MCP 正在成为 AI Agent 工具调用的统一标准——2026 年 7 月即将发布 stateless 协议和 MCP Apps 扩展。现在学会构建 MCP Server,就是提前卡位 AI Agent 生态的基础设施层。
 ▲ ▲ MCP 三层架构:Host → Client → Server,STDIO 与 HTTP 双传输模式
▲ ▲ MCP 三层架构:Host → Client → Server,STDIO 与 HTTP 双传输模式
为什么你需要学会构建 MCP Server
如果你用过 Claude Code、Hermes Agent、Cursor 或 VS Code 的 AI 功能,你一定见过这样的场景:AI 说自己会帮你查天气、搜网页、读文件——但它背后调用的不是魔法,而是 MCP Server。
MCP(Model Context Protocol,模型上下文协议)是 Anthropic 于 2024 年底发布的开放协议,目前已由 Agentic AI Foundation(AAIF)托管。它的核心逻辑极其简洁:定义一套 JSON-RPC 2.0 通信规范,让 AI 应用(Host)能通过统一的接口调用外部工具(Server)。
截至 2026 年 6 月,MCP 生态已有超过 800 个开源 Server 实现,覆盖从文件系统、数据库查询到 Slack 消息、GitHub PR 管理等几乎所有常见工具。Claude Desktop、Claude Code、VS Code、Hermes Agent 等主流 AI 应用都已原生支持 MCP。
但真正有价值的是:构建你自己的 MCP Server。 假设你是一个 SaaS 创业者,你的产品有一个 REST API。与其让用户登录后台手动操作,不如写一个 MCP Server,让用户的 AI Agent 直接调用你的 API。这才是 2026 年 AI 产品分发的新范式。
本文带你用 Python 从零构建一个可用的 MCP Server,包含完整代码、测试方法和 5 个真实踩坑记录。
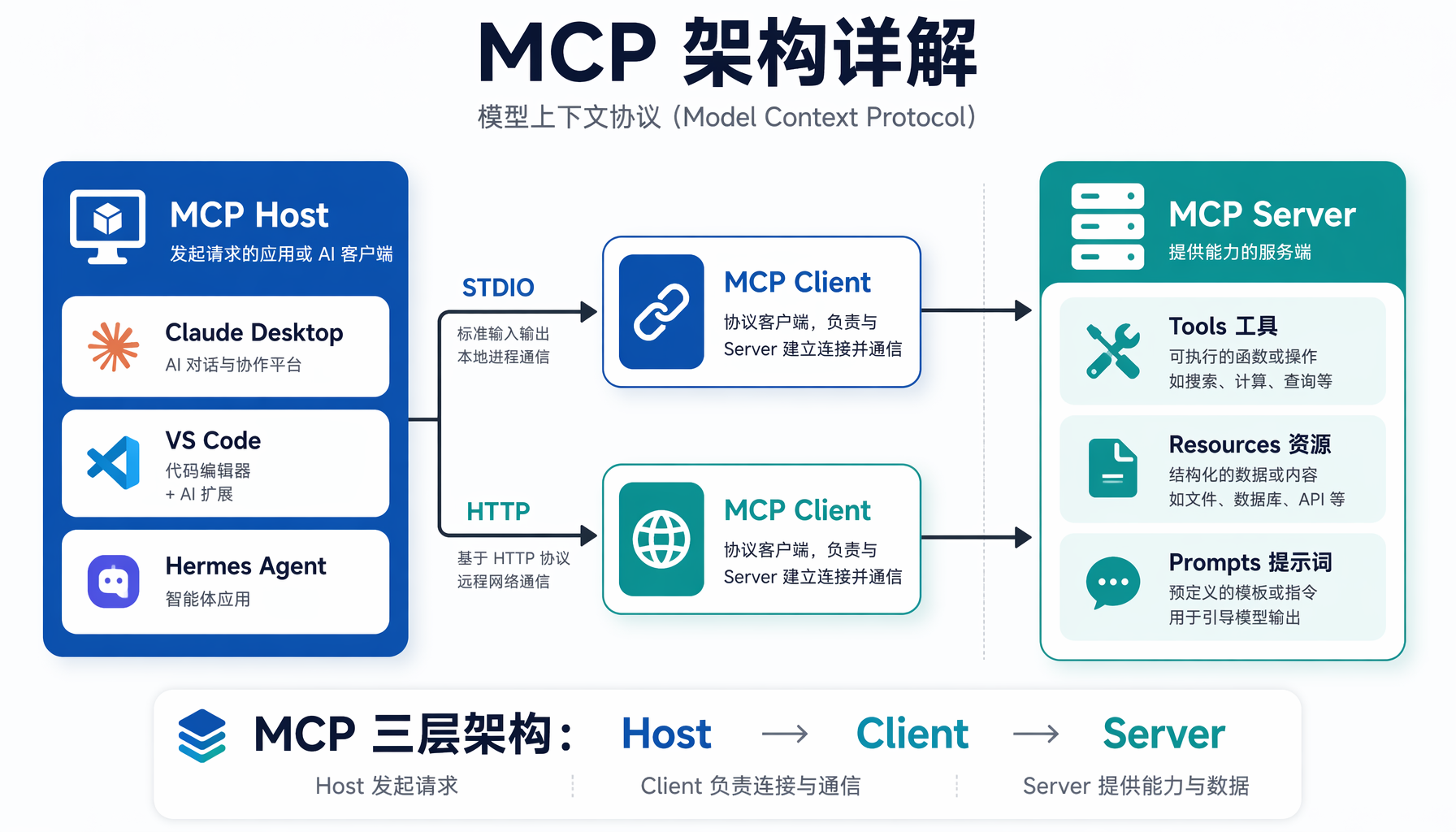
MCP 架构:30 秒看懂
MCP 采用经典的三层客户端-服务器架构:
┌─────────────────────────────────┐
│ MCP Host │
│ (Claude Desktop / VS Code / │
│ Hermes Agent / Cursor) │
│ │
│ ┌──────────┐ ┌──────────┐ │
│ │MCP Client│ │MCP Client│ │
│ │(STDIO) │ │(HTTP) │ │
│ └────┬─────┘ └────┬─────┘ │
└───────┼──────────────┼──────────┘
│ │
┌────▼─────┐ ┌───▼──────────┐
│ 本地 MCP │ │ 远程 MCP │
│ Server │ │ Server │
│ (STDIO) │ │ (HTTP/SSE) │
└──────────┘ └──────────────┘
三个关键角色:
- MCP Host:你正在使用的 AI 应用(Claude Desktop、VS Code 等)。它负责管理多个 MCP Client 实例。
