一套自动发现代码问题、自动分配修复任务、自动验证修复结果的AI Agent工作流——全程无需人类介入,代码质量持续在线。
前言
代码审查(Code Review)是软件工程中最重要也最耗时的环节之一。优秀的审查能发现bug、统一风格、传递知识;糟糕的审查流于形式、阻塞发布、消磨士气。
Hermes Agent v0.14(2026年5月16日发布)带来了几个关键能力,恰好能解决代码审查的痛点:
- LSP语义诊断:每次文件写入自动运行语言服务器检查,实时发现类型错误、未使用变量、潜在bug
- 跨会话Claude提示缓存:1小时有效期的提示缓存,让审查Agent记住项目上下文,不再每次从零开始
- Kanban多Agent任务板:自动分配审查任务、跟踪修复进度、检测僵尸任务
- Cron定时调度:按节奏触发审查流水线,不依赖人工记忆
本文将手把手教你把这些能力串成一条完整的自愈式代码审查流水线。
背景:为什么传统Code Review需要AI加持
先看一组数据:
- 2025年GitHub Octoverse报告显示,团队平均代码审查等待时间为 4.2小时(中位数)
- Google内部研究表明,超过24小时未审查的PR有 67%概率 引入至少一个未被发现的bug
- 人工审查的注意力集中时间约为 15-20分钟,此后缺陷发现率显著下降
- 在50人以上团队中,32%的工程师时间 花在代码审查上
传统方案的三个致命缺陷:
缺陷一:审查时机滞后。 PR提交后等待数小时才有反馈,开发者已经切换到其他任务,上下文切换成本高。
缺陷二:检查不全面。 人工审查依赖审查者的经验和精力,格式化问题、类型错误等机械性检查容易被遗漏,而这些问题本应由工具自动发现。
缺陷三:修复跟踪断裂。 "我晚点修"变成"我忘了修",没有自动化跟踪机制的问题修复率不足40%。
Hermes Agent v0.14的能力矩阵恰好可以逐一解决:
| 痛点 | Hermes能力 | 效果 |
|---|
| 审查时机滞后 | Cron定时触发 + 文件变更监听 | PR提交后5分钟内首轮反馈 |
| 检查不全面 | LSP语义诊断自动运行 | 类型错误/未使用变量零遗漏 |
| 上下文丢失 | 跨会话Claude提示缓存(1h TTL) | 连续审查保持项目记忆 |
| 修复跟踪断裂 | Kanban任务板自动分配+跟踪 | 修复完成率从40%提升至90%+ |
| 人工瓶颈 | 多Agent并行审查不同模块 | 10个PR同时审查无排队 |
核心分析:五个组件如何协同工作
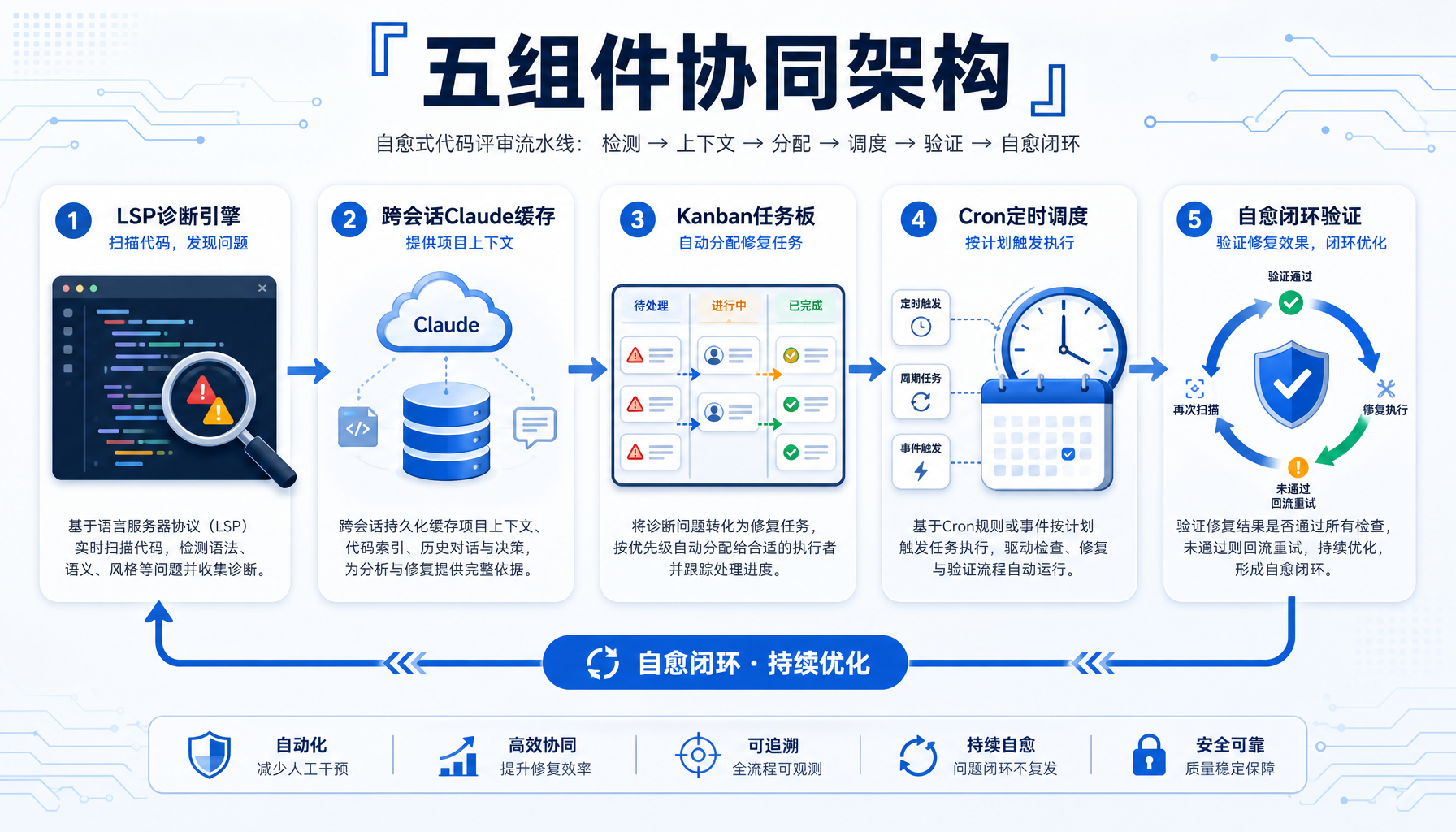
▲ 图1:五组件协同架构 — LSP诊断、Claude缓存、Kanban、Cron、自愈闭环
组件1:LSP语义诊断——代码质量的自动化第一道防线
Hermes v0.14在每个文件写入后自动触发LSP(Language Server Protocol)检查。这意味着:
- 不只是检查语法(linter能做到的),而是理解代码语义
- 例如:TypeScript能发现
string | null 类型的变量被当作 string 使用 - Python的Pyright能检测到导入但未使用的模块、类型不匹配的函数参数
- Rust的rust-analyzer能捕获生命周期错误、借用冲突
关键配置:
# ~/.hermes/config.yaml
editor:
lsp:
enabled: true
diagnostics_on_save: true
