
学术论文揭示"约束衰减"现象:LLM编程Agent在无约束下表现优秀,但一旦加上数据库、ORM、架构模式等结构性要求,通过率平均暴跌30个百分点——Flask勉强能打,FastAPI和Django直接跪。
事件回顾
一篇题为《Constraint Decay: The Fragility of LLM Agents in Back End Code Generation》的论文本周登上Hacker News首页,拿下175个点赞和86条评论,在AI编程圈引发激烈讨论。
论文作者来自EURECOM和罗马第三大学,他们设计了一个系统性实验:固定统一的API契约,在80个从零搭建的后端项目和20个功能迭代任务中测试LLM编程Agent的表现。覆盖了Flask、FastAPI、Django、Express、NestJS、Spring Boot、Laravel和Ruby on Rails共8个主流Web框架。
核心发现触目惊心:当结构性约束(数据库schema、ORM映射、分层架构、中间件链)层层叠加时,最先进的AI编程Agent的断言通过率从基准线暴跌30个百分点。部分弱配置甚至趋近于零。
换句话说:让AI写一个"能跑就行"的Flask API,它可以写得很漂亮。但让它写一个严格遵守MVC分层、定义好Repository Pattern、配置好ORM关系的Django项目,它就开始胡编乱造了。
最脆弱的环节是数据层。论文指出,错误的查询组合和ORM运行时违规是失败的最主要根因——AI Agent生成的SQL JOIN逻辑经常张冠李戴,外键关联凭空捏造。
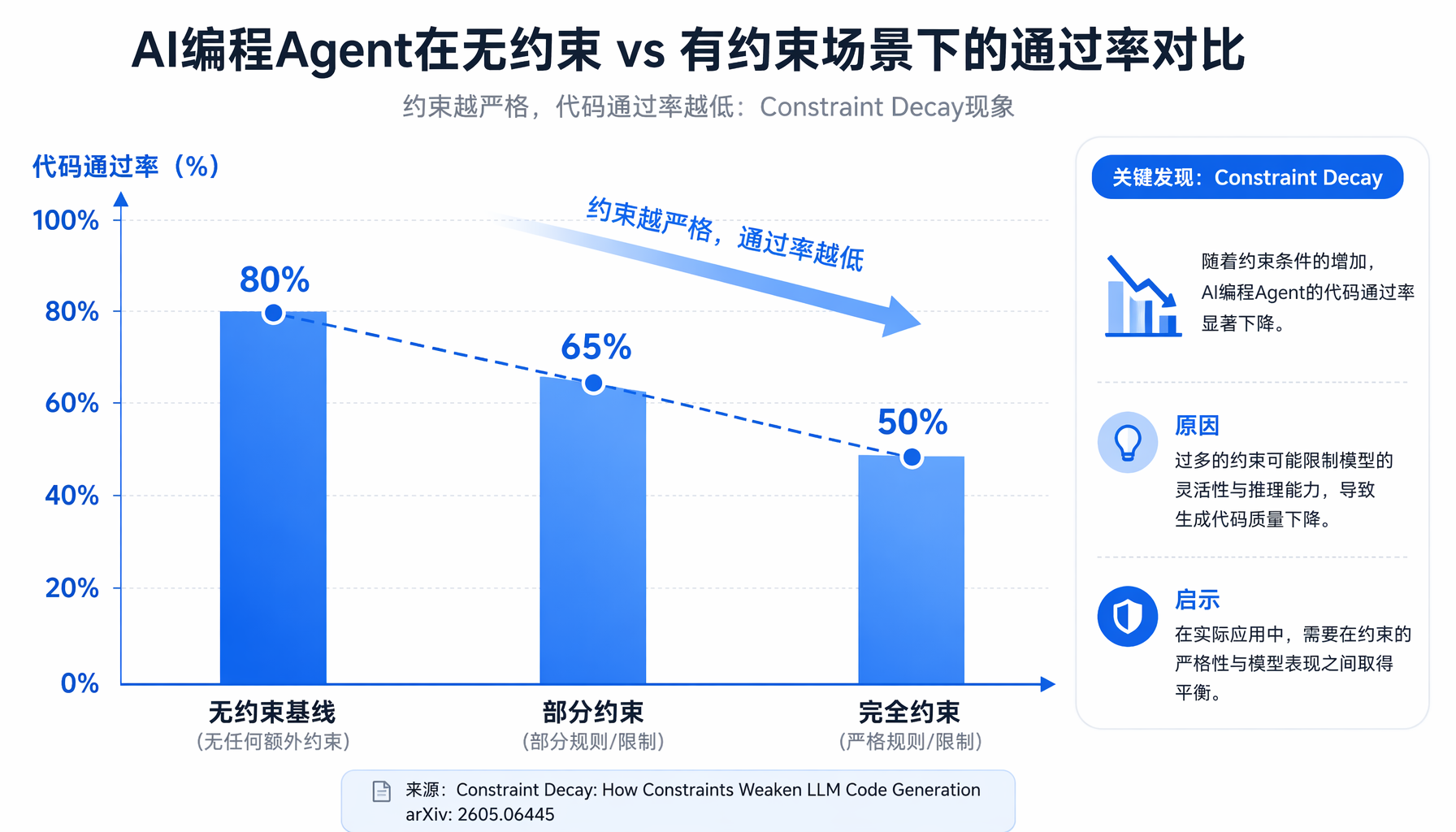
▲ 约束衰减现象:随着架构约束增加,AI编程Agent通过率断崖式下跌(来源:arxiv 2605.06445)
为什么重要
这不是一个"AI不行"的悲观故事,而是一个精准的使用边界地图。对于正在用Claude Code、Cursor、Codex、Reasonix等AI编程工具做产品的AI创业者来说,这篇论文提供了三个关键信号:
第一,原型阶段可以全速冲刺,但生产化必须踩刹车。 论文数据清晰表明:在"功能正确即可"的场景下(无约束基线),AI Agent的通过率可达80%以上。这正是绝大多数创业者在MVP阶段需要的——快速验证想法。但一旦进入"结构也要正确"的生产化阶段,通过率断崖式下跌。
