
结论反直觉:决定你能否用好 AI 编程助手的,不是你写了多少年代码,而是你对「要解决什么问题」理解多深。数据来自 Anthropic 官方刚发布的 40 万次 Claude Code 会话分析。
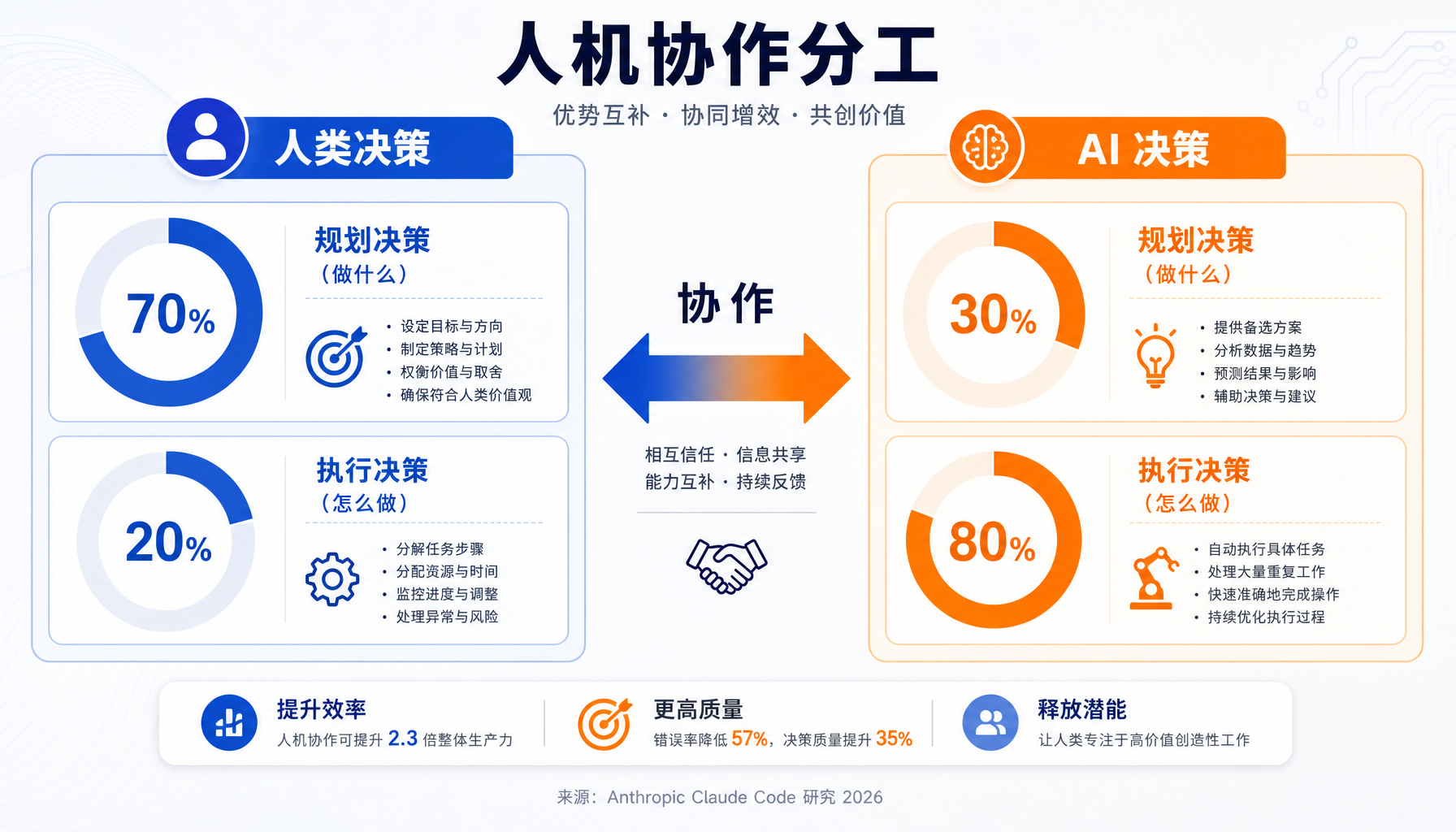
 ▲ 人机协作分工:人类做70%规划决策,AI承担80%执行决策
▲ 人机协作分工:人类做70%规划决策,AI承担80%执行决策
为什么你应该读这篇
Anthropic 在 2026 年 6 月 16 日发布了一份重磅研究报告《Agentic coding and persistent returns to expertise》——他们用隐私保护的方式分析了 2025 年 10 月到 2026 年 4 月间约 40 万次 Claude Code 真实会话、覆盖约 23.5 万名用户,量化了「不同背景的人用 AI 编程助手时,谁更成功、为什么成功」。
这份 16000+ 字的研究给出了一系列反直觉的结论,直接颠覆「程序员最擅长用 AI 写代码」的固有认知。对于 AI 创业者来说,这不仅仅是茶余饭后的谈资——它定义了你该如何构建团队、分配任务、设计工作流。
读完这篇,你将获得:
- 3 个可直接应用到日常 Agent 工作流的操作技巧
- 4 条来自真实数据的行为模式(能显著提升一次成功率)
- 一份从「新手→专家」的 Agent 使用升级路线图
Anthropic 如何定义「成功」
在展开之前,必须先理解 Anthropic 的判断标准——他们把一次会话定义为「已验证成功」的条件是:有可验证的证据表明用户达成了目标,比如测试通过、代码已提交。
这比「用户说好了」或「看起来没问题」要严格得多。而且在分类时,同一个律师用 Claude Code 写脚本自动检查合同条款的场景,会被归入「法律职业」而非「计算机职业」——这意味着他们刻意排除了「会写代码 = 程序员」的混淆。
九个工作模式分布
Anthropic 将每次会话归入九种模式之一:
| 模式 | 占比 | 说明 |
|---|---|---|
| 写新代码 | 25% | 从零构建功能 |
| 修 Bug | 26% | 调试和修复 |
| 测试与编排 | 5% | 测试代码、编排 Agent 流水线 |
| 运维操作 | 17% | 部署、配置、监控 |
| 规划与探索 | 14% | 理解系统、规划变更 |
| 分析与写作 | 13% | 数据分析、文档、演示 |
关键发现:修 Bug 的时间占比在七个月内下降了近一半,而端到端的 Agent 使用(部署运行代码、数据分析、写文档)在显著上升。这说明 AI Agent 正在从「帮你修代码」升级为「帮你做完整项目」。
核心发现一:决策分工 = 人定方向,AI 定执行
Anthropic 设计了一个精细的决策归因分类器:它会读出会话中所有「有意义的决策」,然后区分这些决策属于「规划」(做什么、用什么方法、什么叫完成)还是「执行」(改哪个文件、写什么代码、运行什么命令),再判断每个决策是人做的还是 AI 做的。
结果:
- 人类做了约 70% 的规划决策,但只做约 20% 的执行决策
- Claude 做了约 30% 的规划决策,承担约 80% 的执行任务
解读:这不是 AI「不擅长规划」,而是用户在使用过程中自然形成了分工——人告诉 Claude 要什么、Claude 自己决定怎么做到。典型的会话每轮有约 4 个回合,每个 prompt 触发 Claude 执行约 10 个操作,输出约 2400 词。
当用户把执行决策权交给 AI(让 AI 做超过 80% 的执行决策)时,AI 每次 prompt 会执行约 16 个操作。而当用户紧抓执行不放(自己做超过 80% 的执行决策)时,AI 每次只做约 8 个操作。