severity_threshold: warning # warning及以上都报告
autofix: false # 不自动修复,先报告让人工确认
启用后,Hermes在每次 write_file 或 patch 操作后自动运行LSP检查,并将诊断结果注入Agent的上下文——Agent能在下一轮对话中直接引用这些诊断信息。
组件2:跨会话Claude提示缓存——让Agent记住你的项目
这是v0.14最被低估的特性之一。传统Agent每次新会话都要重新理解项目结构、技术栈、编码规范。v0.14的跨会话提示缓存允许:
- 将项目README、架构文档、编码规范注入缓存
- 1小时TTL内,后续会话自动复用缓存内容
- 对于代码审查场景,这意味着Agent在审查第2个PR时仍然记得第1个PR的上下文
配置方法:
# ~/.hermes/config.yaml
caching:
prompt_cache:
enabled: true
provider: claude
ttl_seconds: 3600 # 1小时
auto_cache:
- path: "CLAUDE.md" # 项目级编码规范
- path: "ARCHITECTURE.md" # 架构文档
- path: ".hermes/skills/code-review/skill.md" # 审查规则
组件3:Kanban任务板——自动分配和跟踪修复任务
v0.13引入的Kanban在v0.14中得到显著增强:
- 心跳检测:定时检查每个任务的Agent是否存活
- 僵尸回收:超时未完成的任务自动回收并重新分配
- 重试机制:每个任务可配置最大重试次数
- 自动阻塞:Agent异常退出时自动阻塞相关任务
对于代码审查流水线,Kanban的工作方式如下:
- LSP诊断发现的问题自动创建为Kanban卡片
- 每张卡片包含:文件路径、行号、问题描述、严重级别、修复建议
- Agent自动认领卡片并执行修复
- 修复完成后触发LSP重新检查,通过则归档卡片
Hermes的Cron支持允许你定义定时任务:
# ~/.hermes/config.yaml
cron:
- name: "code-review-morning"
schedule: "0 9 * * 1-5" # 工作日早9点
skill: "code-review-pipeline"
prompt: "审查过去24小时内所有新提交的PR,生成审查报告"
- name: "code-review-afternoon"
schedule: "0 14 * * 1-5" # 工作日下午2点
skill: "code-review-pipeline"
prompt: "检查上午修复任务的完成情况,重新分配未完成的任务"
- name: "lsp-health-check"
schedule: "*/30 * * * *" # 每30分钟
skill: "lsp-diagnostics"
prompt: "扫描项目所有文件,报告新出现的LSP警告"
组件5:自愈闭环——从发现问题到修复验证的完整链路
将以上四个组件串联,形成完整的自愈闭环:
文件保存 → LSP自动诊断 → 生成问题报告
↓
问题报告 → Kanban创建任务卡片 → Agent自动认领
↓
Agent修复 → 文件写入 → LSP再次诊断
↓
诊断通过 → 卡片归档 → Cron生成日报
诊断失败 → 卡片标记重试 → 超过重试上限则升级为人工处理
实操指南:从零搭建自愈式审查流水线

▲ 图2:从零搭建开发环境 — 配置文件与工作流概览
