
5月22日,DeepSeek更新API定价页,V4 Pro的75%促销折扣在5月31日后不再结束——直接锁定为原价的1/4。输入降至$0.435/百万token、输出$0.87/百万token,加上1M上下文窗口和Claude Code原生兼容,这是2026年迄今对AI编程成本格局最猛烈的一击。
事件回顾
5月22日,DeepSeek在其API官方定价页面悄然更新了一条脚注:V4 Pro模型的75%折扣促销将在2026年5月31日15:59 UTC正式结束,但结束后价格将"正式调整为原价的1/4"。换句话说,这个从4月底启动、原定5月5日截止、后被延长到5月31日的促销价,现在变成了永久定价。
消息在Hacker News上迅速发酵,24小时内获得316个推荐和183条评论,登上首页。
这不是一个普通的降价公告。DeepSeek V4 Pro的"永久定价"意味着:1M token输入从$1.74降至$0.435,输出从$3.48降至$0.87。加上此前已生效的缓存命中价(输入缓存命中仅$0.003625/百万token),一套完整的低成本策略已经成形。
与此同时,V4 Flash版本保持$0.14/$0.28的定价(缓存命中$0.0028/百万token),两个模型都支持1M上下文窗口、384K最大输出、工具调用和JSON结构化输出。

▲ DeepSeek V4 Pro 原价与永久折扣价对比,75%降幅锁定
为什么这是标志性事件
定价逻辑的三层打击
DeepSeek的策略不是简单的"我们更便宜",而是一个精心设计的性价比组合拳:
第一层:基础定价已低于美国前沿模型。 即使在没有折扣的原始定价下,V4 Pro的$1.74/$3.48也已经低于GPT-5.5、Claude Opus 4.7和Gemini 3.1 Pro。现在折扣永久化,价格差距从"有竞争力"变成了"数量级碾压"。
第二层:缓存命中价几乎免费。 4月26日起,DeepSeek将所有模型的输入缓存命中价统一下调至原价的1/10。对于高频重复调用场景(比如Agent反复携带相同的系统提示词和代码上下文),这意味着绝大部分token都按缓存命中价计费。V4 Flash的缓存命中价仅为$0.0028/百万token——几乎可以忽略不计。
第三层:1M上下文窗口让缓存优势最大化。 大上下文窗口意味着你可以一次装入整个代码仓库、完整的API文档、或长对话历史,然后用缓存命中价进行后续交互。这在Agent编程场景下尤其致命——系统提示词和项目上下文始终在缓存中,每次调用的增量成本微乎其微。
Kilo的实战对比:便宜100倍
技术博客Kilo.ai在本月早些时候发布了V4 Pro和V4 Flash与Claude Opus 4.7、Kimi K2.6的横向对比测试,使用相同的FlowGraph基准(一个含20个端点的工作流编排后端)。结果惊人:
- V4 Flash的成本/得分比Claude Opus 4.7便宜约100倍,比Kimi K2.6便宜约30倍。
- 虽然V4 Flash的绝对得分低于两款竞品,但美元成本之低使得"跑三四次再选最佳结果"的总花费依然低于一次Opus 4.7调用。
这不是"便宜但不好用"的故事,而是"便宜到你可以用数量换质量"的新范式。
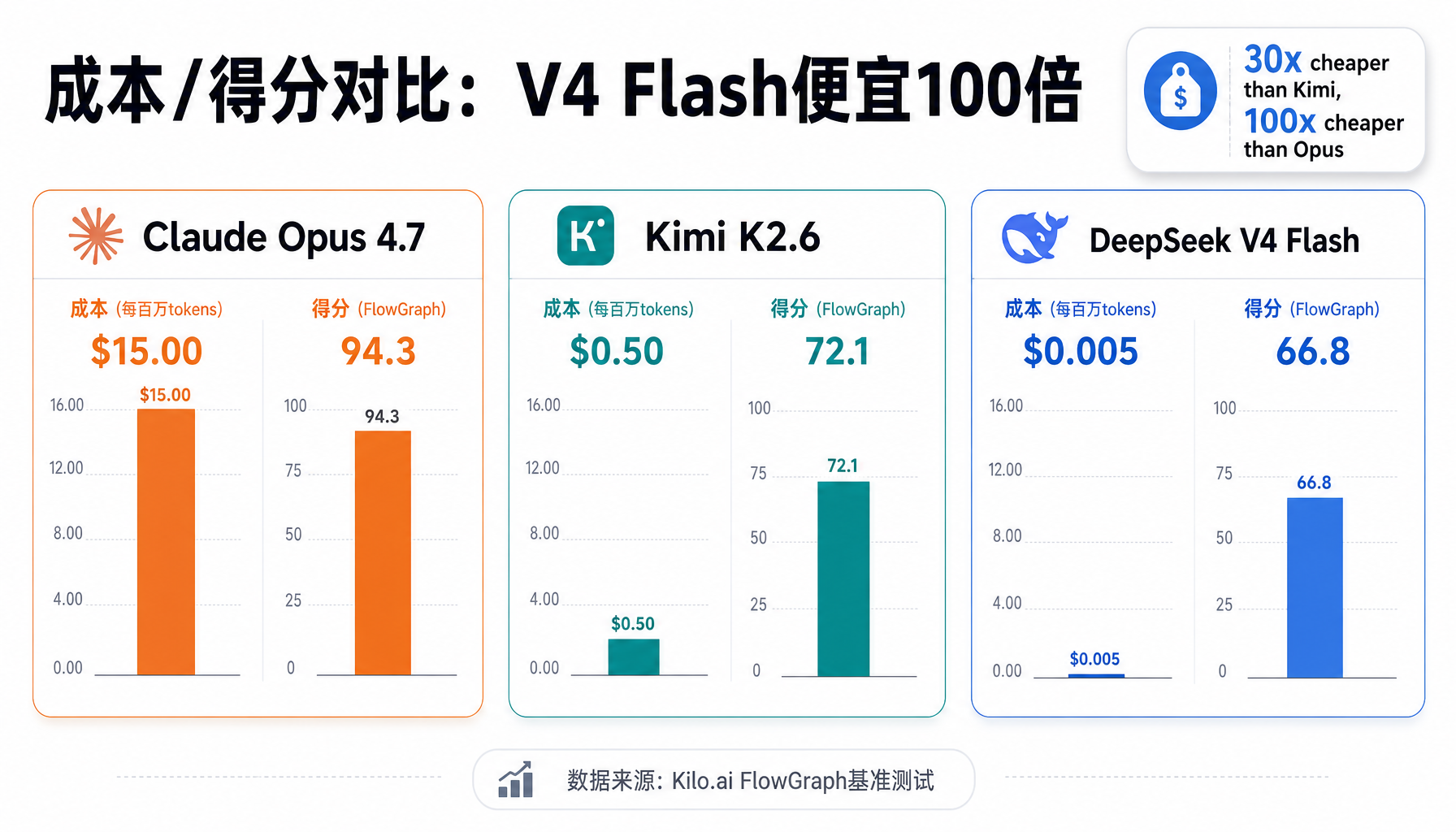
▲ Kilo.ai FlowGraph基准测试:V4 Flash成本/得分比Claude Opus 4.7便宜100倍
HN社区的真实反馈
HN评论区出现了多个一线开发者的使用数据:
