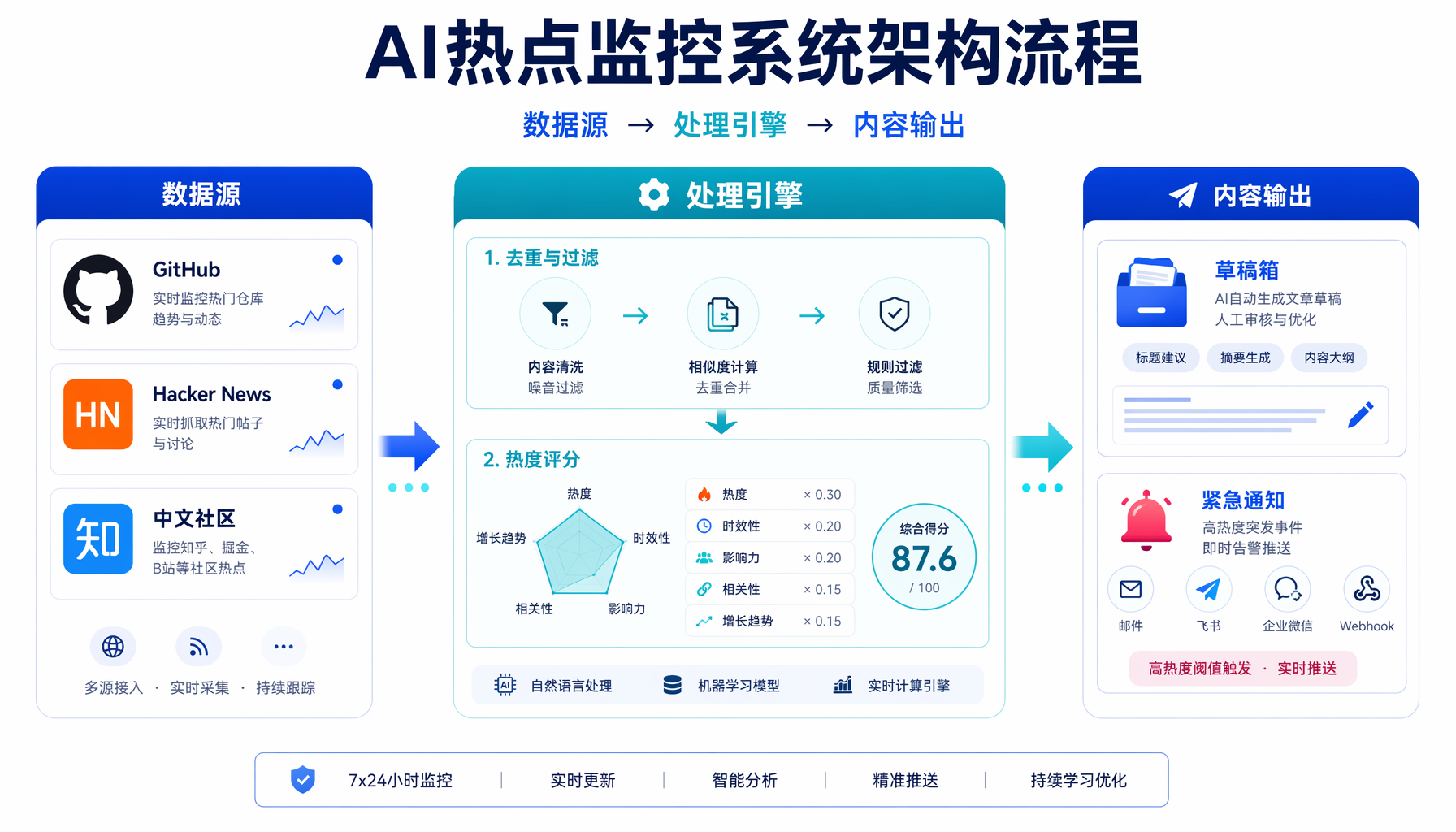
▲ 图1:AI热点监控系统三阶段架构 — 数据源→处理引擎→内容输出全流程
第三步:配置 Cron 定时任务

▲ 图2:Cron监控频率策略 — 不同监控对象的合理扫描间隔对比
在 ~/.hermes/profiles/default/cron/ 下创建 JSON 配置文件:
多个监控频率的最佳实践:
| 监控对象 | 频率 | 原因 |
|---|---|---|
| AI工具发布 | 15分钟 | GitHub release 随时可能发 |
| HN热榜扫描 | 30分钟 | 重大新闻5小时内上榜 |
| 中文社区 | 2小时 | 信息更新相对慢 |
| 竞品公众号 | 6小时 | 避免过度抓取 |
Cron Job 目录结构
第四步:配置告警与通知
监控系统不仅要"看到",还要"喊出声"。Hermes Agent 支持多层通知机制:
4.1 Cron 内嵌通知
4.2 重大新闻标记
在 skill 中设定触发条件:
4.3 静默模式
日常扫描不产生输出,只在有实质性发现时才报告:
第五步:实战案例 — 监控 Hermes Agent 最新版本
以下是一个专门监控 Hermes Agent GitHub releases 的完整配置:
Cron 配置
Skill 内容
curl -s " | python3 -c " import sys, json data = json.load(sys.stdin) for r in data: print(f'Version: {r[\"tag_name\"]}') print(f'Published: {r[\"published_at\"]}') print(f'Body: {r[\"body\"][:500]}') print('---') " cat /opt/hermes-home/projects/ai-neican/.latest-hermes-version 2>/dev/null || echo "none"常见踩坑与排障
坑1:Tavily API 返回 432 错误
现象:web_search 返回 `Client error '432' for url '
原因:Tavily API 配额耗尽或地区限制。
解决:
- 切换后端:
hermes config set web.backend bocha(使用博查) - 直接调 GitHub API(无需认证):