- MCP Client:Host 内部维护的与单个 MCP Server 的连接。一个 Server 对应一个 Client。
- MCP Server:提供具体能力的程序——可以暴露工具(Tools)、资源(Resources)、提示模板(Prompts)。
两种传输方式:
- STDIO 传输:Server 作为子进程运行,通过标准输入/输出与 Client 通信。适合本地工具。
- Streamable HTTP 传输:Server 作为独立 HTTP 服务运行,支持多客户端并发。适合远程 SaaS 工具。
关键认知:MCP 只定义"怎么传数据",不限制"传什么数据"。你的 Server 可以是查询数据库、调用第三方 API、操作浏览器——任何你希望 AI 能做的事情。
实战:构建一个 SEO 分析 MCP Server
我们来构建一个实用的例子——SEO 分析 MCP Server,让 AI 能帮用户分析网页的 SEO 表现。这个 Server 暴露两个工具:
get_page_title:获取网页标题analyze_meta:分析网页的 meta 标签(description、keywords、og 标签)
环境准备
# 安装 uv(Python 包管理器)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 创建项目
uv init seo-mcp-server
cd seo-mcp-server
# 创建虚拟环境
uv venv
source .venv/bin/activate
# 安装依赖
uv add "mcp[cli]" httpx beautifulsoup4
完整代码
创建 server.py:
"""
SEO 分析 MCP Server
提供网页标题提取和 Meta 标签分析两个工具
"""
from typing import Any
import httpx
from bs4 import BeautifulSoup
from mcp.server.fastmcp import FastMCP
# 初始化 FastMCP server
mcp = FastMCP("seo-analyzer")
# 常量配置
USER_AGENT = "seo-mcp-server/1.0 (AI Agent Tool)"
REQUEST_TIMEOUT = 15.0 # 秒
async def fetch_page(url: str) -> str:
"""获取网页 HTML 内容"""
headers = {"User-Agent": USER_AGENT}
async with httpx.AsyncClient(timeout=REQUEST_TIMEOUT) as client:
response = await client.get(url, headers=headers, follow_redirects=True)
response.raise_for_status()
return response.text
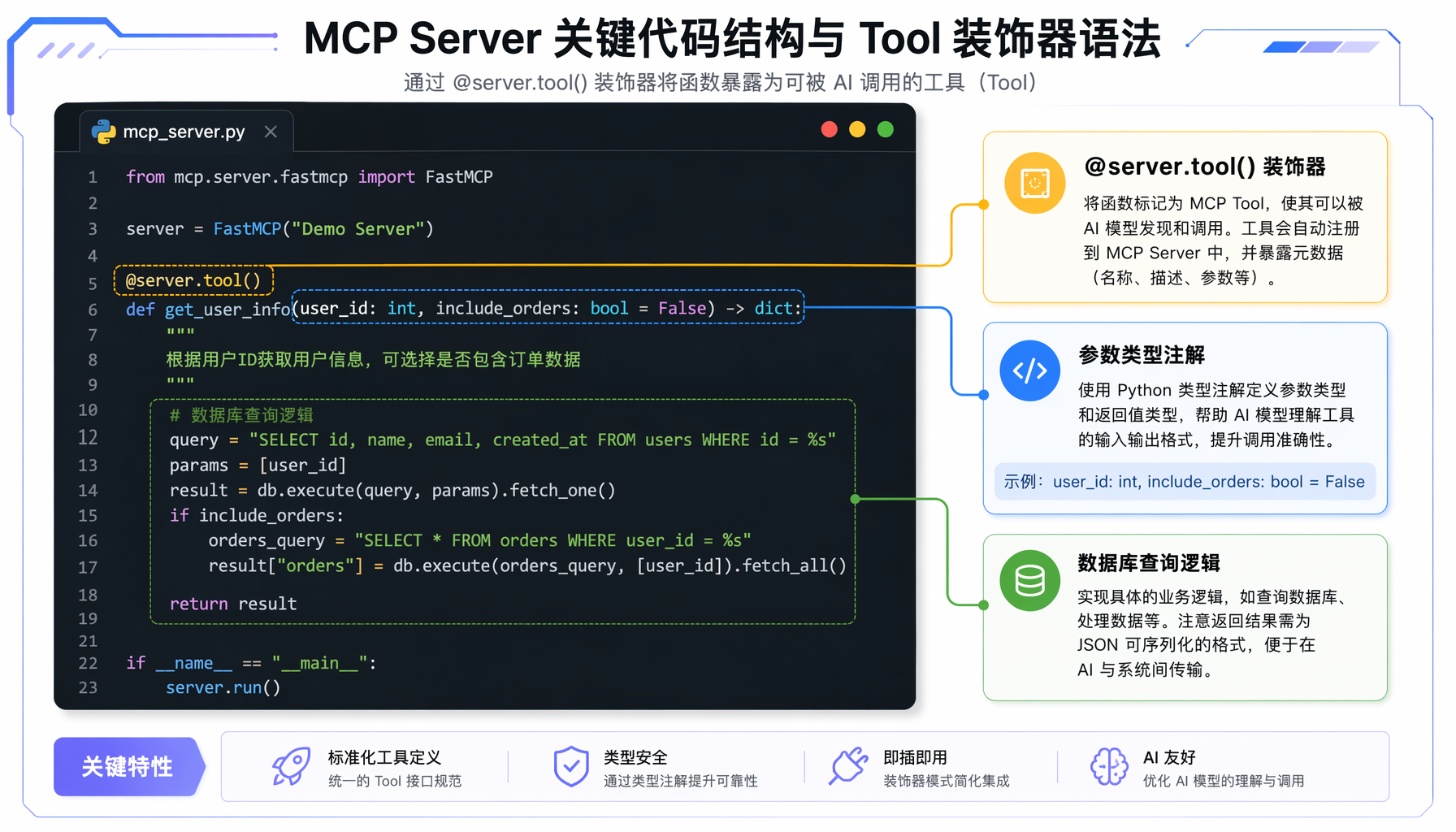
@mcp.tool()
async def get_page_title(url: str) -> str:
"""获取指定网页的标题(title 标签内容)
Args:
url: 要分析的网页完整 URL(含 https://)
Returns:
网页标题字符串,如果无法获取则返回错误信息
"""
try:
html = await fetch_page(url)
soup = BeautifulSoup(html, "html.parser")
title = soup.title.string if soup.title else "(无标题)"
return f"✅ 网页标题:{title.strip()}"
except httpx.HTTPStatusError as e:
return f"❌ HTTP 错误:{e.response.status_code}"
except httpx.RequestError as e:
return f"❌ 请求失败:{str(e)}"
except Exception as e:
return f"❌ 解析错误:{str(e)}"
@mcp.tool()
async def analyze_meta(url: str) -> str:
"""分析网页的 SEO Meta 标签,包括 description、keywords、
Open Graph 标签和 viewport 设置。
Args:
url: 要分析的网页完整 URL(含 https://)
Returns:
格式化的 SEO 分析报告
"""
try:
html = await fetch_page(url)
soup = BeautifulSoup(html, "html.parser")
report_parts = ["📊 SEO Meta 分析报告", "=" * 40]
# 1. Description
desc = soup.find("meta", attrs={"name": "description"})
if desc and desc.get("content"):
desc_text = desc["content"]
desc_len = len(desc_text)
status = "✅" if 50 <= desc_len <= 160 else "⚠️"
report_parts.append(
f"\n{status} Description ({desc_len} 字符):{desc_text[:100]}..."
)
else:
report_parts.append("\n❌ Description:缺失(严重影响 SEO)")
# 2. Keywords
keywords = soup.find("meta", attrs={"name": "keywords"})
if keywords and keywords.get("content"):
report_parts.append(f"📌 Keywords:{keywords['content'][:100]}")
else:
report_parts.append("⚠️ Keywords:未设置(现代 SEO 中权重较低)")
# 3. Open Graph 标签
og_title = soup.find("meta", property="og:title")
og_desc = soup.find("meta", property="og:description")
og_image = soup.find("meta", property="og:image")
