
给模型40个工具让它自由发挥 = 崩溃。用状态机把每个阶段只暴露5个工具 = 本地13B模型也能过SWE-bench。Statewright用Rust写的确定性引擎,不是又一层LLM。
前言
如果你用过Claude Code、Cursor或Codex做实际开发,一定经历过这种绝望:让它改个bug,它先读了5遍同一个文件,然后试图在"计划阶段"直接编辑代码,改完了不测试就说"完成了"——最后你发现它不仅没修好bug,还引入了三个新的。
这不是模型不够聪明。是上下文太大、工具太多了。
Statewright给出了一个反直觉但有效的答案:不要用更大的模型,用更小的问题空间。这篇文章会带你从零搭建Statewright,看懂它怎么让本地13B模型从20%成功率飙升到100%,以及如何为你的团队定制自己的Agent工作流。
一、AI Agent的死穴:工具越多,越容易崩溃
先看一组真实数据。Statewright团队用5个SWE-bench任务测试了不同规格的模型:
| 模型 | 大小 | 无Statewright | 有Statewright |
|---|---|---|---|
| gemma3 | 3.3GB | 失败 | 失败 |
| gemma4:e2b | 7.2GB | 失败 | 部分通过* |
| gpt-oss:20b | 13.8GB | 2/5通过 | 5/5通过 |
| gemma4:31b | 19.9GB | 2/5通过 | 5/5通过 |
| llama3.3 | 42.5GB | - | 2/2通过 |
▲ SWE-bench成功率对比:13.8GB+模型在Statewright加持下从40%飙升至100%
*需要专门的edit_line工具适配
关键发现:13.8GB的模型(大致相当于13B参数级),不加状态约束只有40%成功率,加上后变成100%。同样的任务,同样的硬件,同样的模型。
为什么?因为当你给一个Agent 40+个工具(读文件、写文件、执行shell、搜索代码、调用API、管理git……),模型在每一步都要在40个选项中做决策。这40个选项的排列组合让搜索空间爆炸。模型开始"乱试"——读同一个文件5次、在计划阶段调用编辑工具、跳过测试直接宣告完成。
这不是"模型不够好",是"问题定义太大"。
二、Statewright的解法:状态机 = 把大海变游泳池
Statewright的核心思想就一句话:Agents are suggestions, states are laws。
它不是又一层LLM包装——它是一个用Rust写的确定性引擎。你定义好状态机定义(states、transitions、guards、tool restrictions),它在每个状态下只暴露该状态下允许的工具,强制执行规则。
工作流拆解示例:bugfix
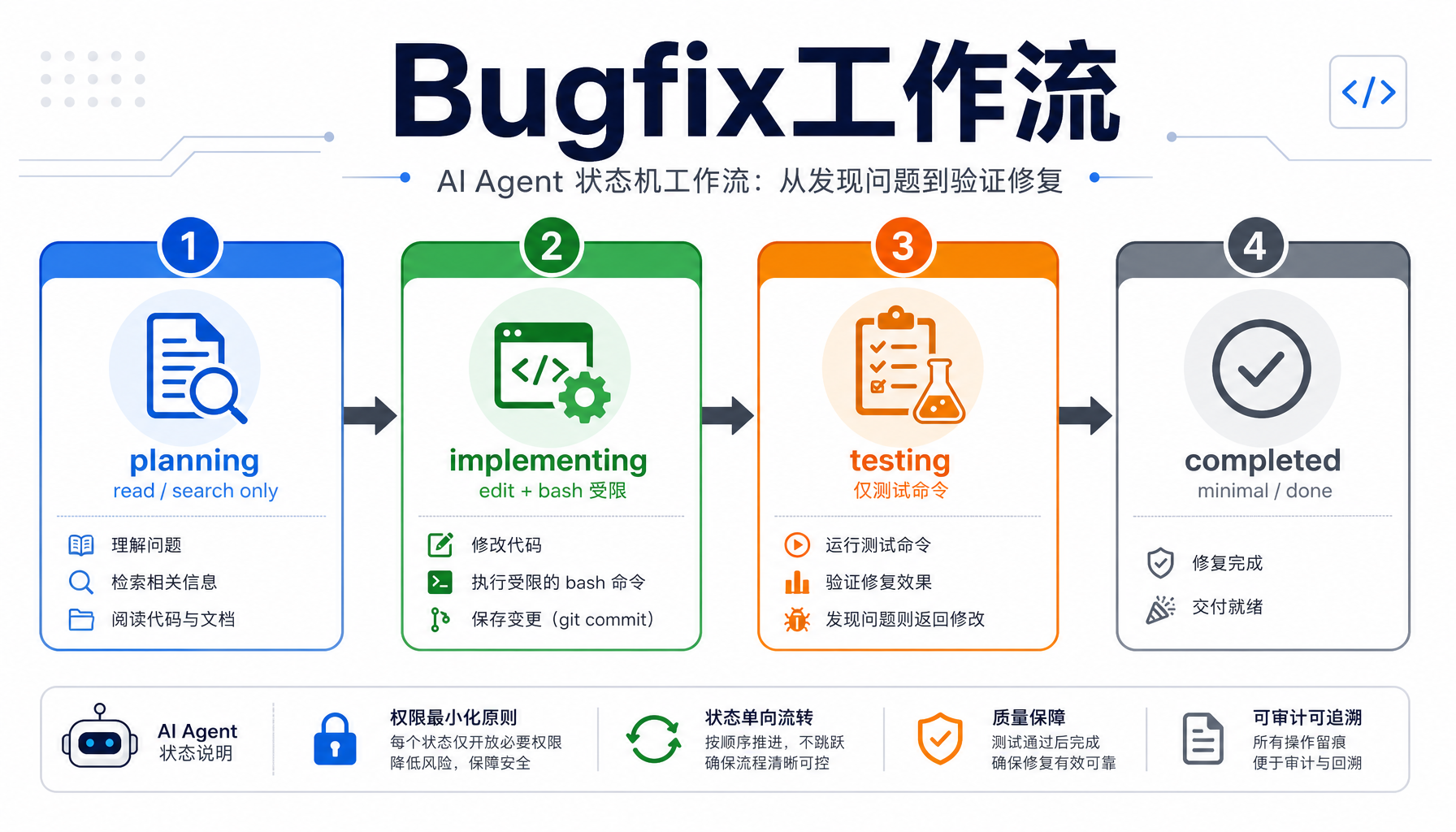
最经典的bugfix工作流被拆成四个状态:
每个状态只给特定工具:
