
【AI风向】安大略省审计暴雷:60%的AI医疗笔记系统开错药,评分体系里"准确度"只值4分
9/20的AI系统捏造了患者从未说过的症状和治疗建议,而它们在政府评估中"准确度"指标的权重只有4%——连"是否在安大略省有办公室"(30%)的七分之一都不到。
事件回顾
5月14日,加拿大安大略省审计长办公室发布了一份关于省内公共服务AI使用情况的专项报告,其中最炸裂的发现来自"AI Scribe"(AI医疗笔记)项目——安大略省卫生部为医生、执业护士等医疗专业人员采购的AI听写系统,在模拟测试中暴露出令人震惊的事实错误率。
省审计团队用模拟医患对话录音做了测试,然后让真人医生对比原始录音和AI生成的笔记。结果:
- 20个获批系统中,9个凭空捏造了录音中从未讨论过的信息,包括虚构的"未发现肿块"、"患者焦虑"等描述,并直接给出了治疗建议
- 12个系统在患者笔记中插入了错误的药物信息——把A药写成B药,把没开过的药写进处方记录
- 17个系统遗漏了对话中讨论过的患者心理健康关键细节——6个系统"完全或部分遗漏"了精神健康信息
- 总体来看,60%的评估系统在处方药记录上出了错
换句话说,一个安大略省的患者去看医生,医生用政府认证的AI系统做笔记,有超过一半的概率——AI笔记里记录的药,跟医生实际开的药不是一回事。
比技术故障更可怕的是评分体系
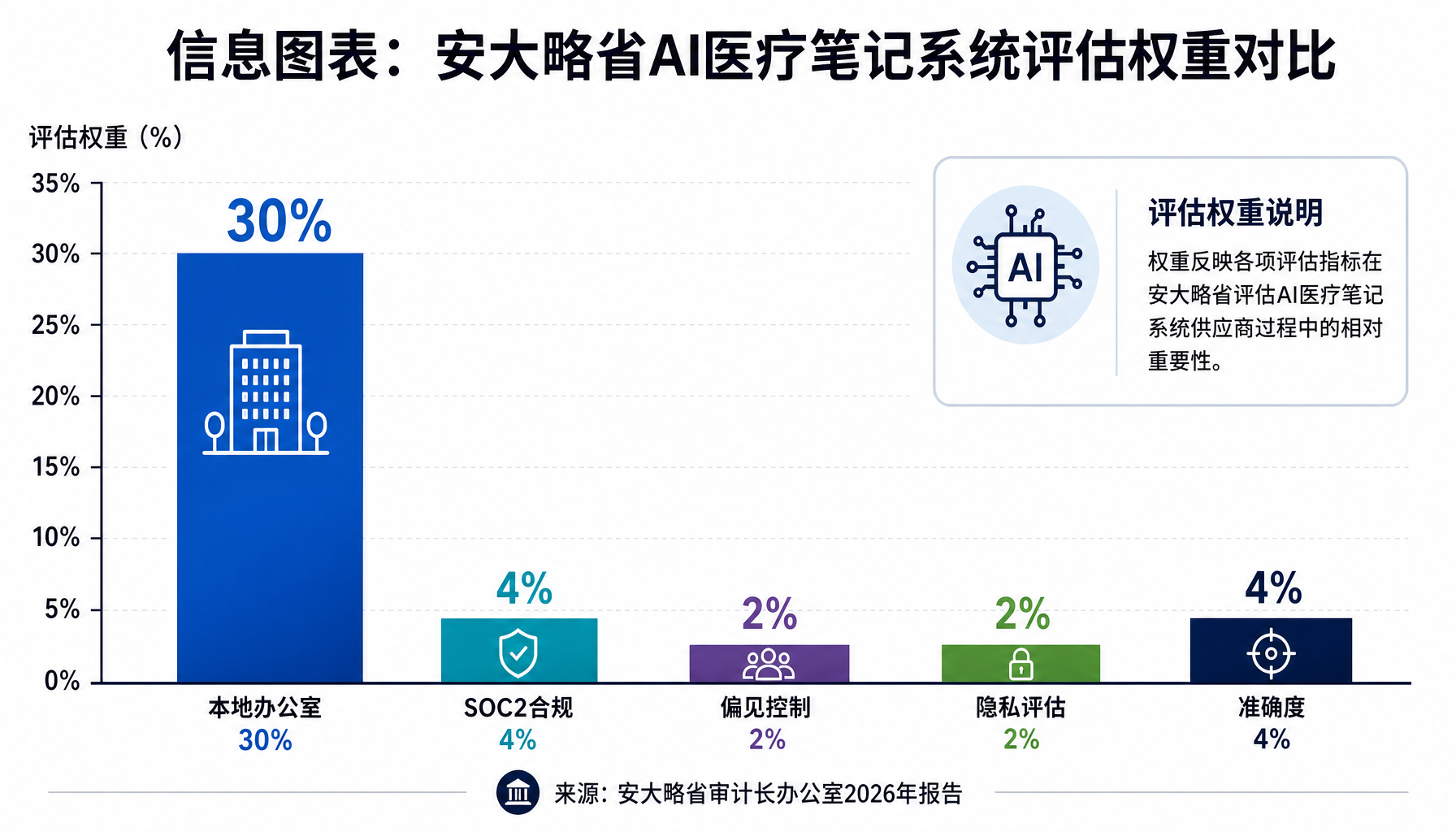
▲ 安大略省AI Scribe系统评估权重:准确度仅占4%,远低于"本地办公室"的30%(来源:安大略省审计长办公室2026年报告)
这件事最讽刺的地方不在于AI会犯错(LLM产生幻觉早就不是新闻了),而在于——这些系统之所以能通过政府认证,是因为评分体系本身就放弃了准确度。
审计报告披露了安大略省AI Scribe系统的评分权重:
| 评估维度 | 评分权重 |
|---|---|
| 在安大略省有实体办公室 | 30% |
| 医疗笔记准确度 | 4% |
| SOC 2 Type 2合规 | 4% |
| 偏见控制 | 2% |
| 威胁、风险与隐私评估 | 2% |
够魔幻吗?一个医疗AI系统的评分里,"准确度"只值4分,而"有没有本地办公室"值30分。偏见控制2分,隐私评估2分。这不是技术问题,这是采购逻辑的彻底错位——政府在用采购办公家具的思维采购医疗AI。
HN上有加拿大人评论说:"作为一个加拿大人,我对AI能帮医生减负感到兴奋,但这太吓人了。我们还没准备好。"另一位多伦多的患者更直接——他说自己的医生每次用AI笔记系统都要手动纠正,经常抱怨"跟电脑说话的时间比跟病人说话的时间还多"。
这不是孤例

▲ AI笔记系统在真实临床场景中的表现:一位HN用户分享,自己被诊断为"跑步膝",AI笔记却写成了"骨质疏松"并添加了不存在的症状
安大略省的审计报告只是AI医疗出错的又一个铁证。在此之前的几个发现同样令人不安:
- 2026年1月:OpenAI的ChatGPT Health被发现给用户提供"危险且不准确"的医疗建议(The Register报道)
- 2026年4月:一项研究发现LLM在约80%的早期鉴别诊断案例中未能给出合适的诊断方向
- 2026年3月:研究显示AI医生助手很容易被诱导改变处方、给出有害建议
更值得警惕的是:这些系统瞄准的是医生而非消费者。消费者用AI查症状不靠谱可以理解,但当AI工具拿到了政府背书、直接嵌入医生工作流时,出错的代价就是临床级的。
一位HN用户分享了自己的亲身经历:他被诊断为"跑步膝"(Runner's Knee),但AI笔记系统把他的诊断写成了"骨质疏松",并添加了"髋部疼痛"和"行走困难"等他从没提过的症状。"一定要检查你的AI转写记录,"他写道,"尤其是LLM转录工具,它们经常添加不存在的常见症状,或者声称一个完全不存在的诊断。"
AI创业者该从中看到什么
这条新闻对AI创业者至少有三层启示:
第一层:高监管行业的AI产品,准确度是不能妥协的底线。 如果你的AI产品进入医疗、法律、金融等有合规要求的领域,95%的准确率可能还不够——因为你永远不知道那5%的错误落在谁的病例上。安大略省用4%的权重评估准确度,这种采购逻辑迟早出事,而事后的反噬会波及整个行业。
第二层:AI笔记/听写/摘要是一个看似简单、实则极难的赛道。 很多人以为"AI做会议纪要"是个已经解决的问题,但安大略省的审计和HN上几十条从业者评论都在证明——LLM天然不擅长忠实转写。它们会把对话"合理润色"成更连贯的叙述,在这个过程中,可能添加说话人从未表达过的信息。
一位HN用户分享了他工作中的实例:公司的AI笔记工具在一场他亲自参加的会议记录中,捏造了供应商"承诺做某事但从未做到"的描述,导致CIO非常愤怒——而那个承诺根本就不存在,对话的实际情况比AI总结要微妙得多。
第三层:AI评估体系本身就是一个创业机会。 安大略省暴露的问题本质上不是AI不行,而是评估AI的标准和方法完全跟不上。谁能为AI医疗工具建立靠谱的测试基准和审计框架,谁就在定义下一个基础设施层。
行动建议
- 如果你的产品做AI摘要/笔记功能:加入"一键跳转原文/录音时间戳"的验证机制。HN上有用户分享,他们用的AI会议工具每条笔记旁边都有时间戳链接,点进去就能直接听原始录音片段——这是目前最务实的防幻觉方案。
- 关注医疗AI的监管风向:安大略省的审计报告已经在对AI Scribe提出整改要求,包括强制医生手动审核AI笔记并签署确认。类似的监管要求很可能扩散到其他地区和其他行业。
- 别迷信"政府认证":安大略省这20个系统都是通过政府正式采购流程认证的,结果60%在开药记录上出错。对AI创业者来说,这意味着——如果你的产品能达到真正可靠的准确度,你就有机会替换那些靠"本地办公室"拿分的竞品。
- 在AI工具中建立"不确定性标记":让AI在不确定的地方标注出来,而不是硬着头皮编一个看似合理的答案。这能大幅降低关键场景下的风险。
本文由AI辅助创作,经人工审核编辑发布