
438 points、170条讨论炸裂Hacker News的开源工具,让你用一台MacBook上的8B模型跑出接近Claude的Agent可靠性。
一句话说清楚
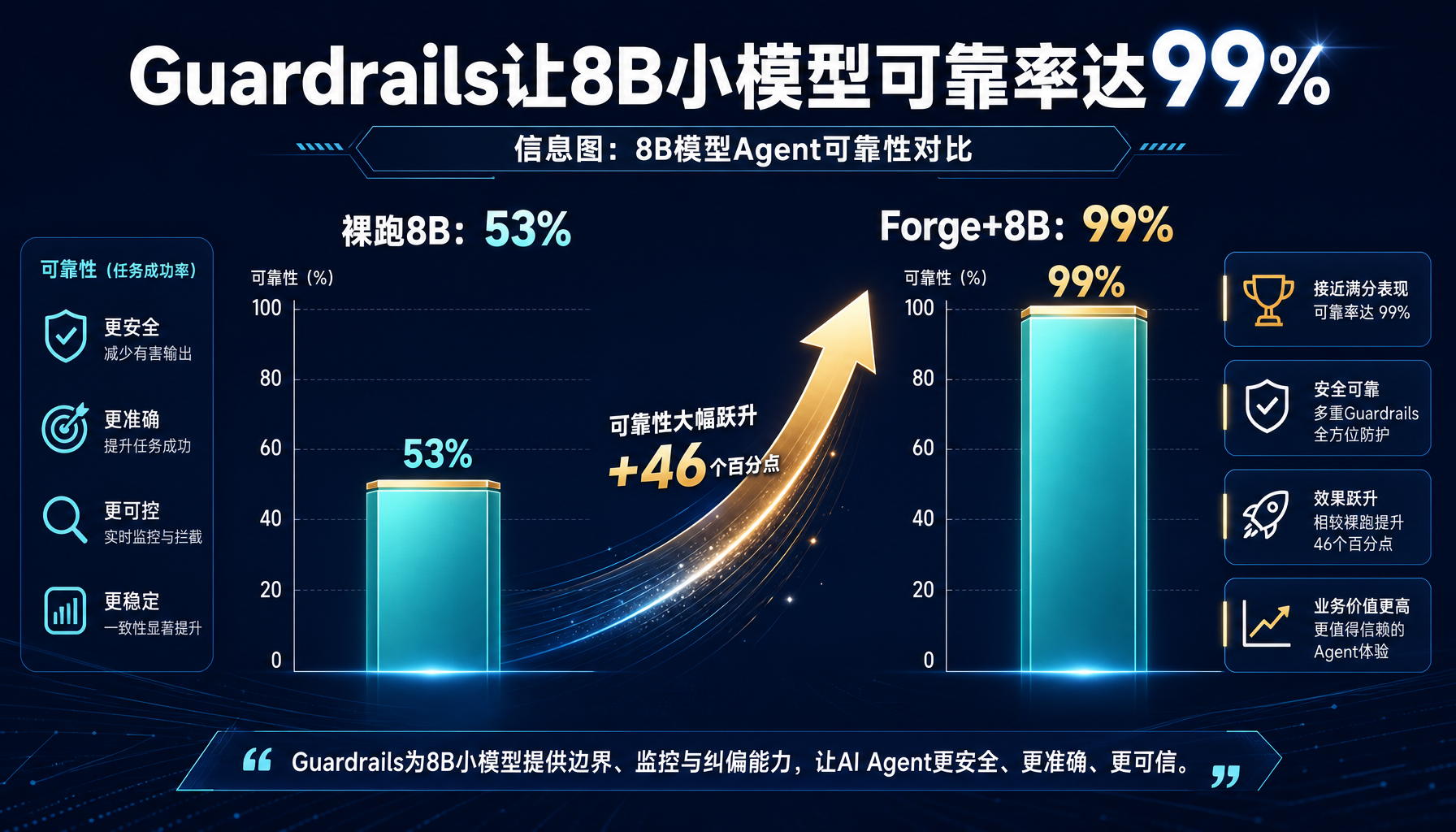
Forge是一个Python框架,唯一使命就是让自托管的8B小模型在Agent场景下变得可靠。它不做模型本身,而是给任何本地模型套上一层"安全网"——验证输出、修正错误格式、强制执行必要步骤、管理上下文窗口。结果:Ministral-3 8B在26个Agent场景下的得分从裸跑的53%飙升到86.5%,在基础场景甚至达到99%。
对于AI创业者来说,这意味着你可以在自己的服务器上跑Agent,不用担心API费用失控,也不用担心数据泄露。
为什么这件事值得你关注
过去一年,AI Agent赛道有一个隐含假设:要做可靠的Agent,必须用最贵的模型。Claude Sonnet每月几百美元的API账单是常态。但Forge的出现挑战了这个假设——它证明可靠性不只是模型能力问题,更是工程问题。
这和前端领域的"渐进增强"理念如出一辙。Forge的作者做了三件事:
1. 修复解析(Rescue Parsing)
小模型最常犯的错误是什么?返回格式不对。你让它调用get_weather,它返回一串话:"好的我来帮你查一下巴黎的天气"。不是它不会查,是它不知道要以JSON格式返回工具调用。
Forge的做法:在响应被解析失败时,不是直接报错,而是尝试多种方式修复——比如从文本中提取函数名、修复不完整的JSON、补全缺失的参数。这个细节让基础完成率从53%跳到了80%以上。
2. 重试提示(Retry Nudges)
当模型第一次失败后,Forge不直接放弃。它给模型发送一个提示,告诉它哪里出错了——"你上次调用search时缺少query参数,请尝试加上再试一次"。
这不是简单的"再试一次",而是结构化的错误信息,让模型知道具体怎么修正。连续3次修正失败才会放弃。
3. 步骤强制执行(Step Enforcement)
很多Agent任务需要按顺序完成多个步骤。比如"查天气→订机票→发邮件确认"——跳过第二步直接发邮件就是失败。Forge的工作流引擎会追踪必要步骤是否完成,没完成就不让任务结束。
三种集成模式:总有一款适合你
Forge最聪明的地方是它的三模式设计。不管你现在的技术栈是什么,都能用上:
▲ Forge三模式集成架构:WorkflowRunner全托管、Proxy透明代理、Middleware可组合组件,三种模式共享同一Guardrails核心
模式一:WorkflowRunner(全托管)
适合从零开始构建Agent的团队。你定义工具和流程,Forge完全接管Agent循环。
模式二:代理服务器(零改动)
这是最实用的模式。Forge作为一个本地代理运行,把任何OpenAI兼容的客户端(OpenCode、Continue、Aider等)连接到你的本地模型。客户端完全不知道Forge的存在,但享受了所有guardrails的保护。
代理模式的核心妙招:Forge自动注入一个虚拟的respond工具。模型调用respond(message="...")而不是直接输出文本。这让小模型始终保持在工具调用模式——作者实测发现,如果不这样做,小模型在"直接回答还是调用工具"的选择上正确率只有4%。强制走工具调用后,完成率回到100%。
模式三:中间件(自由组合)
如果你已经有自己的Agent框架,只想用Forge的guardrails:
实战教程:30分钟跑通你的第一个Forge Agent