| 状态 | 可用工具 | 禁止的操作 |
|---|---|---|
| planning | read_file, search_code, grep | 任何编辑操作、shell命令 |
| implementing | edit_file, read_file, bash(受限) | rm、shred、重定向写入(>>) |
| testing | bash(仅测试命令) | 任何编辑操作、非测试命令 |
| completed | 无 | 全部锁定 |
关键机制:如果你在planning状态调用edit_file,你不会得到"建议你不要这样做"的提示——你会得到硬拒绝,同时引擎告诉你:"当前状态不支持此工具。可用工具:read_file, search_code, grep。要进入编辑状态,请调用statewright_transition。"
这就是"States are laws"的真正含义——不是建议,不是提示词里的"请遵守规则",而是工具层面的硬阻断。

▲ 各状态工具权限矩阵:planning只读 → implementing编辑受限 → testing仅测试命令 → completed锁定
三、5分钟上手:在Claude Code中安装Statewright
▲ Statewright状态机工作流:planning→implementing→testing→completed,每个状态严格限定可用工具
前提条件
- Claude Code 已安装
- 一个Statewright账号(免费层可用)
步骤1:安装插件
在Claude Code终端中执行:
执行后会自动打开浏览器,引导你注册Statewright账号并生成API Key。
步骤2:启动你的第一个工作流
用bugfix工作流修复calc.py中的测试失败:
步骤3:观察发生了什么
上面的输出里有几个关键点:
- planning阶段只读文件——Agent先读了
calc.py和test_calc.py,定位到第47行的除零问题。此时它没有编辑权限,所以不会"手痒"直接改代码。 - 明确的状态转换——
planning => implementing。Agent必须显式调用statewright_transition(READY)才能进入下一阶段。 - 编辑受限——implementing阶段只改了1行(加了ZeroDivisionError处理),不是大范围重写。
- 强制测试——implementing完成后必须进入testing阶段,运行
pytest -x验证。
整个流程46秒完成。对比无约束情况下Agent可能花3分钟反复读文件、乱改代码、忘记测试。
四、自定义工作流:创建你自己的状态机
Statewright的真正威力在于自定义工作流。你可以为团队的特定场景创建专属状态机。
工作流定义格式
一个完整的工作流用JSON定义,包含状态、转换、工具权限和守卫条件:
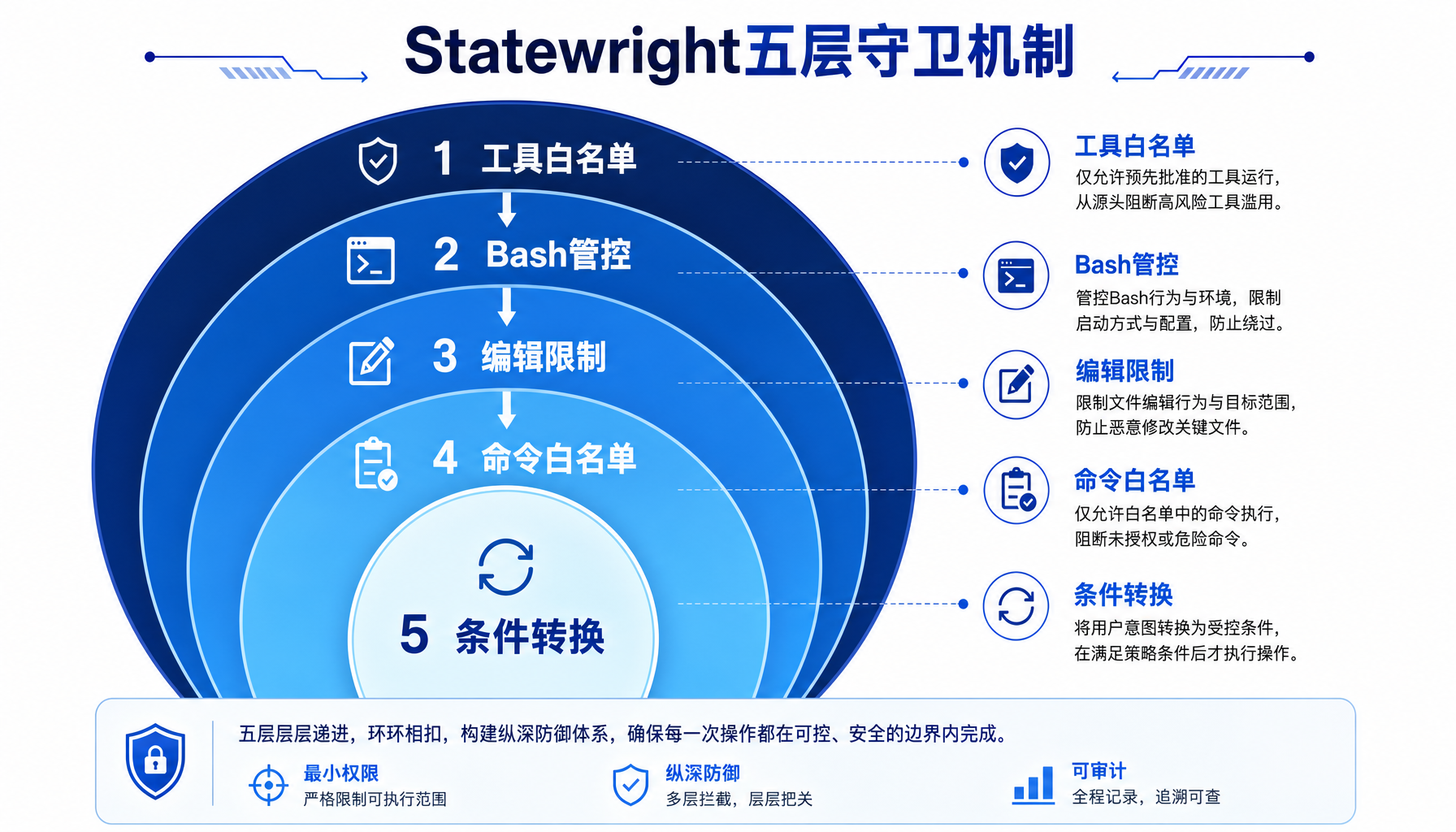