report_parts.append("\n--- Open Graph 标签 ---")
report_parts.append(
f"{'✅' if og_title else '❌'} og:title:"
f"{og_title['content'][:60] if og_title else '缺失'}"
)
report_parts.append(
f"{'✅' if og_desc else '❌'} og:description:"
f"{og_desc['content'][:60] if og_desc else '缺失'}"
)
report_parts.append(
f"{'✅' if og_image else '❌'} og:image:"
f"{og_image['content'][:60] if og_image else '缺失'}"
)
# 4. Viewport(移动端适配)
viewport = soup.find("meta", attrs={"name": "viewport"})
report_parts.append(
f"\n{'✅' if viewport else '❌'} Viewport:"
f"{'已设置' if viewport else '缺失(影响移动端 SEO)'}"
)
# 5. Canonical URL
canonical = soup.find("link", rel="canonical")
if canonical and canonical.get("href"):
report_parts.append(f"🔗 Canonical:{canonical['href'][:80]}")
return "\n".join(report_parts)
except httpx.HTTPStatusError as e:
return f"❌ HTTP {e.response.status_code}:无法访问该页面"
except httpx.TimeoutException:
return f"❌ 请求超时(>{REQUEST_TIMEOUT}秒),页面响应过慢"
except Exception as e:
return f"❌ 分析失败:{str(e)}"
if __name__ == "__main__":
# 使用 STDIO 传输运行(Claude Desktop / Hermes Agent 标准方式)
mcp.run(transport="stdio")
本地测试
写完 Server 后,先用 MCP Inspector 测试:
# 安装 MCP Inspector(一次性)
npx @modelcontextprotocol/inspector
# 在另一个终端启动 Server 的 Inspector 模式
mcp dev server.py
MCP Inspector 会在浏览器中打开 UI 中直接调用 get_page_title 和 analyze_meta 两个工具,查看输入输出。
测试示例输出:
调用 analyze_meta,参数 `url = "
📊 SEO Meta 分析报告
========================================
✅ Description (155 字符):Example Domain. This domain is for use in...
