
微软内部取消Claude Code授权、Uber开年4个月烧完全年AI预算、英伟达VP亲口承认"算力成本远超员工薪资"——当AI巨头的财务遮羞布被一张一张撕开,AI创业者真正需要问的问题是:这些钱到底烧在了哪里?而我该怎么花?
事件回顾
5月22日,Fortune发表了一篇引爆Hacker News的报道:微软已经开始大面积取消内部Claude Code授权,转而推动工程师使用自家的GitHub Copilot CLI——而这距离微软首次向数千名开发者、项目经理和设计师开放Claude Code使用权,仅仅过了6个月。
The Verge的消息源进一步确认,取消Claude Code授权并非因为Anthropic的工具不好用。恰恰相反,Claude Code在微软内部流行得太快了——快到让管理层意识到,放任员工自由使用外部AI编程工具的成本正在失控。
但微软并非孤例。同一天,The Information披露,Uber的CTO Praveen Neppalli Naga在内部坦言:公司2026全年的AI编码工具预算,在4个月内就被烧光了。更要命的是,Uber此前还通过内部排行榜——按团队AI工具使用量排名——来激励员工多用AI。
两条新闻在Hacker News上分别获得220分和247分,合计超过250条评论。而引爆HN情绪的,其实还有第三个数据源。
核心数据:$1.4万亿 vs $7180亿,谁在赚钱?
独立开发者Michael Tan-Sikorski建立了一个名为Is AI Profitable Yet?的网站,追踪所有主要AI公司的累计投入与收入。截至2026年5月,数据触目惊心:
| 公司 | 累计AI投入 | 累计AI收入 | 净盈亏 |
|---|---|---|---|
| Amazon | $3130亿 | $400亿 | -$2730亿 |
| Alphabet(Google) | $2870亿 | $600亿 | -$2270亿 |
| Meta | $2300亿 | $30亿 | -$2270亿 |
| Microsoft | $2660亿 | $610亿 | -$2050亿 |
| OpenAI | $550亿 | $280亿 | -$270亿 |
| Anthropic | $330亿 | $175亿 | -$155亿 |
| NVIDIA | $2250亿 | $4780亿 | +$2530亿 |
全场唯一的赢家,是卖铲子的。
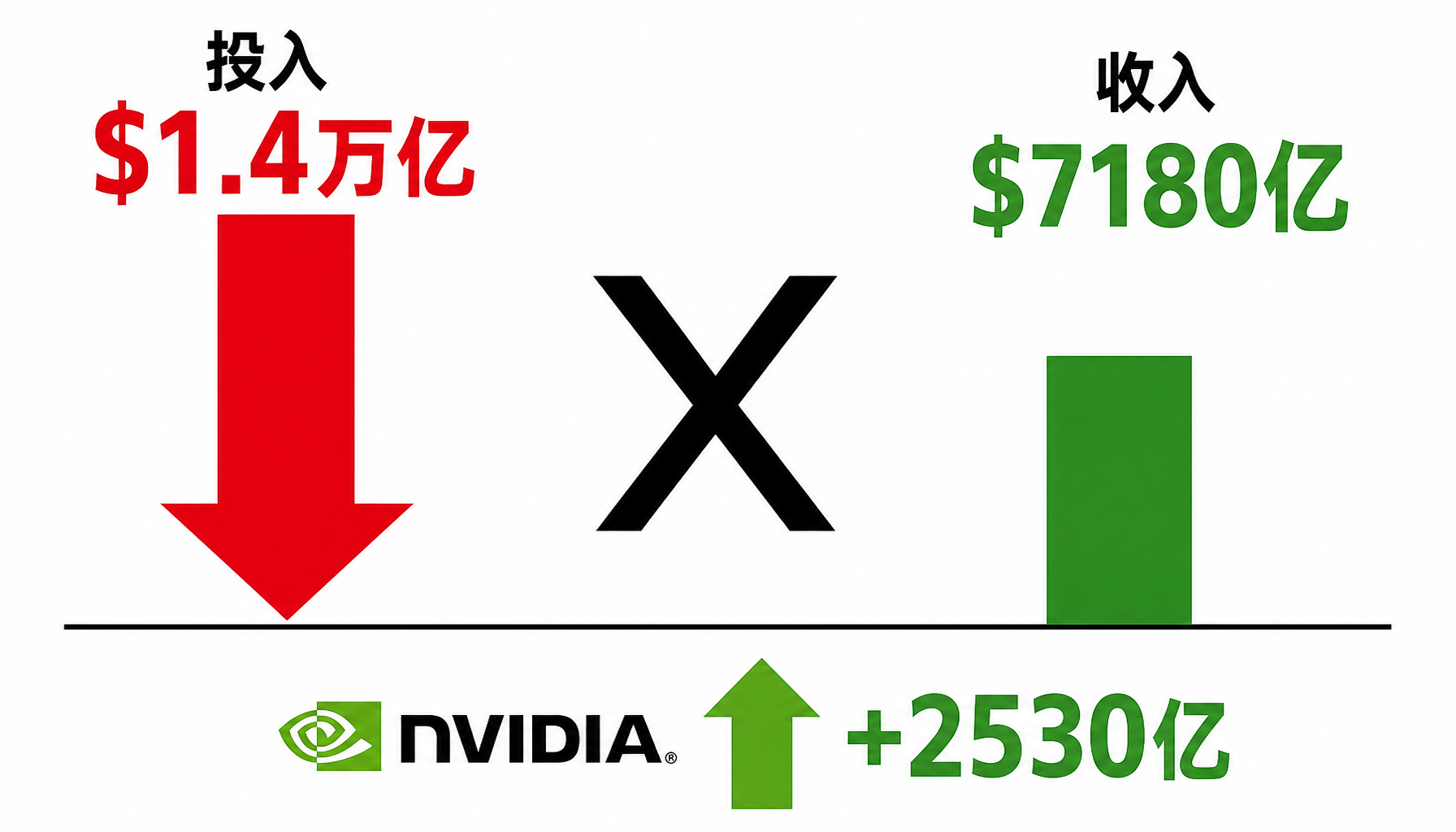
▲ 图:$1.4万亿AI投入中,10家公司仅NVIDIA盈利+2530亿。数据来源:Isaiprofitable.com(2026年5月)
这组数据的震撼之处不在于数字本身——科技巨头的资本开支历来惊人——而在于这些投入超过了历史上任何单一技术周期的资本密集度。作为对比:美国阿波罗登月计划的总花费(经通胀调整)约为$2500亿。也就是说,Amazon一家在AI上的投入就已经超过了一次登月。