- 直接访问 HN 热榜页面:`
现象:对中文站点(新浪、虎嗅、人民网移动端)使用 web_extract 返回0字符。
原因:这些站点的移动端页面结构特殊,内容提取器无法识别。
解决:
- 用
web_search先搜文章标题,获取正确URL - 优先提取 PC 端URL(
www.开头) - 对于微信公众号文章,用
mp.weixin.qq.com的永久链接
坑3:跨日重复草稿
现象:同一热点话题生成了两篇草稿。
原因:前一个 cron cycle 已经发现并写了草稿,但后续 cycle 再次发现同一话题。
解决: 去重搜索范围要覆盖近2天的草稿,不只是当天:
坑4:搜索关键词效果差
现象:搜索结果零散,大量无关内容。
原因:关键词太宽泛或太冷门。
解决:
- 太宽泛:加限定词(
site:zhihu.com、2026、教程) - 太冷门:改用更通用的表述("AI Agent" 代替 "Hermes Agent 0.6.3")
- 组合搜索:产品名 + 功能关键词("Claude Code" + "MCP")
坑5:GitHub README 内容提取失败
现象:访问 GitHub README 页面返回结构元素但不含 Markdown 正文。
原因:browser_snapshot 只渲染页面结构,不显示 Markdown 渲染内容。
解决: 使用 GitHub 的 raw 地址或 API:
进阶:接入内容创作流水线

▲ 图3:热点综合评分模型 — 四维度加权决策树,触发深度分析/快讯/仅记录
当监控系统发现热点后,可以自动触发内容生成流水线:
自动化评分标准
给发现的热点打一个综合分,决定后续动作:
总结
用 Hermes Agent 搭建热点监控系统的核心优势:
- 零代码:全部通过 skill 配置文件完成,不需要写 Python/JS
- 零成本:使用内置工具,无需额外SaaS订阅
- 可定制:监控关键词、频率、触发动作完全自主控制
- 可扩展:发现热点后可自动接入内容生产、排版、发布流水线
下一步行动:
- 复制本文的 cron 配置模板,创建你的第一个监控任务
- 配置去重逻辑,避免重复发现
- 设置重大新闻告警阈值
- 逐步扩展监控关键词库
记住:信息差是AI内容创业的核心竞争力。你的热点雷达越灵敏,你的内容就越有先发优势。
#AI创业 #Agent工坊 #HermesAgent #热点监控 #一人公司 #内容创业
本文由AI辅助创作,经人工审核编辑发布