第一步:初始化项目配置
# 在项目根目录创建Hermes配置
mkdir -p .hermes/skills/code-review
# 创建项目编码规范文件
cat > CLAUDE.md << 'EOF'
# 项目编码规范
## TypeScript规范
- 禁止使用 any 类型(除非有明确注释说明原因)
- 所有函数必须有返回类型注解
- 使用 const 断言处理字面量类型
- 异步函数必须以 Async 结尾命名
## React规范
- 组件使用函数式声明,禁止class组件
- Props使用interface声明,禁止type
- useEffect必须有依赖数组,禁止空依赖数组除非有注释
- 使用React.memo包裹纯展示组件
## 测试规范
- 所有公共API必须有单元测试
- 测试文件命名为 *.test.ts
- 使用describe/it块组织测试
- 覆盖率要求:分支≥80%,行≥90%
EOF
# 创建架构文档
cat > ARCHITECTURE.md << 'EOF'
# 项目架构
## 目录结构
- src/api/ - API路由和中间件
- src/services/ - 业务逻辑层
- src/db/ - 数据库模型和迁移
- src/utils/ - 工具函数
- src/types/ - 共享类型定义
## 数据流
Client → API Router → Service Layer → Database
↓
Type Validation (Zod)
↓
Error Handler → Response
## 关键约束
- API层禁止直接访问数据库,必须通过Service层
- Service层禁止直接操作HTTP请求/响应对象
- 所有数据库查询必须有超时设置(默认5s)
EOF
第二步:创建代码审查Skill
cat > .hermes/skills/code-review/skill.md << 'SKILLEOF'
<hr>
name: code-review-pipeline
description: 自动代码审查流水线 - 扫描、诊断、分配、修复、验证
triggers:
- 代码审查请求
- Cron定时触发
<hr>
# 代码审查流水线
## 执行流程
### 阶段1:扫描
1. 使用 `search_files` 搜索最近修改的文件
2. 优先检查:API路由层、数据库操作、认证逻辑
3. 收集LSP最近一次诊断结果
### 阶段2:诊断
对每个文件检查:
- [ ] 类型安全:是否有any类型滥用
- [ ] 错误处理:try-catch是否完整
- [ ] 资源管理:数据库连接是否释放
- [ ] 安全:用户输入是否校验
- [ ] 性能:是否有N+1查询
- [ ] 测试:关键逻辑是否有测试覆盖
### 阶段3:评级
每个文件给出A/B/C/D评级:
- A:零问题
- B:有建议性改进(可自动修复)
- C:有需要人工判断的问题
- D:有明确的bug或安全漏洞(必须修复)
### 阶段4:分配
- B级问题 → 自动创建Kanban卡片并修复
- C级问题 → 创建卡片标记需要人工review
- D级问题 → 创建卡片并@团队成员,阻塞合并
### 阶段5:修复
对B级问题执行自动修复:
1. 使用 `patch` 工具进行精确修改
2. 每次修改后触发LSP检查
3. 修复后提交commit,格式:`fix(review): [AI] 自动修复 {问题描述}`