理论说完,上实操。以下是Mac/Linux环境下从零到跑通的完整步骤。
环境准备(5分钟)
第一个Agent:天气查询(5分钟)
输出示例:
进阶:多步骤研究Agent(10分钟)
真正的Agent价值在于多步骤协作。下面这个例子展示了搜索→分析→总结的完整链路:
这个多步骤Agent如果裸跑8B模型,有47%的概率在中间某步卡住——比如搜完直接输出结果跳过分析,或者格式错误导致工具调用失败。Forge的步骤强制执行确保了链路完整,成功率从53%提升到接近100%。

▲ 30分钟从零搭建多步骤AI Agent:环境准备→工具定义→执行→输出
性能数据:用数字说话
Forge的26个评测场景覆盖了Agent任务的所有典型挑战:
| 场景类别 | 场景数 | 说明 |
|---|---|---|
| Plumbing(基础流程) | 3 | 工具调用循环是否正常工作 |
| Model Quality(模型质量) | 6 | 工具选择、参数精确度、条件路由 |
| Advanced Reasoning(高级推理) | 4 | 数据缺口恢复、参数转换、不一致API恢复 |
| Compaction Chain(压缩链) | 4 | 多阶段上下文压缩保留能力 |
| Stateful Variants(有状态变体) | 13 | 状态在多次调用间正确传递 |
核心结论:
- 裸跑8B模型在OG-18基础场景:53%
- 加上Forge guardrails后OG-18:99%
- 高级推理场景:76%
- 全场景综合分:86.5%
最佳配置:Ministral-3 8B Instruct Q8 + llama-server后端。不需要GPU集群,一台RTX 4090就能跑。
对AI创业者的实际意义
成本对比:API vs 自托管
| 方案 | 月成本(中等用量) | 可靠性 | 数据隐私 |
|---|---|---|---|
| Claude Sonnet API | $200-500 | ⭐⭐⭐⭐⭐ | ❌ 数据经第三方 |
| GPT-4o API | $150-400 | ⭐⭐⭐⭐ | ❌ 数据经第三方 |
| 自托管8B + Forge | $50-100(仅电费) | ⭐⭐⭐⭐ | ✅ 完全本地 |
这里的月成本差是3-5倍。对于每天跑几十个Agent任务的一人公司来说,一年能省下2400-4800美元。

▲ 自托管Agent月成本仅为商业API的1/5,数据完全本地化,无隐私泄露风险
三个立刻能落地的场景
1. 客服Agent:在你的服务器上跑一个8B模型+Forge,处理FAQ、查询订单状态、生成工单。不需要把客户数据发给OpenAI。
2. 内容审核流水线:自建的审核Agent永远比第三方API更灵活。你可以定制审核标准,成本也低得多。
3. 代码审查助手:用Continue或Aider连接Forge代理,享受本地模型的代码建议——私有代码库永远不会离开你的机器。
踩坑提醒
虽然Forge很强大,但有几点需要注意:
- 不是所有8B模型都一样好。Forge官方推荐Ministral-3 8B Instruct。其他8B模型(如Llama-3.1、Qwen2.5)的表现差异很大,需要自己跑eval测试。
- 代理模式有设计边界。步骤强制(Step Enforcement)只在WorkflowRunner模式下有效。代理模式只做响应质量守卫(验证+修复+重试),不做工作流级别的控制。
- 上下文窗口管理是隐藏成本。虽然8B模型支持32K-128K上下文,但长对话中推理质量会下降。Forge的TieredCompact策略(保留最新2轮+压缩旧消息)是必须启用的。
