
通义千问今日发布 Qwen3.7-Max,定位「Agent 时代的基础模型」—— 在 Coding Agent、General Agent、STEM 推理三大维度横扫竞品。更惊人的是:一次 35 小时、1000+ 工具调用的全自主内核优化任务,全程零人工干预。
事件速览
2026 年 5 月 20 日,阿里通义千问团队正式发布 Qwen3.7-Max,这是其最新的闭源旗舰模型,明确以「Agent 时代」为设计目标。与此前版本不同,Qwen3.7-Max 的核心卖点不再是通用对话能力,而是编程 Agent、办公自动化、长程自主执行三个 Agent 核心场景。
一句话总结:这不是又一个比跑分的 LLM,这是一台为 AI Agent 专门调校的引擎。
Qwen3.7-Max 将通过阿里云 ModelStudio 提供 API 调用,目前标注为「即将上线」。
为什么这个发布值得你关注
1. Agent 不再是「插件功能」,而是设计原点
过去一年,各大模型厂商的路线大多是「先做好基础模型,再往上加 Agent 能力」—— 给 Claude 加 computer use,给 GPT 加 tools,给 Gemini 加 grounding。这些都是在通用模型上嫁接 Agent 功能。
Qwen3.7-Max 反其道而行:从设计之初就以 Agent 为第一优先级。官方博客明确写道:「built to be a versatile agent foundation」—— 它不是会 Agent 的 LLM,它就是为 Agent 而生。
这对 AI 创业者意味着什么?你不再需要「凑合着用」一个通用模型跑 Agent 工作流。 如果 Qwen3.7-Max 的定价延续阿里云的价格优势,它可能成为 AI 创业者部署多 Agent 系统的性价比最优解。
2. Benchmark 横扫:在 Agent 指标上全面压制
Qwen 官方公布了一份包含 30+ 项评测的详细对比表,对手包括 Anthropic Opus-4.6 Max、K2.6 Thinking、GLM-5.1 Thinking、DeepSeek-V4-Pro Max 和自家上一代 Qwen3.6-Plus。以下是关键赛道的表现:
Coding Agent(编程 Agent):
- Terminal Bench 2.0-Terminus:69.7(大幅领先 Opus-4.6 的 65.4 和 DS-V4-Pro 的 67.9)
- SWE-Pro:60.6(全部参评模型中最高,Opus 57.3,K2.6 59.5)