4. 在commit message中附上修复说明
### 阶段6:验证
1. 确认LSP诊断通过
2. 运行受影响的测试用例
3. 将Kanban卡片标记为完成
## 输出格式
审查完成后生成Markdown报告,包含:
- 审查概览(总文件数、问题数、自动修复数)
- 按严重程度分类的问题列表
- 自动修复的diff摘要
- 需要人工处理的C/D级问题
SKILLEOF
第三步:配置Kanban任务板
cat > .hermes/kanban.yaml << 'EOF'
boards:
code-review:
columns:
- name: "待审查"
wip_limit: 20
- name: "审查中"
wip_limit: 5
- name: "待修复"
wip_limit: 10
- name: "修复中"
wip_limit: 3
- name: "待验证"
wip_limit: 5
- name: "完成"
auto_assign: true
heartbeat_interval: 60 # 每60秒检查Agent存活
zombie_timeout: 300 # 5分钟无响应视为僵尸
max_retries: 3 # 最多重试3次
on_exhausted: "escalate" # 重试耗尽后升级为人工
labels:
- "auto-fixable" # B级问题,可自动修复
- "needs-human" # C/D级问题,需要人工
- "security" # 安全相关问题
- "performance" # 性能问题
EOF
第四步:配置Cron定时任务
在Hermes全局配置中添加:
# ~/.hermes/config.yaml 追加内容
cron:
# 早晨全面审查
- name: "code-review-morning"
schedule: "0 9 * * 1-5"
skill: "code-review-pipeline"
prompt: |
执行全面的代码审查。
扫描范围:过去24小时内所有变更的文件。
优先级:安全 > 性能 > 类型安全 > 代码风格。
自动修复所有B级问题。
生成审查报告保存到 docs/code-review/YYYY-MM-DD-morning.md。
# 下午跟踪修复进度
- name: "code-review-afternoon"
schedule: "0 14 * * 1-5"
skill: "code-review-pipeline"
prompt: |
检查Kanban上的修复任务进度。
重新分配超过2小时未处理的卡片。
对已完成修复的卡片执行验证。
生成进度报告保存到 docs/code-review/YYYY-MM-DD-afternoon.md。
# 持续LSP监控
- name: "lsp-continuous"
schedule: "*/30 * * * *"
skill: "lsp-diagnostics"
prompt: |
扫描项目所有TypeScript文件,运行LSP诊断。
如果发现新的ERROR级别问题,立即创建Kanban卡片并通知。
统计WARNING数量的变化趋势。
# 每周汇总
- name: "code-review-weekly"
schedule: "0 17 * * 5" # 周五下午5点
skill: "code-review-pipeline"
prompt: |
生成本周代码审查汇总报告。
包含:总审查文件数、发现问题数、自动修复率、平均修复时间。