对 AI 创业者的启示:如果你把 Claude Code 当成「代码补全工具」来用——每行代码都要审核、每个函数名都要确认——你就是在限制它的生产力。高手的用法是:描述清楚你要什么结果,然后让它自己决定实现路径。
核心发现二:领域专长 > 编码能力
这是整个研究中最反直觉、对 AI 创业者最有价值的结论。
五级专长度量
Anthropic 用三个信号给每次会话的用户打专长分(1-5 级,从新手到专家):
- 指令精确度:用户描述需求时有多具体
- 验证要求的质量:用户让 Claude 验证什么(测试?边界情况?还是什么都不验证)
- 纠错方向:是用户纠正 Claude 更多,还是 Claude 纠正用户更多
关键洞察:专长是「任务特定」的,不是「职位特定」的。一个资深工程师第一次用 Rust,在这个 Rust 任务里是新手。一个从未用过 Python 的会计,但能精确描述对账规则、还能发现 Claude 处理漏了月末结账的边界情况——她在这个财务核对任务上是专家。
 ▲ 专家vs新手:每个prompt触发12个vs5个操作,输出量差距5.3倍
▲ 专家vs新手:每个prompt触发12个vs5个操作,输出量差距5.3倍
数据说话
- 新手会话:每个 prompt 触发约 5 个 Claude 操作,约 600 词输出
- 专家会话:每个 prompt 触发约 12 个 Claude 操作(2.4 倍),约 3200 词输出(5.3 倍)
而且这个差距在所有工作类型、所有任务价值区间内都成立——不是「因为专家做更复杂的任务」,而是「专长本身让 Claude 做得更多」。
更重要的结论:所有主要职业类别的用户在编码任务上的成功率与软件工程师基本相同。这意味着一个律师、会计、医生,只要他们对自己的领域有足够理解,就能让 Claude Code 达到接近专业程序员的产出质量。
Anthropic 的原文结论是:「AI 编程助手不是在取代领域专长——你对问题理解越深,AI 能产生的优质工作就越多。」
对 AI 创业者的三件事
- 不要招「会写代码的人」来用 AI 编程,要招「懂业务的人」。一个懂跨境电商选品逻辑的运营,用 AI Agent 构建自动化工具的效率可能远超一个只会写代码但不懂业务的工程师。
- 「我」值钱的部分是领域知识,不是代码能力。花时间深耕你的垂直领域,而不是学 Python 语法。
- 高级用户和中级用户的差距不大——你不需要成为「深度专家」,只要对领域有足够熟练的理解,效果已经接近顶级专家。
核心发现三:七个月内发生了什么变化
从 2025 年 10 月到 2026 年 4 月,Anthropic 观察到三个关键趋势:
- 调试时间占比减半:修 Bug 的时间大幅下降,说明模型本身在变强——能一次性写出更正确的代码,也能更快地自我修复。
- 端到端使用在增加:用户从「让 Claude 写代码片段」转向「让 Claude 完成从部署、运行、分析到生成文档的完整链条」。
- 任务价值上升约 25%:Anthropic 用自由职业平台上的同类任务报价作为对照基准,发现典型任务的价值在七个月里涨了约四分之一——人们在用 Claude 做越来越值钱的事。
解读:AI 编程 Agent 的进化不只是「写得更多」、「更快」,而是让用户能做更高层次的工作。修 Bug 在减少,战略型的建新功能、数据分析、运维编排在增加。这是 AI 创业者必须把握的趋势:不要用 Agent 做低级重复劳动,用它做高价值的端到端交付。
实操指南:3 步提升你的 AI Agent 使用层级
基于 Anthropic 的研究,这里有一套可以在本周内落地的工作流升级方案。
第一步:给 Claude 写「验收标准」而非「执行指令」
错误示范——微管理模式(新手级):
正确示范——目标模式(专家级):