📌 Keywords:(未设置)
--- Open Graph 标签 ---
❌ og:title:缺失
❌ og:description:缺失
❌ og:image:缺失
✅ Viewport:已设置
🔗 Canonical:https://example.com/
 ▲ ▲ Python FastMCP 代码与 SEO 分析输出:定义工具 → AI 自动调用
▲ ▲ Python FastMCP 代码与 SEO 分析输出:定义工具 → AI 自动调用
接入 Claude Desktop
在 Claude Desktop 的配置文件 claude_desktop_config.json 中添加:
{
"mcpServers": {
"seo-analyzer": {
"command": "uv",
"args": [
"--directory",
"/path/to/seo-mcp-server",
"run",
"server.py"
]
}
}
}
重启 Claude Desktop 后,在对话中直接说"分析 example.com 的 SEO meta 标签",Claude 会自动调用你的 MCP Server。
接入 Hermes Agent
Hermes Agent 从 v0.12.0 开始原生支持 MCP。在 Hermes 的配置中添加:
hermes mcp add seo-analyzer -- uv --directory /path/to/seo-mcp-server run server.py
hermes gateway restart
5 个真实踩坑记录
踩坑 1:STDIO Server 中用 `print()` 调试——直接炸掉通信
症状:Server 启动后,Client 连接立即断开,日志里出现 JSON parse error。
根因:STDIO 传输模式下,stdout 是 JSON-RPC 消息的唯一通道。任何 print() 输出都会混入 JSON 流,导致 Client 解析失败。
正确做法:
# ❌ 错误:直接用 print 调试
print("收到请求,正在处理...")
# ✅ 正确:写到 stderr 或用 logging 模块
import sys
print("收到请求,正在处理...", file=sys.stderr)
# ✅ 更好:用标准 logging
import logging
logging.basicConfig(level=logging.INFO, stream=sys.stderr)
logging.info("收到请求,正在处理...")
踩坑 2:类型注解不完整导致工具注册失败
症状:MCP Inspector 里看不到你定义的工具。
根因:FastMCP 依赖 Python 类型注解来自动生成工具的 JSON Schema。如果函数参数没有类型注解,或返回类型缺失,工具可能注册失败或被跳过。
正确做法:
# ❌ 缺失类型注解
@mcp.tool()
async def my_tool(url): # 没有类型注解
...
# ✅ 完整类型注解
@mcp.tool()
async def my_tool(url: str) -> str: # 参数和返回值都有类型
"""工具描述(会作为 tool description 传给 LLM)"""
...
踩坑 3:HTTP Client 复用导致连接泄漏
症状:Server 运行一段时间后内存持续增长,最终 OOM。
根因:在 @mcp.tool() 函数内部创建 httpx.Client() 对象,但没有正确关闭。每次工具调用都创建新连接池。
正确做法:
# ❌ 错误:每次调用创建新 Client
@mcp.tool()
async def fetch_data(url: str) -> str:
async with httpx.AsyncClient() as client: # 每次都新建
...
# ✅ 正确:用单例或模块级 Client
_client: httpx.AsyncClient | None = None
async def get_client() -> httpx.AsyncClient:
global _client
if _client is None:
_client = httpx.AsyncClient(
timeout=15.0,
limits=httpx.Limits(max_connections=10)
)
return _client
 ▲ ▲ 5 个 MCP 开发常见踩坑:print 禁用、类型注解、连接泄漏、工具描述、HTTP 握手
▲ ▲ 5 个 MCP 开发常见踩坑:print 禁用、类型注解、连接泄漏、工具描述、HTTP 握手
踩坑 4:工具描述写得太简单,LLM 不会用
症状:AI 从不主动调用你的工具,或者调用时参数给错。
根因:@mcp.tool() 装饰的函数 docstring 就是传给 LLM 的 tool description。LLM 完全依赖这个描述来决定"是否调用"和"传什么参数"。描述模糊 = 工具永远不会被使用。
正确做法:
# ❌ 太简单,LLM 不知道什么时候用
@mcp.tool()
async def analyze(url: str) -> str:
"""分析网页"""
...