一位开发者表示使用V4 Pro处理了6500万token,按照永久折扣价仅花费1.5美元。另一位开发者称已将V4 Flash作为日常默认模型,"第一个能用1M上下文的可访问模型"。还有团队表示正在评估从Anthropic迁移到DeepSeek,因为每日数亿token的调用量下,成本差距已经大到不可忽视。
值得注意的是,V4 Pro和Flash已原生兼容Claude Code、OpenClaw和OpenCode等主流Agent编程框架,迁移成本极低。
对AI创业者的三个直接冲击
1. Agent产品的成本模型改写
如果你的产品依赖LLM API进行推理、编程或自动化,DeepSeek的定价意味着你的毛利率结构将根本性改变。以每月1亿token调用量为例:用Claude Opus 4.7(假设$15/$75定价)月成本可能在数千美元级别;用V4 Pro($0.435/$0.87),同样的调用量月成本不到一百美元。
更关键的是,缓存命中价使得"携带大量上下文"从成本劣势变成了优势——你可以给Agent加载更多项目知识而不必担心token账单爆炸。
2. 国产芯片路线的可行性得到验证
V4 Pro训练和推理均基于华为昇腾950芯片和寒武纪硬件,而非NVIDIA GPU。这意味着在中美芯片管制持续收紧的背景下,DeepSeek证明了"不用NVIDIA也能造出有竞争力的模型"。对于关注供应链风险的AI创业者,这是极其重要的信号——AI基础设施的成本结构可能出现根本性变化。
Counterpoint Research首席分析师魏孙指出:"V4基于国产芯片运行,使AI系统可以不依赖NVIDIA构建和部署,这不仅能加速国内采用,还能促进全球AI发展提速。"
3. 从"用哪个模型"到"什么时候用哪个模型"
未来AI产品的架构将不再是单一模型绑定,而是多模型路由器——高频低复杂度的调用走V4 Flash(几乎免费),中复杂度走V4 Pro(性价比极致),只有在确实需要顶级推理能力时才调用Opus或GPT-5.5。这种"模型分层"架构将成为AI创业的标准配置。
行动建议
- 立即注册DeepSeek API账号并测试V4 Pro。 75%折扣在5月31日前仍有效,之后也是1/4价——没有理由不试试。特别是如果你在用Claude Code或OpenCode,切换成本只需改一个API base URL。
- 重构你的Agent上下文策略。 1M上下文窗口+几乎免费的缓存命中价,意味着你可以设计"重型上下文Agent"——提前加载完整的代码库、产品文档、用户画像,每次交互只需负担增量token。这不是渐进优化,而是架构层面的重新设计。
- 审计你的API账单。 如果你的月token消耗在百万级以上,切换到DeepSeek的ROI可能是整个Q2最有价值的决策。尤其检查那些"高频但不那么难"的调用——这些正是V4 Flash的最佳场景。
- 建立模型分层路由。 开始设计你的模型选择逻辑:简单代码补全→V4 Flash,中等复杂度编程→V4 Pro,顶级推理和创意任务→Opus/GPT-5.5。这将是2026下半年AI产品架构的基本模式。
- DeepSeek托管在中国大陆,数据合规和隐私政策需仔细评估,特别是处理敏感客户数据时。
- 模型能力与Claude Opus 4.7仍有差距,Kilo测试显示V4 Pro在复杂推理任务上不及Opus。不是所有场景都适合切换。
- DeepSeek的并发限制(V4 Pro 500并发,V4 Flash 2500并发)可能在高负载场景下成为瓶颈。
- API稳定性和SLA尚未经历大规模生产环境的长期考验。
本文由AI辅助创作,经人工审核编辑发布