差距在哪:第一个版本把 Claude 当成了代码补全工具——你还是在做「怎么做」的决策。第二个版本描述了意图和约束条件,把执行决策交给了 Claude。
第二步:用 «验证清单» 代替 «目测检查»
研究显示,专家用户会明确要求 Claude 验证结果——而新手往往只是「看了一下输出」。
这相当于你作为领域专家,给了 Claude 一份「什么叫做好了」的清单。研究显示这正是高效用户的标志行为之一。
▲ 七个月趋势:调试时间减半,端到端使用增加,任务价值上升25%
第三步:建立 «任务特定» 的专长视角
Anthropic 的分类器强调:专长是任务特定的。你在当前这个任务上的专长取决于:
- 你对要解决的问题理解有多深
- 你对预期行为能描述到多细
因此,每次开始一个新任务时:
- 先花 5 分钟写下问题的边界条件(什么算成功、什么算失败、什么情况下可以接受不完美的方案)
- 描述你已知的坑(「上次类似任务里,跨时区的时间处理出了两次 bug,请特别注意时区」)
- 如果领域你不够熟,先让 Claude 帮你梳理一遍问题空间(「我不确定这个需求的最佳实现方式,请先给我分析 3 种可能的方案和各自的 tradeoff」)
踩坑提醒:从数据分析中得出的 4 个常见错误
误区一:把 AI Agent 当成搜索引擎
研究中的一个典型低级用户行为模式:问一个模糊的问题,拿到回答后不做验证就接受。这种会话的成功率显著低于那些明确要求 Claude 写测试、跑命令验证结果、检查边界条件的用户。
正确做法:每一次让 Claude 干活,都附带验收条件。不要靠「看着差不多」来判断。
误区二:不会纠错
专家用户的另一个标志:他们更频繁地纠正 Claude 的输出——而且纠正错了。这说明他们不只是「信任 AI」,而是在与 AI 进行真正的协作对话。发现 Claude 理解偏了就立刻纠正方向,而不是「算了先听 AI 的」。
误区三:把「执行决策」也抓在手里
研究发现用户抓执行决策和不抓执行决策时,Claude 的动作量差异接近一倍(8 个 vs 16 个操作/prompt)。如果你连用哪个库、怎么写循环都要指定,你就是在把 $20/月的 Claude Pro 当成了贵价版的代码补全工具。
误区四:跨领域时低估自己的专长
这是最重要的误区。一个资深律师可能觉得自己「不会编程」所以不敢指挥 Claude 写代码——但实际上,如果她能跟 Claude 说清楚「这个合同审查脚本需要检查 6 种缺失条款,每一种的定义如下…」,她的效果会超过一个初级程序员。
不要因为你不会写代码就放弃指挥权。你只要会描述问题和约束条件。
总结
Anthropic 的这项研究给出了一个清晰的信号:AI 编程时代,代码能力不再是决定工作产出的上限,领域专长才是。
三个核心要点:
- 人会决定做什么(70% 的规划决策),AI 决定怎么做(80% 的执行决策)——接受这个分工,而不是试图微观管理
- 非程序员在编码任务上的成功率与程序员基本相同——前提是他们对自己的领域有足够理解
- 专家的标志不是「会写代码」,而是「会描述问题 + 会定义验收标准 + 会及时纠错」
行动建议:今天在下次使用 Claude Code 时,尝试把 prompt 从「怎么做」改为「做什么 + 验收条件」,看看产出质量的差异。这是从新手到专家最直接的跃迁路径。
研究来源:Anthropic 官方研究报告 "Agentic coding and persistent returns to expertise"(2026 年 6 月 16 日发布),基于约 40 万次会话、23.5 万用户的隐私保护分析。原始数据覆盖 2025 年 10 月至 2026 年 4 月。
本文由AI辅助创作,经人工审核编辑发布。 #Agent工坊 #ClaudeCode #AI编程 #一人公司 #AI创业
本文由AI辅助创作,经人工审核编辑发布