第二,框架选择直接影响AI编程成功率。 Flask这类显式、最小化的框架(路由写在函数上,数据库操作直白可见)AI能驾驭。但FastAPI的依赖注入系统和Django的隐式约定(Model Meta、自动URL路由、Middleware栈)让AI晕头转向。如果你正在选技术栈且计划重度依赖AI编程,这个数据值得参考。
第三,"AI把指令当建议"不是你的幻觉,是系统性缺陷。 HN评论区一位工程师吐槽Claude Opus:"Instructions are merely suggestions"(指令不过是建议罢了)。另一位说Opus会"锚定"在它最初生成的架构上,即使你后来补充了新约束,它也会想方设法绕回去。论文从机制上验证了这种现象——这就是约束衰减的具象表现。
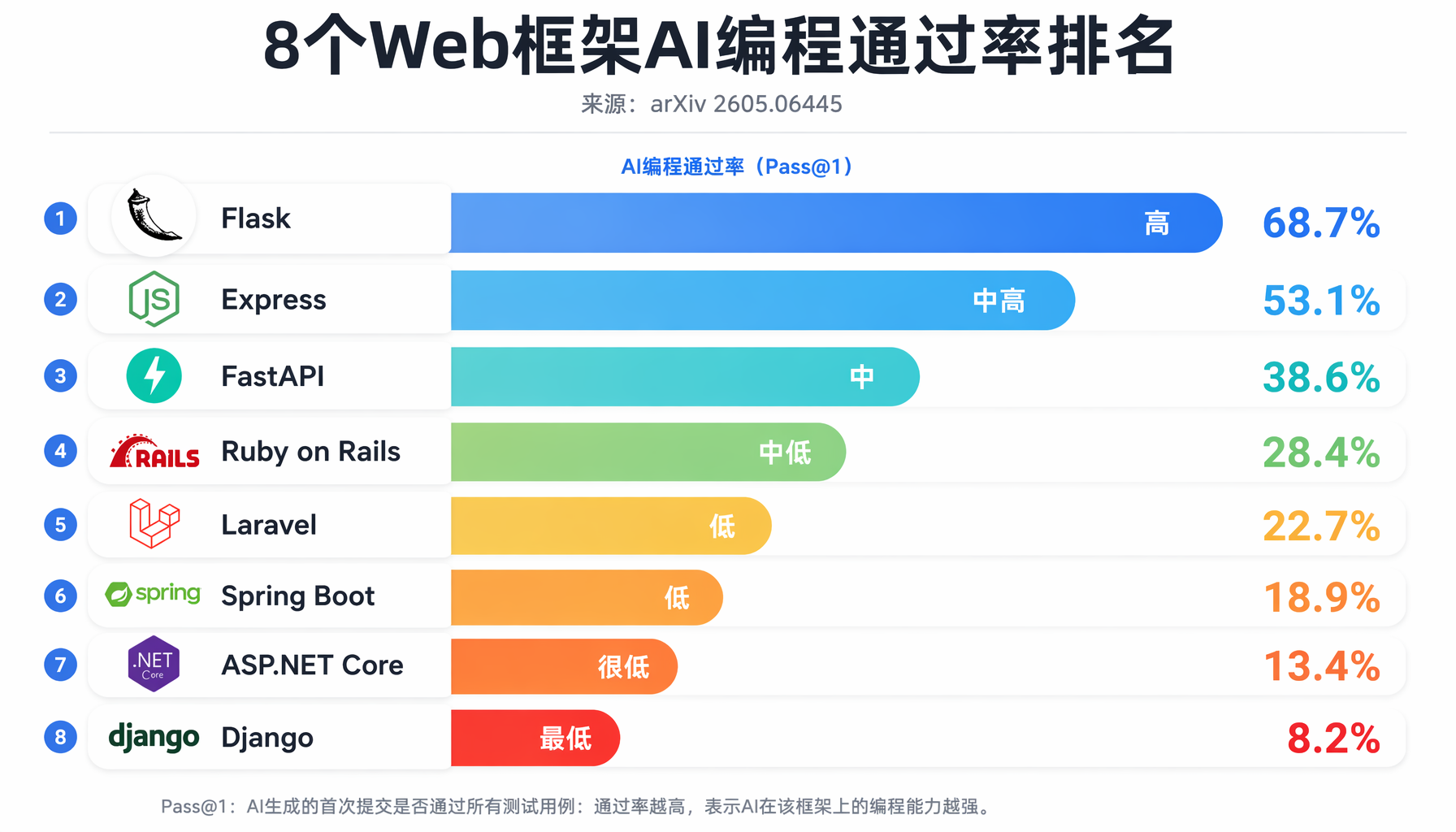
▲ 框架选择直接影响AI编程成功率:Flask/Express显式框架显著优于FastAPI/Django魔法框架(来源:arxiv 2605.06445)
我们能学到什么
1. 用"显式框架"而非"魔法框架"
如果你的团队正在用AI编程工具做主力开发,优先选择Flask、Express这类"所见即所得"的轻量框架。避免FastAPI的Depends()魔法和Django的隐式约定——它们让人类开发者效率高,却让AI Agent掉进结构陷阱。
一个实战建议:如果你确实需要用Django的生产力(Admin后台、ORM成熟度),那就把AI Agent的角色从"全栈写手"降级为"单文件助手"——让它写单个view或单个model,你来组装架构。
2. 给AI Agent装"护栏"——把约束显式化
论文的核心发现是:隐式约束(框架约定、设计模式)是AI的死穴,显式约束(接口契约、测试用例)AI能处理。所以:
- 用API契约锁定接口:先手写OpenAPI/Swagger spec,再让AI实现。论文中统一API契约的实验设置本身就是一种护栏。
- 用测试驱动AI:先写测试用例,再让AI写代码。让"能否通过测试"成为硬约束而非软建议。
- 结构约束写成代码检查:ESLint规则、mypy类型检查、架构lint(如dependency-cruiser)作为pre-commit hook。让AI的"结构错误"在提交前就被机器拦住。
3. 把数据库操作设为"高风险区"
论文明确指出数据层是失败主因。实用策略:
- 手写核心查询:涉及多表JOIN、事务、锁的SQL,不要交给AI。这些是业务逻辑的命脉。
- 用ORM的"显式模式":Django ORM用手写SQL + raw()而非让AI自由组合QuerySet链式调用。SQLAlchemy用Core模式而非ORM模式。
- 数据库迁移文件人工审核:AI生成迁移文件极易出现外键约束错误、索引遗漏、字段类型不当。
行动建议
- 今天就能做的事:在你当前AI编程工作流中加入一个"结构检查"环节——跑一遍mypy/pyright类型检查、ESLint规则、架构lint。如果AI生成的代码能通过这些检查,才算"结构正确"的及格线。
- 本周可以做的事:为新项目选择技术栈时,把"AI编程友好度"纳入评估维度。Flask > FastAPI > Django,Express > NestJS,这是论文给出的实证排序。
- 团队规范建议:制定"AI代码准入标准"——AI生成的代码至少要通过:类型检查、lint规则、架构约束检查、核心逻辑的单元测试。缺一不可进入code review。
- 心态调整:不要把AI编程Agent当作"全自动代码工厂"。把它当作一个能写80%功能代码但需要你手把手教架构的实习生——它能极大加速原型阶段,但生产化的最后一公里必须人工把关。
一个值得关注的视角
HN评论区有一条被忽略的洞见:"Even the strongest frontier model they used — GPT 5.2 — I would consider barely usable for agentic programming."
这位评论者认为模型能力还在快速进化中——GPT 5.2是2025年12月的模型,距今不过半年,但已经有Claude Opus 4.5、GPT-5.5、DeepSeek V4等更强的模型出现。论文的实验结果可能已经是"旧天花板"了。
但也有人反驳:约束衰减不是智商问题,是目标函数冲突问题——当AI同时被要求"功能正确"和"结构合规"时,它在优化两个矛盾的目标。这不是模型变大就能解决的,可能需要新范式的训练方法。
无论你站哪边,有一点是确定的:在AI编程工具被吹上天的2026年,这篇论文是少有的严谨提醒——AI不是银弹,至少在需要结构纪律的后端开发中还不是。
#AI创业 #AI编程 #Agent工具 #一人公司
本文由AI辅助创作,经人工审核编辑发布