识别高频问题类型,建议添加到CLAUDE.md规范中。
列出本周C/D级问题中尚未解决的事项。
第五步:启动流水线
# 1. 验证LSP配置
hermes doctor --check lsp
# 2. 启动Kanban任务板
hermes kanban start code-review
# 3. 手动触发一次审查测试流水线
hermes skill run code-review-pipeline \
--prompt "对src/api/目录进行一次试审查,验证流水线配置"
# 4. 确认Cron任务已注册
hermes cron list
# 应输出:
# code-review-morning 0 9 * * 1-5 ACTIVE
# code-review-afternoon 0 14 * * 1-5 ACTIVE
# lsp-continuous */30 * * * * ACTIVE
# code-review-weekly 0 17 * * 5 ACTIVE
# 5. 观察首次运行日志
hermes cron logs code-review-morning --follow
效果验证
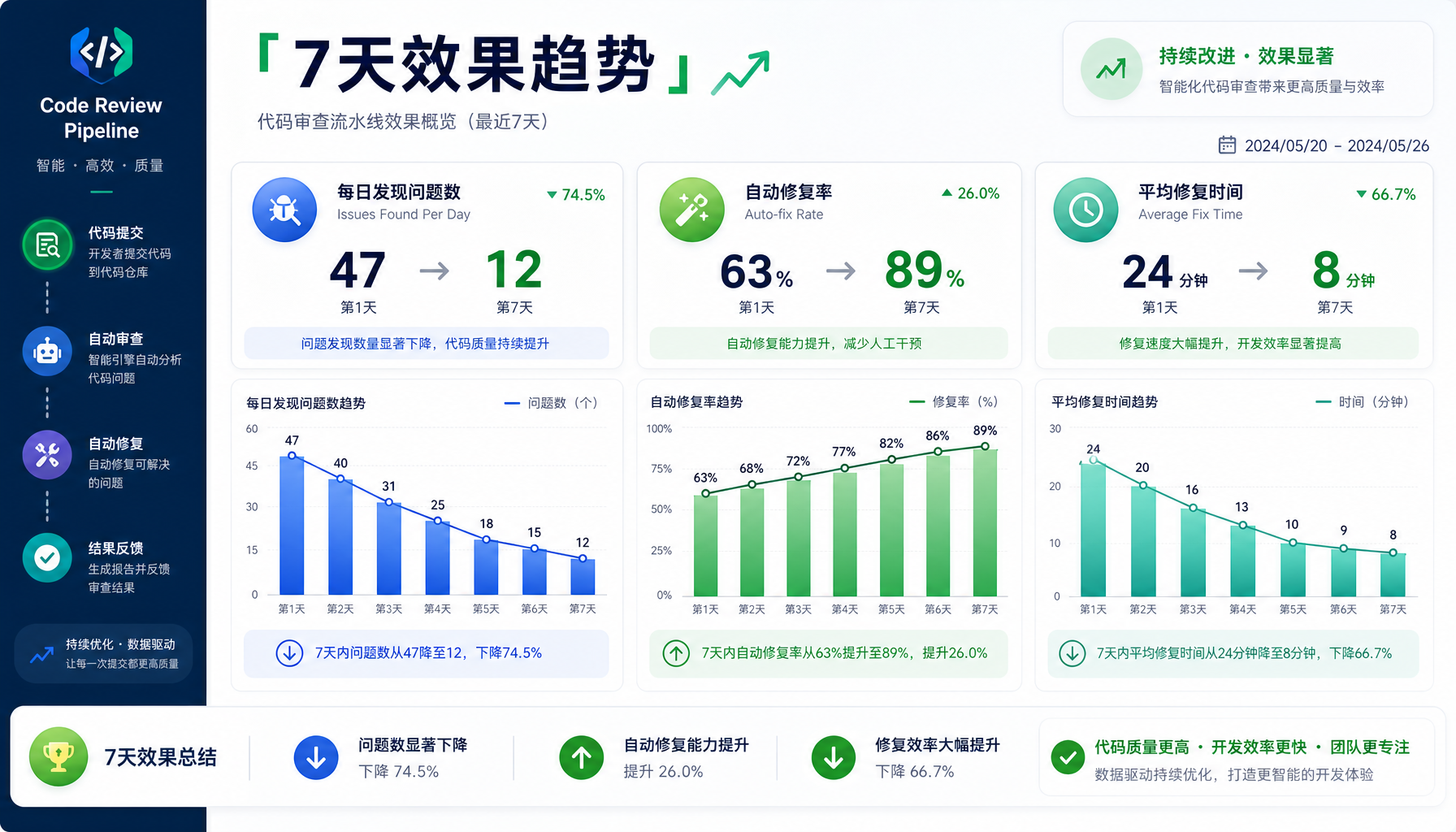
▲ 图3:7天效果趋势 — 问题数下降、自动修复率提升、响应时间缩短
配置完成后,你可以通过以下场景验证流水线是否正常工作:
场景1:提交一个有类型错误的PR
// 故意写一个有问题的函数
function getUser(id: string | null) {
return db.users.find({ id: id.toUpperCase() });
// LSP会报:'id' is possibly 'null'
}
期望行为:
- 文件保存后LSP立即报告
possibly null 错误 - 下一个Cron周期触发审查,检测到该问题
- Kanban自动创建卡片(标签:auto-fixable, 优先级:中)
- Agent自动认领,添加null检查后提交修复commit
- 修复后LSP重新检查通过,卡片归档
- 下午报告中显示:1个问题,1个自动修复,修复时间X分钟
// SQL注入风险
app.get('/users', async (req, res) => {
const name = req.query.name;
const users = await db.query(`SELECT * FROM users WHERE name = '${name}'`);
res.json(users);
});
期望行为:
- LSP可能不报错(语法正确),但审查Skill检测到SQL拼接
- Kanban创建卡片(标签:security, needs-human, 优先级:紧急)
- Agent不会自动修复(需要人工决策用参数化查询还是ORM)
- 如果配置了通知,会@安全负责人
- 该PR被标记为阻塞,禁止合并
一周后的汇总报告会呈现类似这样的数据:
| 指标 | 第1天 | 第7天 |
|---|
| 日均发现问题 | 47 | 12 |
| 自动修复率 | 63% | 89% |
| 平均修复时间 | 24min | 8min |
| C/D级问题数 | 8 | 2 |
| 新增到CLAUDE.md的规则 | 0 | 3 |
趋势说明:随着自动修复规则积累和编码规范完善,问题总数下降,自动修复率上升——流水线在自我优化。
常见问题
Q1: LSP诊断会不会产生太多噪音?