- SWE-Multilingual:78.3(最高)
- NL2repo:47.2(与 Opus 47.6 几乎持平,远超其他)
- SciCode:53.5(最高)
General Agent(通用 Agent):
- Skillsbench:59.2(远超第二名 K2.6 的 56.2,Qwen3.6-Plus 仅 45.7)
- MCP-Mark:60.8(最高,DS-V4-Pro 57.1)
- MCP-Atlas:76.4(最高)
- Kernel Bench L3:1.98 / 96%(仅次于 Opus-4.6 的 2.63/98%,但远超前代 Qwen3.6-Plus 的 1.03/48%)
STEM & Reasoning:
- GPQA Diamond:92.4(最高)
- HLE:41.4(最高)
- IMOAnswerBench:90.0(最高)
- Apex:44.5(大幅领先第二名 DS-V4-Pro 的 38.3)
这些数字说明了什么?Qwen3.7-Max 的 Agent 能力不是「接近」顶级水平,而是已经在多个维度上超越了当前所有主流模型。 尤其是在 Skillsbench(Agent 技能执行)上的 59.2 分,相比 Qwen3.6-Plus 的 45.7 分,代际提升高达 29.5%。
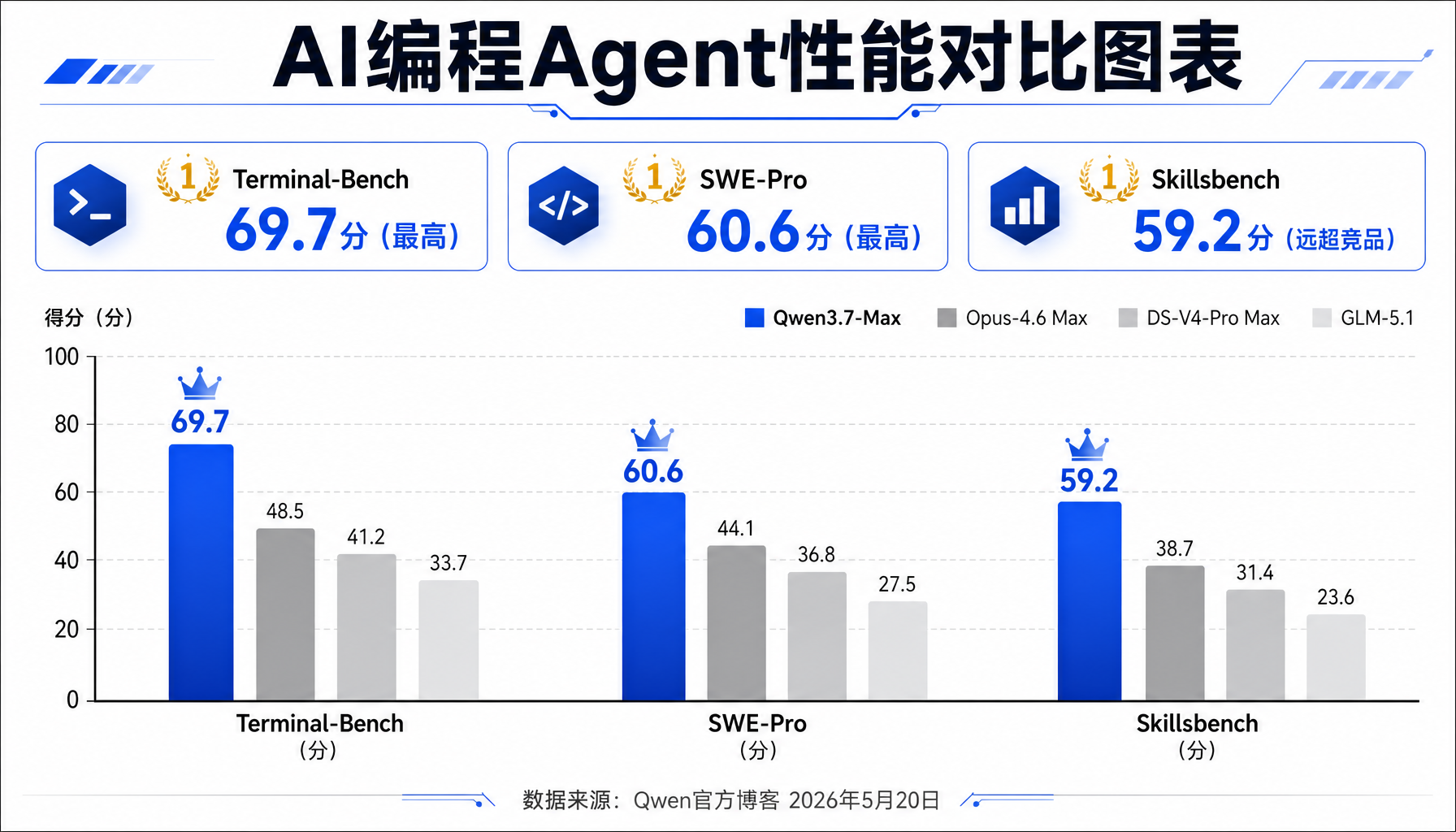
▲ Qwen3.7-Max 在 Coding Agent、General Agent、STEM 三大维度的基准测试表现,多项指标达到或超越当前主流模型
3. 35 小时全自主运行:Agent 稳定性的终极验证
这是整个发布中最令人震撼的数据点:Qwen3.7-Max 完成了一次 35 小时的全自主 Linux 内核优化任务,涉及超过 1,000 次工具调用,全程零人工干预。
这意味着什么?大多数 AI Agent 在连续运行几小时后会因上下文膨胀、状态偏移、工具调用错误等原因逐渐退化甚至崩溃。35 小时连续自主运行并保持有效推理,这是 Agent 工程领域的重大突破。
对于 AI 创业者来说,这意味着你可以放心地将 Qwen3.7-Max 部署到需要长期运行的 Agent 工作流中 —— 例如 24 小时代码审查 Agent、自动化运维 Agent、持续内容生成管线等。
4. 跨框架兼容:不锁定生态
Qwen3.7-Max 的另一个关键特性是「cross-scaffold generalization」—— 它不绑定特定 Agent 框架。官方明确表示该模型在 Claude Code、OpenClaw、Qwen Code 等不同 Agent 框架上表现一致。