五层守卫机制
Statewright提供五种硬守卫,组合使用可以覆盖绝大部分Agent失控场景:
| 守卫类型 | 作用 | 使用场景 |
|---|---|---|
工具白名单 (allowed_tools) | 每个状态只暴露指定工具 | 防止planning阶段编辑代码 |
| Bash管控 | 禁止销毁命令(rm/shred)、重定向写入、脚本解释器 | 防止Agent误删文件 |
编辑限制 (max_edit_lines, max_files_edited) | 限制单状态编辑行数和文件数 | 防止Agent"大改特改" |
命令白名单 (allowed_commands) | 前缀匹配允许的shell命令 | testing阶段只允许pytest/npm test |
条件转换 (guard) | 程序化前置条件 | "必须读过至少1个文件才能进入review" |

▲ Statewright五层守卫机制:从工具白名单到条件转换,同心圆式层层防护
实战示例:API开发工作流
假设你的团队需要Agent帮忙开发REST API端点:
注意一个关键设计:test状态有两个出边——测试通过进入docs,测试失败回到implement。这就是状态机比DAG更适合Agent场景的原因:Agent工作天然需要循环和重试。
预期输出示例
当你用这个工作流让Agent开发一个 /users/:id 端点时:
重点:注意中间的失败→重试循环。Agent第一次实现时忘了处理User.DoesNotExist异常,测试失败后自动回到implement修复,再测通过后进入docs。这个重试循环是状态机自动管理的,不需要你手动告诉Agent"再改一次"。
五、踩坑提醒:使用Statewright必须知道的5件事
⚠️ 坑1:缓存失效导致成本上升
每次状态转换时工具列表会变化,这可能触发模型提供商的prompt缓存失效。在长会话中(如30+次工具调用),token成本可能比无状态约束高出10-20%。
对策:对于简单任务(如单文件小改动),不需要Statewright。只在复杂多步骤工作流中使用。HN社区建议:任务超过5次工具调用时再启用。
⚠️ 坑2:流程过僵会扼杀创造力
Statewright的设计哲学是"先约束,再放宽"。但如果你把状态机设计得太死——比如每个状态只允许2种工具、转换条件极其严格——Agent可能会因为无法完成某个微小动作而卡住,反复在状态之间跳转而没有任何进展。
对策:从宽松开始。先给每个状态6-8个工具,运行几轮后根据实际"乱用工具"的日志来收紧。不要一上来就"每个状态只给2个工具"。
⚠️ 坑3:与MCP工具的兼容性问题
Statewright通过MCP协议与Agent通信。如果你的Agent已经在用其他MCP服务器(如文件搜索、数据库查询),需要确保工具名称不冲突。Statewright会注入自己的MCP工具(statewright_start, statewright_get_state, statewright_transition),这些名称是保留的。