深层分析:AI成本悖论是怎么形成的?
悖论一:Token越便宜,账单越大
这是一个经典的Jevons悖论在AI领域的重演。
过去两年,AI推理成本下降了超过90%——GPT-4级别的token价格从$30/百万token跌至不到$2/百万token。按照直觉,成本下降应该让整体开支减少。但实际情况恰恰相反:成本下降 → 使用量爆炸 → 总账单暴涨。
Uber内部排行榜驱动的"Tokenmaxxing"(刷token用量)文化,就是这个悖论的最佳注脚。当KPI从"产出"变成"AI使用量"时,工程师会自然地找到最大化token消耗的方式——生成冗长文档、用AI美化每一封Slack消息、要求Claude Code反复重写已经能工作的代码。
一位HN评论者精准总结道:"烧token就像往火炉里扔美元。Token使用量根本不是生产力的好指标。问题在于,没有人真正搞清楚如何衡量高效的AI参与度。"

▲ 图:Jevons悖论在AI领域的重演——Token价格下降90%,但总使用量爆炸增长,最终导致总账单暴涨
悖论二:当前AI价格是亏本买卖
HN评论区的另一个共识:我们今天使用AI支付的价格,不是真实成本。
Anthropic和OpenAI每处理一个token都在亏损——它们依靠风投资金和战略投资(微软投Anthropic $50亿、亚马逊投Anthropic $80亿)来补贴推理成本。这是一种经典的"先亏本获客、后提价收割"策略。
正如一位评论者所言:"如果你在使用AI,你现在没有支付真实成本,因为我们还处在'低价拉新'阶段。一旦垄断地位确立,你的月费会翻三倍。"
悖论三:最大金主正在撤退
微软取消Claude Code授权的深层含义被许多人忽略了:这是AI最大金主在发出"成本不可持续"的信号。
微软不仅是OpenAI的最大投资者(已投入约$130亿),也是Anthropic的重要战略合作伙伴(Foundry协议承诺投入$50亿)。当这样一家公司开始收缩内部AI工具支出时,它传递的信息是清楚无误的:即使对于一家市值$3万亿的科技巨头来说,当前AI工具的ROI也算不过账来。
英伟达应用深度学习VP Bryan Catanzaro在4月接受Axios采访时直言不讳:"对我的团队来说,算力成本远超员工的成本。"请注意,这话出自英伟达高管之口——全世界靠AI赚钱最多的公司的VP。
对AI创业者的三条启示
启示一:区分"AI支出"和"AI投资"
大厂烧钱和创业公司花钱是两码事。
Meta的$2300亿AI投入中,大头是数据中心建设、GPU采购和基础设施——这些是只有Meta级别公司才需要承担的沉没成本。作为AI创业者,你的成本结构完全不同:你使用现有API、部署开源模型、或者按量付费。
关键问题不是"AI贵不贵",而是"你花的每一块钱AI成本,是否产出了可衡量的业务价值"。