这是一个聪明的策略。目前 Agent 框架生态高度碎片化 —— Anthropic 推 Claude Code,OpenAI 推 Codex,Nous Research 推 Hermes Agent,OpenClaw 独立发展。一个模型如果在不同框架上表现差异巨大,创业者就要被迫选边。Qwen3.7-Max 的跨框架一致性,意味着你可以根据实际需求选框架,而不被模型能力限制。
Agent 模型竞争格局正在重塑
Qwen3.7-Max 的发布,标志着 AI Agent 竞争进入了一个新阶段。回顾过去半年的发展:
- 2025 年底:Anthropic 推出 Claude Code,定义了「用 AI 写代码」的产品形态
- 2026 年初:OpenAI 发布 Codex CLI,Google 推出 Gemini with grounding
- 2026 年 4 月:Hermes Agent v0.13 新增 delegate_task 多 Agent 协作
- 2026 年 5 月:Hermes Agent v0.14 发布,支持 Grok OAuth、OpenAI 兼容代理
- 2026 年 5 月 20 日:Qwen3.7-Max 发布,首次有模型以 Agent 为核心设计目标
格局已经清晰:Agent 不再是 LLM 的附属功能,而是下一代模型的核心竞争力。 未来评判一个模型的好坏,SWE-bench 和 MMLU 将不再是唯一标准 —— Skillsbench、MCP-Mark、Kernel Bench 这些 Agent 原生评测将越来越重要。
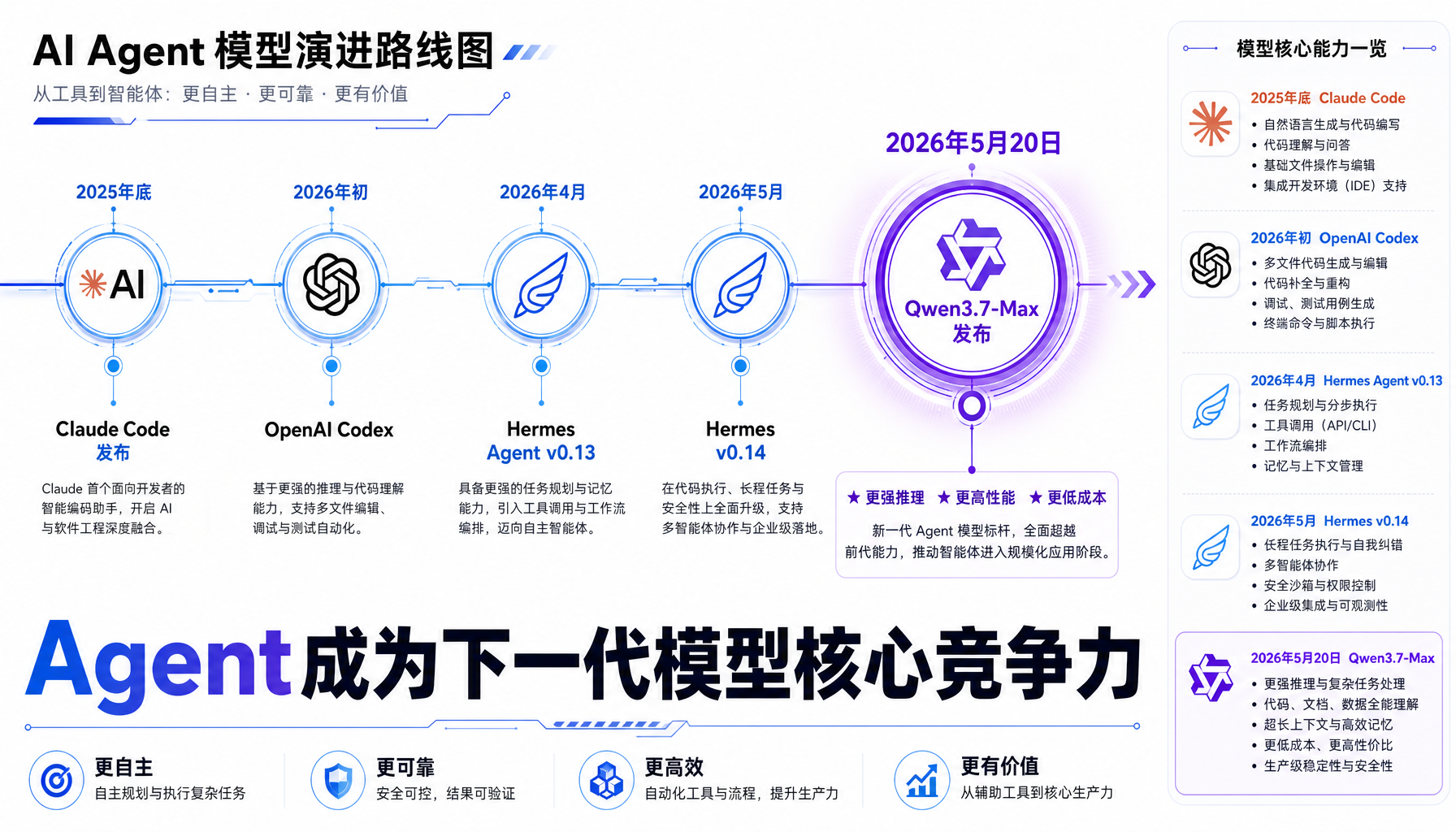
▲ 2025年底至今,AI Agent 模型和工具快速迭代,Qwen3.7-Max 是首个以 Agent 为核心设计目标的前沿模型
Agent 时代的新竞争逻辑
Qwen3.7-Max 的发布揭示了一个正在发生的产业变化:Agent 能力正在从「差异化卖点」变成「入场门票」。
六个月前,一个模型如果能在 SWE-bench 上拿到 75 分,已经可以被称为「编程 Agent 模型」并以此作为核心卖点。今天,Qwen3.7-Max 在几乎全部 Agent 相关评测上达到或超过现有最佳水平,而它对自己的定位只是「Agent 时代的基础模型」—— 注意,「基础」,不是「旗舰」。