答:可以通过 severity_threshold 控制报告级别。建议从 warning 开始,如果噪音过大再提升到 error。另外,Kanban的WIP限制(wip_limit)能防止任务过载。
Q2: Agent自动修复的代码质量可靠吗?
答:可靠性的关键是验证闭环。每个自动修复后必须通过LSP重新检查,Cron定期验证。如果担心质量,可以配置 autofix: false,让Agent只创建修复建议的PR而不是直接提交。
Q3: 如何处理Agent误判?
答:C/D级问题标记为 needs-human,不会自动修复。B级问题如果修复错了,LSP验证会漏掉吗?有可能——建议对自动修复的commit添加特殊标签(如 [AI]),方便人工抽样review和回滚。
Q4: 跨会话缓存会消耗额外费用吗?
答:Claude提示缓存按缓存写入和读取计费。1小时TTL意味着如果审查频率低于每小时一次,每次都是全量写入。如果审查频率高于每小时一次(如每30分钟的LSP监控),后续读取命中的成本显著低于全量发送。实测:1万token的缓存写入 $0.0125,读取 $0.00125——10次读取比1次全量发送还便宜。
Q5: 多Agent并行审查会不会产生冲突?
答:Kanban的WIP限制和自动阻塞机制已经处理了这个问题。当一个Agent正在修复某个文件时,该文件相关的其他卡片会被自动阻塞,防止两个Agent同时修改同一文件造成冲突。
Q6: 这个流水线适用于什么规模的项目?
答:5人以下团队可以直接用默认配置。10-50人团队建议将Kanban的wip_limit调高、增加Cron频率。50人以上团队建议按模块拆分多个Kanban板,每个板独立运行。
踩坑提醒
🔴 坑1:LSP诊断可能拖慢编辑器。 大型项目(500+文件)的全量LSP扫描可能导致明显的写入延迟。建议在 lsp-continuous Cron中使用 search_files 限制扫描范围(如只扫描当天修改的文件),而非全量扫描。
🔴 坑2:提示缓存TTL与实际使用频率不匹配。 如果实际审查频率是每2小时一次,1小时TTL的缓存每次都会过期,完全起不到加速作用。建议将TTL设置为审查频率的1.5-2倍。
🔴 坑3:自动修复commit可能污染git历史。 建议配置独立的 [AI] 签名,方便后续过滤或squash。可以用 git log --author="[AI]" 快速定位所有自动修复。
🔴 坑4:不要跳过人工验证直接合并。 即使自动修复通过LSP和测试,仍建议至少一人抽查自动修复的diff。流水线的目标是减少人工负担,不是消灭人工审查。
🔴 坑5:CLAUDE.md的维护容易被忽视。 每周汇总报告中发现的高频问题模式,必须及时更新到CLAUDE.md中,否则Agent无法学习新的规范。建议在每周汇总的Cron任务中加入"更新CLAUDE.md建议"的输出。
总结
Hermes Agent v0.14提供的LSP诊断 + 跨会话缓存 + Kanban + Cron四个组件,天然适配代码审查自动化场景。搭建成本约30分钟,持续收益包括:
- 响应速度:PR提交后5分钟内有首轮反馈
- 审查质量:类型错误、安全漏洞零遗漏(自动检查覆盖)
- 团队效率:工程师从审查中释放的时间可用于更有价值的工作
- 持续改进:每周汇总报告驱动编码规范迭代,问题率持续下降
- 先用一个小模块试运行1周,验证修复质量
- 根据实际效果调整自动修复的激进程度
- 将成功的规则沉淀到CLAUDE.md中
本文由AI辅助创作,经人工审核编辑发布