对策:检查你的MCP配置,确保没有自定义工具用了statewright_前缀。
⚠️ 坑4:本地模型的"能力地板"
研究数据明确显示:13GB以下的模型即使在Statewright约束下也无法可靠完成任务。不是因为状态机不好,而是模型连基本的"读懂文件内容并生成准确编辑"都做不到。
对策:本地模型至少13GB(≈13B参数)。低于这个门槛,先用云端模型。
⚠️ 坑5:API Key的"粘贴两次"问题
最新版本的Claude Code可能会在你粘贴API Key时警告安全问题——你只需要再粘贴一次并确认"我确实要这样做"。这不是Statewright的问题,是Claude Code对来自外部插件的敏感操作过度保护。HN上有多个用户报告了同样的体验。
六、Statewright vs 竞品:什么时候用它,什么时候不用
| 方案 | 原理 | 适用场景 | 局限 |
|---|---|---|---|
| Statewright | Rust确定性状态机+工具拦截 | 多步骤开发/部署/审核流程 | 需要预先定义工作流 |
| 提示词约束 | 在system prompt中写规则 | 简单任务、单步骤操作 | 模型经常忽略长prompt中的规则 |
| 可观测性工具 | 事后记录+分析 | 调试、性能分析 | 不能防止错误发生 |
| 更大模型 | 指望模型自己"更聪明" | 探索性任务、创意工作 | 成本高、仍有不确定性 |
选择指南:
- 任务有明确的步骤和交付物 → Statewright
- 任务是探索性的、没有固定流程 → 不要用Statewright,用更大的模型+事后审查
- 任务简单(3步以内)→ 提示词约束就够了
七、生产环境部署建议
团队共享工作流
Statewright支持将工作流定义导出为JSON文件,可以通过Git管理:
CI/CD集成
可以将Statewright作为CI流水线的一部分,强制执行代码审查和测试:
总结
Statewright解决的不是"模型不够聪明"的问题,而是"模型被太多选择淹没"的问题。它的核心洞察简单而深刻:缩小每一步的决策空间 = 大幅提升每一步的决策质量。
三个最值得记住的数字:
- 13.8GB模型 + 状态机 = 5/5 SWE-bench通过(无状态机:2/5)
- 46秒:一个完整的bugfix工作流(定位→修复→测试→完成)
- 5种守卫:工具白名单、Bash管控、编辑限制、命令白名单、条件转换——组合使用覆盖绝大部分Agent失控场景
对于AI创业者来说,这不是一个工具选择问题,而是一个架构决策:你的Agent流水线是用"一个超大prompt管一切",还是"每个阶段精准控制工具和权限"?前者看起来简单,后者才是工程上的正确解。
#AI创业 #Agent工坊 #Statewright #状态机 #AI编程工具 #一人公司
本文由AI辅助创作,经人工审核编辑发布