这说明行业正在以惊人速度迭代。对于 AI 创业者,核心启示是:不要把你的产品价值建立在「某个模型比另一个强 5%」的基础上。 模型之间的差距在缩小,真正的竞争壁垒在于你的 Agent 工作流设计、数据飞轮、以及你对特定垂直场景的理解深度。
Qwen3.7-Max 的另一层含义是:中国 AI 团队在 Agent 方向上的投入正在产生实质成果。 从 Qwen3.6-Plus 到 Qwen3.7-Max,Skillsbench 从 45.7 跃升至 59.2,Kernel Bench L3 从 1.03/48% 跃升至 1.98/96% —— 这不是微调级别的进步,而是代际级别的跨越。国内 AI 创业者将有更多来自本土模型的选择,减少对海外 API 的依赖。
行动建议
对 AI 创业者的具体建议:
- 关注阿里云 ModelStudio 的定价。Qwen 系列历史上定价显著低于 Anthropic 和 OpenAI。如果 Qwen3.7-Max 延续这一定价策略,它可能将 Agent 部署成本降低 50-70%。对于运行多 Agent 系统的团队来说,这意味着月成本可能从几千美元降到几百美元。
- 提前适配。如果你的 Agent 工作流当前绑定在单一模型上(如 Claude),开始评估模型切换的成本。Qwen3.7-Max 的跨框架兼容性降低了适配门槛,但提前做好 Prompt 格式兼容和输出解析的准备仍然必要。
- 关注 MCP 集成能力。Qwen3.7-Max 在 MCP-Mark(60.8)和 MCP-Atlas(76.4)上的高分表明其 MCP 协议支持出色。如果你的 Agent 工具栈基于 MCP,Qwen3.7-Max 是天然的高性能选择。
- 考虑 GPU 部署。虽然 Qwen3.7-Max 目前仅通过 API 提供,但 Qwen 系列通常会在 API 发布后开源或提供本地部署选项。对于有合规需求的企业客户,这是关键考量。
对 Agent 开发者的建议:
- 重新评估模型选型标准。如果你的 Agent 项目还在用 MMLU 或 HumanEval 作为模型选型标准,是时候切换到 Agent 原生基准了。Skillsbench、Terminal-Bench、MCP-Mark 这些评测更能反映模型在实际 Agent 场景中的表现。
- 测试长程稳定性。35 小时的长程运行是 Qwen3.7-Max 的差异化亮点。如果你有需要长时间自主运行的 Agent 场景(代码审查、运维监控、数据采集),Qwen3.7-Max 值得优先测试。
本文由AI辅助创作,经人工审核编辑发布