# ✅ 详细描述:什么时候用、参数含义、返回值格式
@mcp.tool()
async def analyze_page_seo(url: str) -> str:
"""分析指定网页的 SEO 表现,包括 meta 标签完整性、
Open Graph 社交分享标签、移动端适配情况。
适用场景:用户询问"这个网页 SEO 怎么样"或
"帮我看看这个网站的 meta 标签"时使用。
Args:
url: 完整网页 URL,必须以 https:// 开头
"""
...
踩坑 5:本地开发 OK,远程部署后工具不出现
症状:STDIO 模式本地测试一切正常,但改成 HTTP 模式部署到服务器后,Client 连上了但工具列表为空。
根因:HTTP 传输模式下,MCP Server 需要先完成 initialize 握手,才会暴露工具列表。如果 Server 的 CORS 配置不正确,或者 Client 的 initialize 请求被中间件拦截,握手失败会导致工具列表为空。
排查方法:
# 用 curl 手动测试 initialize 握手
curl -X POST https://your-server.com/mcp \
-H "Content-Type: application/json" \
-d '{
"jsonrpc": "2.0",
"id": 1,
"method": "initialize",
"params": {
"protocolVersion": "2025-11-25",
"capabilities": {},
"clientInfo": {"name": "test", "version": "1.0"}
}
}'
# 成功后继续请求工具列表
curl -X POST https://your-server.com/mcp \
-H "Content-Type: application/json" \
-d '{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/list",
"params": {}
}'
MCP 2026 路线图:你需要关注的三件事
1. Stateless 协议(2026-07-28 RC)
当前 MCP 协议要求 Client 和 Server 之间维持会话状态。即将发布的 release candidate 将协议改为无状态——同一个 Client 可以连接到任意 Server 实例,不再需要 session affinity。这对于需要弹性伸缩的 SaaS MCP Server 来说是重大利好。
2. MCP Apps——Server 自带 UI
MCP Apps 扩展(SEP-1865)允许 Server 附带 HTML 界面,Host 在沙箱 iframe 中渲染。这意味着未来的 MCP Server 不只是返回文本——它可以返回一个完整的交互式仪表盘。想象你的 SEO 分析 Server 返回的可视化报告,而不是纯文本。
3. Extensions 成为一等公民
Extensions 框架让新能力以 opt-in 扩展的形式先发布、再稳定、最后才可能进入核心规范。Tasks 扩展(长运行任务)已经毕业。这意味着 MCP 生态的进化速度将大幅加快。
总结:现在就该动手
MCP 不是"又一个新的协议"——它是 AI Agent 工具层的 HTTP。就像每个 SaaS 产品都需要 REST API 一样,未来每个 SaaS 产品都可能需要一个 MCP Server。
行动清单:
- 今天:用本文代码跑通你的第一个 MCP Server
- 本周:把你最常用的内部工具包装成 MCP Server,接入 Claude Desktop
- 本月:关注 7 月 28 日的 MCP stateless 协议 RC,评估是否要将 Server 迁移到 HTTP 模式
- 季度:如果你的产品有 API,考虑发布官方 MCP Server 作为新的分发渠道
风险提示:MCP 规范仍在快速演进中(当前稳定版为 2025-11-25,下一个 RC 为 2026-07-28)。生产环境部署前请检查 SDK 版本与目标 Host 的协议版本兼容性。Python SDK 1.2.0+ 支持最新特性。
#AI创业 #Agent工坊 #MCP协议 #AI工具开发 #一人公司
本文由AI辅助创作,经人工审核编辑发布