Uber的反面教材告诉我们:把AI使用量设为KPI是灾难。正确做法是:为每个AI使用场景设定明确的产出指标(如"用AI生成的代码减少了多少人工review时间"、"用AI处理的客服工单一次解决率是多少"),然后逆向计算合理的AI预算。
启示二:DeepSeek的效率革命是真实存在的
ISAiProfitable.com的数据揭示了一个被西方媒体忽视的事实:DeepSeek的投入产出比远超所有西方实验室。
DeepSeek累计投入仅$3亿,而Anthropic是$330亿——相差100倍。但DeepSeek产出的模型(DeepSeek-V3、R1等)在某些基准测试中已接近或达到Claude的水平。对于一个AI创业者来说,这意味着你的工具链不一定需要绑定最贵的模型。
实操建议:
- 编码任务:DeepSeek-V3/Coder + Claude Code(按需切换)
- 内容创作:Gemini Flash(极低成本) + Claude(高难度任务)
- 推理任务:DeepSeek-R1(开源可控)
- 不要所有任务都用最新最强模型——这是Uber式的"Tokenmaxxing"
启示三:算力成本曲线正在陡降,现在布局才划算
虽然当前AI不赚钱,但两条曲线正在朝着对创业者有利的方向移动:
- 硬件成本曲线:Taalas等公司已经在做专用推理芯片,Llama 3.1 8B推理速度达到14,000+ TPS。专用AI芯片一旦规模化,推理成本将再降一个数量级。
- 模型效率曲线:2024年到2026年,同等能力的模型推理成本下降了90%以上。这个趋势不会停止。
这意味着:今天看起来不划算的AI应用场景,6个月后可能就划算了。 如果你现在围绕"高成本模型"设计产品,明年推理成本下降时你就是率先吃到红利的人。
行动建议
- 立即审计你的AI工具支出:翻一翻API账单,看看哪些调用是真正产生价值的,哪些是"Tokenmaxxing"。Uber在4个月内烧光全年预算的教训,不该由你重复。
- 建立多模型路由策略:不是所有任务都需要Opus或GPT-5.5。为你的产品设计一个模型路由器——简单任务走便宜模型,复杂任务走强模型。这是当前AI创业者的基本操作。
- 关注专用AI芯片公司:Taalas、Groq、Cerebras等专用推理芯片公司一旦规模化供货,将是整个行业的成本拐点。保持关注,不要锁定在昂贵的通用GPU方案上。
- 把AI当成"实习生"而非"员工":当前AI最适合的不是替代全职员工,而是做那些"需要做但没人有时间做"的事——文档整理、初步代码框架、数据清洗、竞品分析初稿。把这些任务交给AI,把人的时间留给需要判断力和创造力的工作。
- 警惕被"AI必须全面落地"的FOMO绑架:微软砍Claude Code的底层逻辑是"我们自家的Copilot更便宜"——而不是"AI不值得用"。你的判断标准也应该是:在具体场景下,AI是否比替方案更快/更便宜/更好? 如果三个答案都是否,就不要用。
本文由AI辅助创作,经人工审核编辑发布