- 首次配置需要时间。安装llama-server、下载GGUF模型、配置Jinja模板——新手可能需要2-3小时才能跑通第一个Agent。
常见问题
Q: Forge和LangChain/LlamaIndex有什么区别?
LangChain和LlamaIndex是通用框架,侧重"能做什么"。Forge是可靠性层,侧重"能做到多好"。你完全可以把Forge的guardrails用在LangChain的Agent循环里(通过中间件模式)。两者是互补关系,不是替代关系。
Q: 8B模型真的够用吗?什么场景不够?
评测数据说话:基础Agent任务(工具调用、参数传递、条件路由)8B+Forge能做到99%。但复杂推理(多跳数据整合、API不一致恢复)只能到76%。如果你的Agent需要在一轮对话里综合5个不同来源的信息并做复杂推断,建议上14B或直接用API。
Q: 代理模式会不会拖慢响应?
Forge在每次LLM调用后只增加50-200ms的验证和修复时间。但如果触发重试(模型第一次输出不合格),总耗时会翻倍。官方建议:简单任务(1-2次工具调用)用代理模式,复杂工作流用WorkflowRunner。
Q: 能直接用中文模型吗?
Forge与模型无关,只依赖工具调用协议。任何支持Ollama或llama-server的中文模型(如Qwen2.5、Yi)都能用。但官方eval只在Ministral-3和Qwen3上跑过,其他模型需要你自己测。
延伸思考:AI Agent的未来在工程层,不在模型层
Forge的成功暗示了一个趋势:在模型能力趋于同质化的2026年,Agent可靠性的竞争正在从模型层转移到工程层。
OpenAI、Anthropic靠更大的模型和更多的算力来提升Agent表现。但Forge证明,在模型之上的"安全网"层做文章——修复解析、智能重试、步骤约束——效果可能比升级模型更显著,成本却低得多。
对一人公司来说,这个趋势是巨大的利好。过去"只有大公司才能做可靠Agent"的壁垒正在瓦解。一个会写Python的人+一台RTX 4090+Forge,就能搭建出可靠性接近商业API的Agent系统。这意味着:你不再被API供应商锁死,你可以把Agent部署在客户自己的服务器上,你的利润率不再是OpenAI定价的函数。
Forge目前有865个单元测试,支持Ollama、llama-server、Llamafile、Anthropic四种后端,Python 3.12+,MIT许可证。安装只需一行:pip install forge-guardrails。项目结构清晰,源码可读性高,非常适合作为学习AI Agent工程化的参考实现。
行动建议
- 今天就能试试:
pip install forge-guardrails+ 启动Ollama (ollama pull ministral-3:8b-instruct-2512-q4_K_M),跑通Quick Start里的天气查询示例(10行代码)。
- 明天可以做的事:把Forge代理指向你现有的AI工具(Continue/Cline/Aider),观察本地模型的输出质量是否明显提升。
- 本周值得投入的:写一个你自己的Workflow,定义2-3个工具,让Forge跑一个完整的Agent任务(如:搜索最新AI新闻→汇总→生成Markdown报告)。
- 如果没GPU:Forge也支持Anthropic API作为后端。你可以先用Claude跑通流程,等确认工作流成熟后再迁移到自托管。
本文由AI辅助创作,经人工审核编辑发布